提出CRF框架,结合强化学习与大语言模型解决复杂知识图谱问答任务中的长期推理和幻觉问题,实验证明其有效性。
原文标题:论文浅尝 | 结合强化学习与大型语言模型的复杂问答协作推理框架(COLING2025)
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、CRF框架将KGQA任务分解为约束检测和路径推理两个层次,这种分层结构有什么优势?在其他复杂任务中,是否也可以借鉴这种分层解决问题的思路?
3、文章在实验部分使用了多个数据集,并且进行了消融实验和稳定性实验,这些实验设计有什么意义?你觉得还可以从哪些方面来评估CRF框架的性能?
原文内容


笔记整理:
卢宇晨,东南大学在读硕士,研究方向为基于知识图谱的API版本代码迁移
论文链接:
https://aclanthology.org/2025.coling-main.712/
发表会议:
COLING 2025
1. 动机
随着自然语言处理技术的发展,知识图谱问答(Knowledge Graph Question Answering,KGQA)任务取得了显著进展。然而,由于用户需求的复杂化、多样化,最近的研究已经试图构建能够回答复杂问题的KGQA系统,以更好地适应现实世界的场景。然而,复杂问题往往需要跨越多个知识图谱三元组进行推理,现有方法在面对此类问题时效果堪忧。例如强化学习(Reinforcement learning,RL),在处理长期推理问题时容易受到无目的探索的影响,导致学习效率低下;另一方面,大型语言模型(Large Language Model,LLM)在处理需要深入推理的复杂问题时容易产生幻觉,难以提供稳定可靠的答案。
为了解决这些挑战,本文提出了一个基于强化学习和大型语言模型的协作推理框架(Collaborative Reasoning Framework,CRF),旨在有效解决复杂 KGQA 问题。该框架利用大型语言模型的先验知识和推理能力,为强化学习提供更有效的探索和奖励信号,并通过强化学习避免大型语言模型的幻觉问题,提供可解释的推理链。该工作在多个基准数据集上取得了最先进的性能,验证了模型的有效性。
2. 贡献
(1)本文针对复杂 KGQA 问题,提出了一个基于强化学习和大型语言模型的协作推理框架(CRF),有效解决了现有方法在长期推理和幻觉问题上的局限性。
(2)本文将 KGQA 任务分解为约束检测(constrain detection)和路径推理两个层次。通过将LLM和RL策略相结合,多层次智能体(agent)可以解决复杂KGQA的无目的探索和LLM幻觉的挑战,实现了高效且可解释的推理过程。
