提出一种端到端变分方法,自动学习编码连续语音属性,增强语义标记表达能力,提升生成式口语语言模型的自然度。
原文标题:【ICML2025】用于提升生成式口语语言模型自然度的变分框架
原文作者:数据派THU
冷月清谈:
本文介绍了一种端到端的变分方法,旨在提升生成式口语语言模型的自然度。该方法通过自动学习编码连续的语音属性来增强语义标记的表达能力,无需人工提取和选择副语言特征。传统方法常采用离散化的语义标记进行语音建模,但忽略了语音中的韵律信息,导致生成语音的自然度较低。虽然添加音高特征有所改善,但其表达能力有限且依赖人工设计。该变分框架能够有效捕捉语音中的连续属性,从而生成更自然的语音延续。实验结果表明,该方法在语音自然度方面表现更优。
怜星夜思:
1、除了音高,你觉得还有哪些语音属性对口语的自然度影响比较大?这些属性又该如何量化并融入到模型中?
2、文章提到使用变分方法进行语音属性的编码,你认为这种方法相比于其他方法(如自编码器、GAN)的优势是什么?又有哪些潜在的局限性?
3、文章中提到模型在语义标记上训练,生成的语音自然度较低,那么是否可以通过改进语义标记的方式来提升语音自然度?如果是,你有什么想法?
2、文章提到使用变分方法进行语音属性的编码,你认为这种方法相比于其他方法(如自编码器、GAN)的优势是什么?又有哪些潜在的局限性?
3、文章中提到模型在语义标记上训练,生成的语音自然度较低,那么是否可以通过改进语义标记的方式来提升语音自然度?如果是,你有什么想法?
原文内容

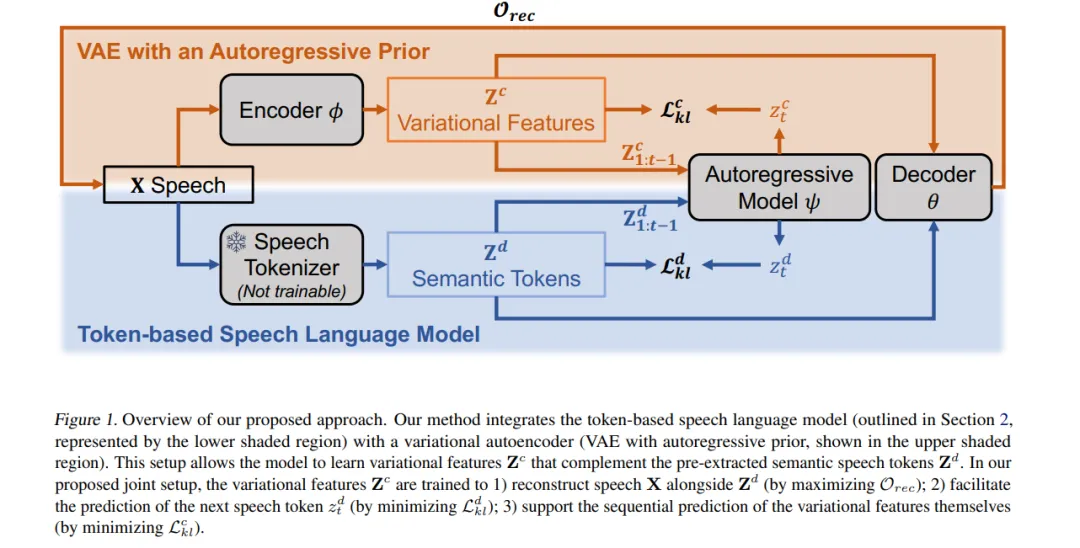
来源:专知本文约1000字,建议阅读5分钟我们提出了一种端到端的变分方法,能够自动学习编码这些连续的语音属性,从而增强语义标记的表达能力。

大型语言模型在文本处理上的成功激发了其在语音建模中的应用。然而,由于语音是连续且复杂的,通常需要离散化以便进行自回归建模。由自监督模型提取的语音标记(称为语义标记)通常聚焦于语音的语言层面,但忽略了韵律信息。因此,在这些标记上训练得到的模型往往生成出自然度较低的语音。已有方法试图通过向语义标记中添加音高特征来弥补这一问题,但音高本身无法完整表达各种副语言属性,且选取合适的特征通常依赖精细的人工设计。
为了解决这一问题,我们提出了一种端到端的变分方法,能够自动学习编码这些连续的语音属性,从而增强语义标记的表达能力。我们的方法无需人工提取与选择副语言特征。此外,根据人类评价者的反馈,该方法生成的语音延续在自然性上更受偏好。代码、样本与模型可在以下地址获取:https://github.com/b04901014/vae-gslm。