提出VRF-DETR,一种Transformer架构,解决无人机图像小目标检测难题。引入自适应感受野和门控卷积,在精度和效率间取得平衡,超越现有算法。
原文标题:2025年小目标检测新突破!
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到了门控卷积(GConv)模块,它通过抑制不重要的空间响应来保留关键局部模式。除了GConv,还有哪些技术或者方法可以实现类似的功能,提高模型对关键信息的关注度?
3、VRF-DETR在VisDrone数据集上表现出色,但VisDrone主要集中在城市环境。如果将该模型应用到更复杂的场景,例如山区、森林等,可能面临哪些挑战?应该如何改进?
原文内容

来源:学姐带你玩AI本文约1500字,建议阅读5分钟本文提出了一种基于Transformer的无人机图像检测框架VRF-DETR,旨在解决无人机(UAV)检测任务中的小目标检测、密集遮挡和计算资源限制等问题。
论文题目:An Efficient Aerial Image Detection with Variable Receptive Fields
论文地址:https://arxiv.org/pdf/2504.15165
代码地址:https://github. com/LiuWenbin-CV/VRF-DETR.

创新点
-
引入自适应接收场选择机制,通过深度空洞卷积生成不同接收场的特征图,再利用空间注意力建立通道间关系,最后通过门控元素乘积实现自适应增强。
-
将门控机制引入卷积操作中,通过深度可分离卷积降低参数量,同时利用门控机制动态抑制不重要的空间响应,保留关键局部模式。
-
改进了RT-DETR中的C2f模块,采用级联结构,依次通过MSCF建立区域间关联、批量归一化和dropout层正则化特征、GConv进行空间自适应精炼,两侧的快捷连接保证梯度稳定流动,中间的dropout层防止特征共适配。
方法