(3)本文在多个基准数据集上进行了全面的实验,并通过消融研究验证了 CRF 框架中各个组件的有效性,证明了其在复杂 KGQA 任务上的优越性能。
3. 方法
本文提出了一种名为CRF的协作推理框架,旨在解决复杂知识图谱问答 (KGQA) 任务,CRF的总体架构由图一所示。该框架融合了大型语言模型和强化学习技术,通过分层决策过程模拟人类认知过程,有效解答复杂KGQA任务。框架主要包含高层和低层策略智能体(agent),分别负责约束检测和路径推理,并通过LLM提供奖励函数和行动引导,克服弱监督、奖励延迟和稀疏、无目的探索等问题,从而提升框架在复杂KGQA上的性能。
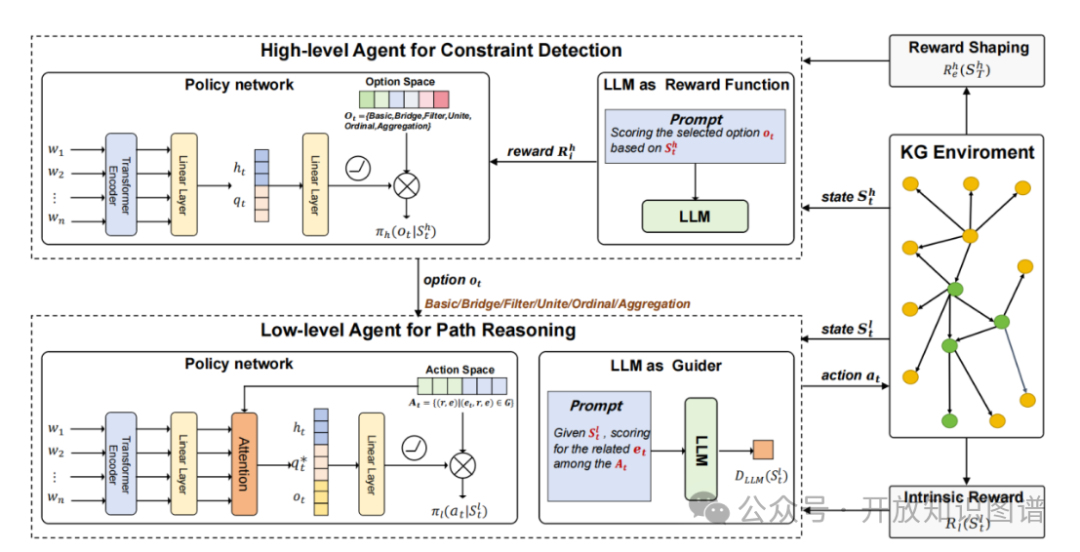
图1 CRF总体框架图
3.1 高层级约束检测
为了有效处理复杂问题,该模型引入了高层级约束检测策略,其核心功能是检测推理过程中遇到的约束类型,从而指导路径推理过程,确保推理方向正确。以下是该过程中几个关键概念的叙述。
约束状态与类型选项。模型将当前实体、问题、历史关系路径作为输入状态,并根据问题类型定义了六种不同的选项,分别对应不同的约束场景:Basic,用于逐步添加关系,生成推理路径,适用于大多数简单问题。例如,通过“isDirectedBy”关系连接“电影 Inception”和“Christopher Nolan”;Bridge,专门处理涉及多个主题实体的问题,通过连接不同路径,构建完整的推理链条。例如,通过“isInMovie”关系找到“Christopher Nolan”参演的电影“Interstellar”,再通过“isDirectedBy”关系找到“Christopher Nolan”;Union,适用于涉及多个关系的同一主题实体的问题,例如查询一个演员参演的所有电影;Filter,用于处理数值或时间比较,例如查询某位演员主演的票房收入超过 10 亿美元的电影;Ordinal,用于对当前实体集进行排序,并根据序号选择实体,例如查询某个电影票房排名前三的演员;Aggregation,对当前实体应用聚合函数,例如统计某个演员参演电影的类型数量。通过定义这些选项,模型能够有效地识别和应对不同的约束类型,从而更好地指导路径推理过程。
奖励设计。奖励分为外部奖励与内部奖励。外部奖励,是由于只有最终答案被标记,模型使用 KGE 模型的评分函数为候选实体计算软奖励,提供一种对推理结果的评估方式;内部奖励,是 LLM根据当前状态和上下文演示输出每个选项的概率,作为中间奖励,解决延迟和稀疏奖励的问题,加速模型收敛,使模型能够更快地学习到有效的推理策略。
策略网络。模型使用 Transformer 编码器获取问题表示,并结合 LSTM 编码历史关系路径,最终输出每个选项的概率分布,指导推理过程。Transformer 编码器能够捕捉问题的语义信息,而 LSTM 编码器则能够捕捉关系路径的序列信息,两者结合能够更全面地理解问题和路径,从而更准确地选择合适的选项,指导推理过程。
3.2 低层级路径推理
高层级策略检测一旦到预先定义的约束类型,便会引导低层级路径推理模块选择最有可能的关系,从而构建推理路径。为了使高层级检测到的约束类型在低层级推理过程中发挥作用,低层级模块会将高层级选项作为额外的输入,进而指导路径推理过程(见图1)。以下是该过程中几个关键概念的叙述。
状态定义。低层级状态与高层级状态类似,包括主题实体、问题、历史关系路径,以及高层级选项。高层级选项可以影响低层级策略的学习,使其能够更好地适应不同的约束场景。
动作选择。对于每种选项,低层级模块选择动作来选择最有可能的关系。动作空间是当前实体的出边集合。根据不同的选项,选择动作的策略也不同:Basic 会选择单跳关系,将其添加到历史关系路径中;Bridge, Union, Filter 则根据约束条件(例如实体、关系或数值约束)选择关系;Ordinal, Aggregation 由于低层级模块难以直接选择正确的动作,它将利用 LLM的辅助,直接进行正确的推理,这部分内容具体可见下文“LLM指导”。
奖励设计。低层级模块的奖励基于内在动机,通过测量所选关系与问题的语义相似度来计算。正确的决策包含一个涵盖问题部分语义信息的关系,因此语义相似度越高,奖励越大。
策略网络。低层级模块策略网络将低层级状态、关系感知的问题表示和选项嵌入作为输入,输出每个动作的概率分布,指导路径推理过程。
LLM指导。由于 RL 代理在处理需要长期推理的复杂查询时可能存在无效探索的问题,模型利用 LLM的常识先验和规划能力,以语言的形式为策略代理提供指导,提高低层级动作选择的效率。LLM通过评估每个候选动作与问题的相关性,输出一个概率分布,表示每个动作被选中的可能性。低层级策略网络与 LLM的概率分布结合,共同决定最终的行动选择,从而更好地利用 LLM的先验知识,避免无效探索,提高推理效率。。
3.3 CRF框架的优化与推理
CRF 模型的优化和推理过程充分利用了 LLM和 RL 的优势,有效地解决了复杂知识图谱问答中的长期推理、低质量奖励和幻觉等问题,实现了更高的准确率和鲁棒性。
优化。CRF 的优化过程采用 REINFORCE 算法,该算法属于策略梯度方法,通过梯度上升更新策略参数,使期望累积奖励最大化。具体步骤如下:轨迹生成,利用当前策略在所有问答对上生成大量轨迹,每个轨迹包含一系列状态、动作和奖励;梯度估计,计算轨迹上每个时间步的梯度,梯度大小取决于该时间步的奖励和策略在该状态和动作下的概率密度比;参数更新,利用梯度估计结果更新策略网络的参数,使策略倾向于选择那些能够带来更高奖励的动作。
推理。CRF 框架的推理过程模仿人类认知过程,结合LLM的先验知识和训练好的策略智能体的逻辑推理能力,共同完成复杂问题的回答。首先,LLM将根据当前状态、动作和问题信息,评估每个候选动作的相关性,并输出一个概率分布,表示每个动作被选中的可能性; 随后,策略智能体根据自身计算的概率分布和 LLM的概率分布,共同决定最终的行动选择。策略智能体的逻辑推理能力可以验证 LLM的评估结果,避免幻觉的发生。然后,策略代理根据选择的动作,逐步构建推理路径,直到找到答案实体或达到最大推理步数。最后,根据推理路径,生成最终的答案实体。
4. 实验
数据集设置。本文在四个公共数据集上测评了CRF方案的有效性。这四个数据集为WebQuestionSP (WebQSP)、 ComplexWebQuestions (CWQ) 、 PathQuestion (PQ) 和 MetaQA ,这些数据集涵盖了不同难度、不同领域和不同推理深度的问题,为 KGQA 研究提供了丰富的测试资源。WebQSP数据集包含 4373 个问题,所有问题的答案实体与主题实体之间最多相隔 2 个关系跳。它基于 Freebase 知识图谱构建,涵盖了各种类型的问题,是 KGQA 研究的常用基准数据集;CWQ 基于 WebQSP 构建,但问题更加复杂。它通过扩展问题实体或添加答案约束,构建了四种类型的复杂问题,需要最多 4 个关系跳才能找到答案。这个数据集对模型的推理能力提出了更高的要求;PQ 数据集来自通用领域,基于 Freebase 知识图谱的子集构建。它从知识图谱中提取两个实体之间的路径,并使用一些规则生成更真实的问题。PQ 数据集包括 2 跳、3 跳和混合跳的问题,可以评估模型在不同推理深度下的表现;MetaQA 数据集专注于电影领域,包含超过 400,000 个问题。它根据关系跳的数量分为 1 跳、2 跳和 3 跳三个子集,可以评估模型在不同领域和推理深度下的泛化能力。
表1 实验数据集的统计数据
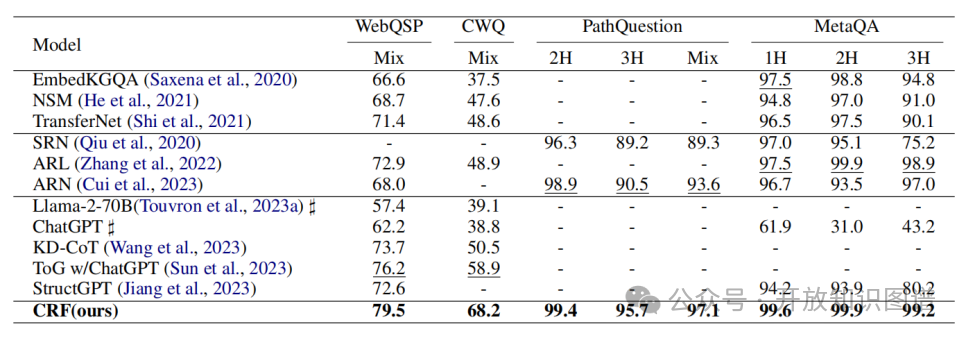
对比实验。本文为证明自身CRF框架的优越性,将自身效果与基于信息检索的方法、基于强化学习的方法以及基于LLM的方法在上述四个数据集上进行性能对比,由表2可知,CRF取得了最好的成绩。
表2在四个公开数据集上的Hit@1结果。最好的分数用粗体表示,第二好的分数用下划线表示。“-”表示在原始论文中没有报道任何结果。使用♯的结果转载自(Sun等人,2023年)
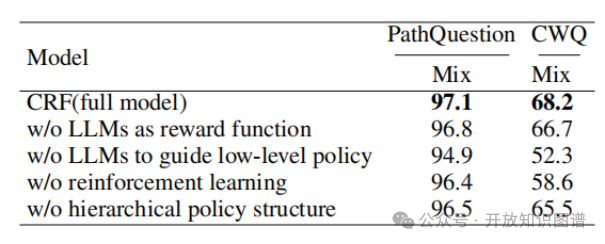
消融实验。本文消融实验设置了取消LLM作为奖励函数、取消LLM作为低层次模块的策略引导、取消强化学习策略、取消层次结构,在PQ和CWQ数据集上评测其性能。这些消融实验结果表明,LLM、强化学习和分层策略结构都是 CRF 模型中不可或缺的组件,它们共同作用,才能使模型在复杂 KGQA 任务上取得最佳性能(见表3)。
表3 PQ和CWQ数据集上的消融研究结果(Hit@1)。最佳结果被标记为粗体
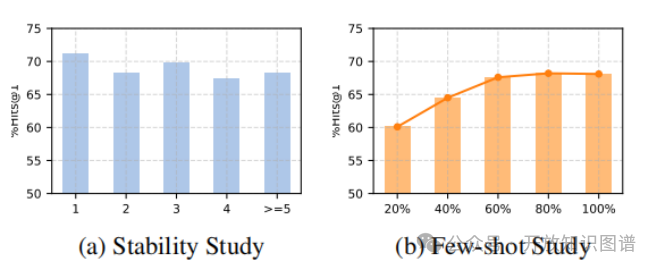
稳定性实验,研究了模型在不同复杂度问题上的表现。表4(a)表明,CRF 模型在问题复杂度增加的情况下仍能保持稳定的性能,说明其具有良好的鲁棒性和泛化能力。
少样本学习实验,研究了模型在不同比例的训练数据上的表现。表4(b)表明,CRF 模型即使使用少量训练数据也能取得良好的性能,说明其具有少样本学习能力。
表4 (a)在具有不同复杂性的CWQ上的性能。(b)不同比例CWQ训练数据的表现
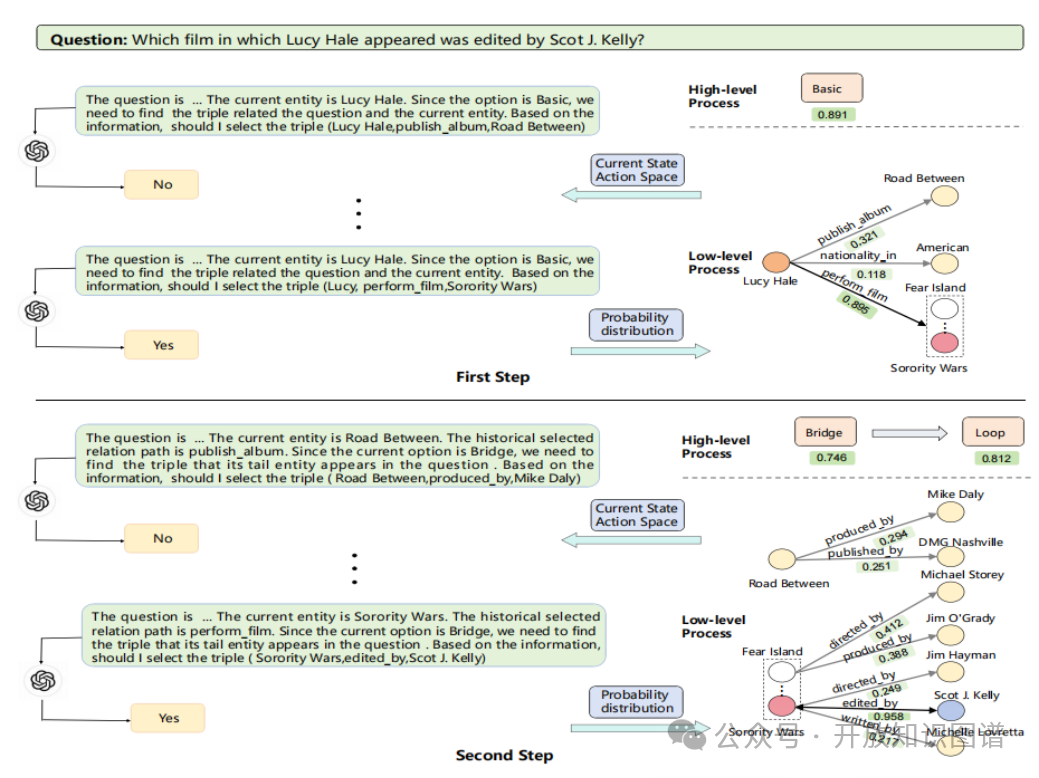
案例分析。该案例展示了CRF 模型如何通过分层决策和 LLM/RL 协同推理,有效地解决复杂 KGQA 任务。高层代理负责识别约束条件,低层代理负责路径推理,LLM 则提供常识先验和规划能力,RL 代理则提供逻辑推理能力,共同完成推理过程(表5)。
表5 一个层次化决策过程案例
5. 总结
本文提出了一个基于分层强化学习和大型语言模型的协同推理框架(CRF),旨在解决复杂知识图谱问答(KGQA)任务。 该框架借鉴了人类的认知过程,将 LLM 的常识先验和 RL 的环境学习能力相结合,构建了一个分层代理来处理复杂问题。高层代理负责识别推理过程中遇到的约束条件,而低层代理则负责选择 KG 中最有希望的关系进行路径推理。通过将 KGQA 任务分解为约束检测和路径推理两个层次,CRF 模型有效地解决了 LLM 推理中的幻觉问题和 RL 探索中的盲目性问题。实验结果表明,CRF 模型在多个基准数据集上取得了最先进的性能,证明了其在复杂 KGQA 任务中的有效性。