本文提出了一种基于Transformer的无人机图像检测框架VRF-DETR,旨在解决无人机(UAV)检测任务中的小目标检测、密集遮挡和计算资源限制等问题。该框架通过三个关键组件实现:多尺度上下文融合(MSCF)模块,通过动态调整特征贡献解决固定尺度注意力的局限性,利用深度空洞卷积生成不同接收场的特征图,结合空间注意力和门控元素乘积实现自适应增强,提高对不同尺度目标的适应性;门控卷积(GConv)模块,将门控机制引入卷积操作,利用深度可分离卷积降低参数量,同时动态抑制不重要的空间响应以保留关键局部模式,提高局部特征建模能力;
VRF-DETR 的整体架构
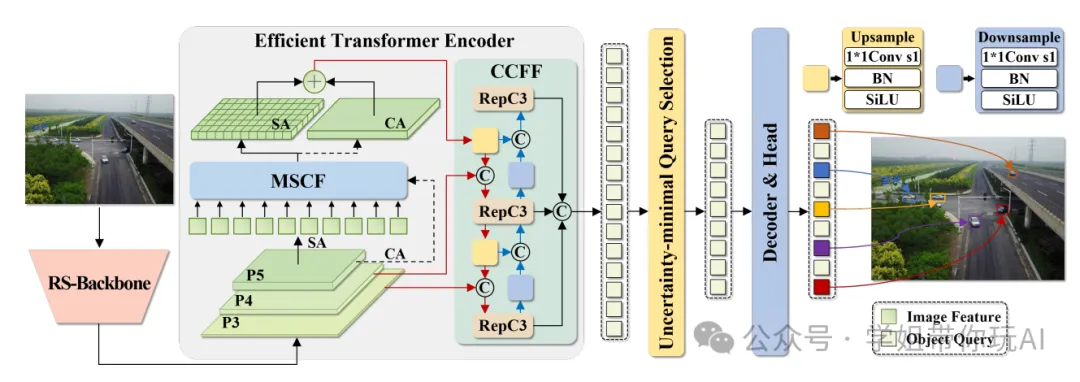
本图展示了 VRF-DETR 的主体结构,包括远程遥感骨干网(RS-Backbone,其包含 GMCF 瓶颈用于特征学习)、多尺度融合编码器(集成了自适应空间注意力的 MSCF)以及网络中广泛分布的轻量级 GConv 操作符。这些模块共同构成了 VRF-DETR 实现航空检测中准确性和效率平衡的基础架构。
MSCF 模块的架构
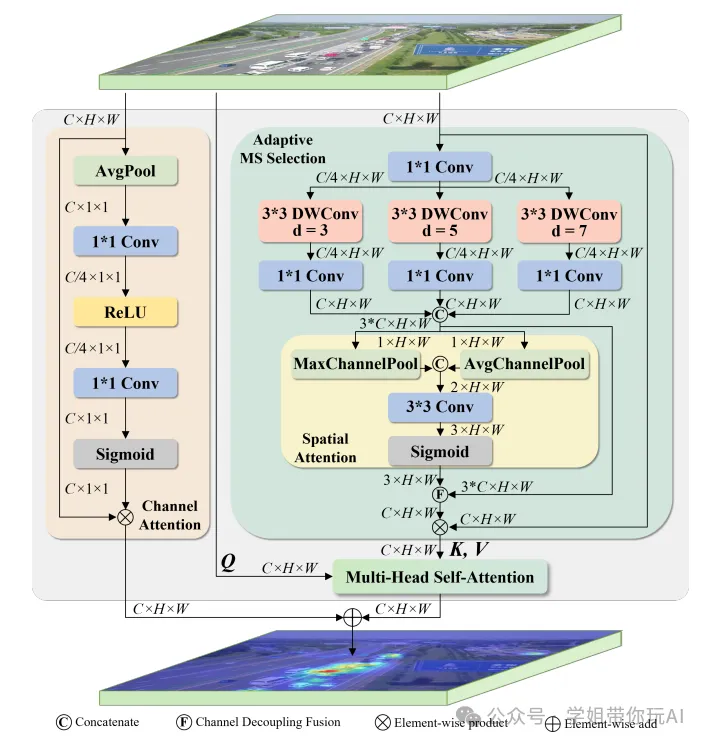
本图展示了 MSCF 模块的详细结构,包括其重新组织的双分支结构,通过深度空洞卷积生成不同接收场的特征图,随后进行特征连接、空间选择和加权融合等操作,最终实现自适应接收场选择机制,为后续对不同尺度目标的检测提供动态调整特征贡献的能力。
GConv 模块的架构
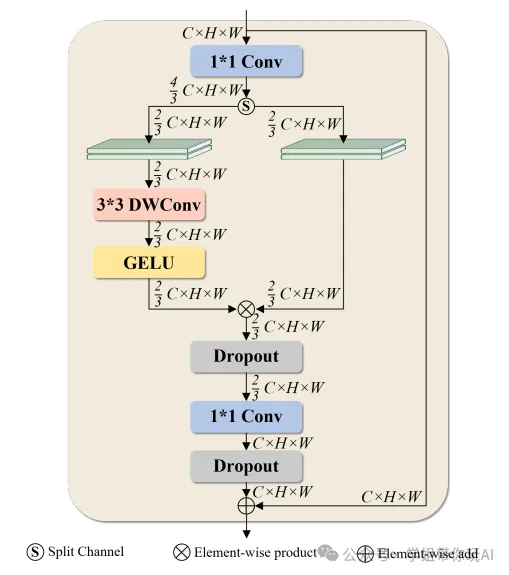
本图呈现了 GConv 模块的三个关键部分:逐点卷积投影层、基于深度卷积的特征处理器(带有门控机制)以及残差连接。输入张量经过 1×1 卷积扩展通道后分为两部分,其中一部分经过深度可分离卷积和激活函数处理,再与门控张量进行逐元素乘法以实现动态特征重校准,最后通过 1×1 卷积恢复通道数并添加原始输入,实现高效的空间上下文建模。
实验结果
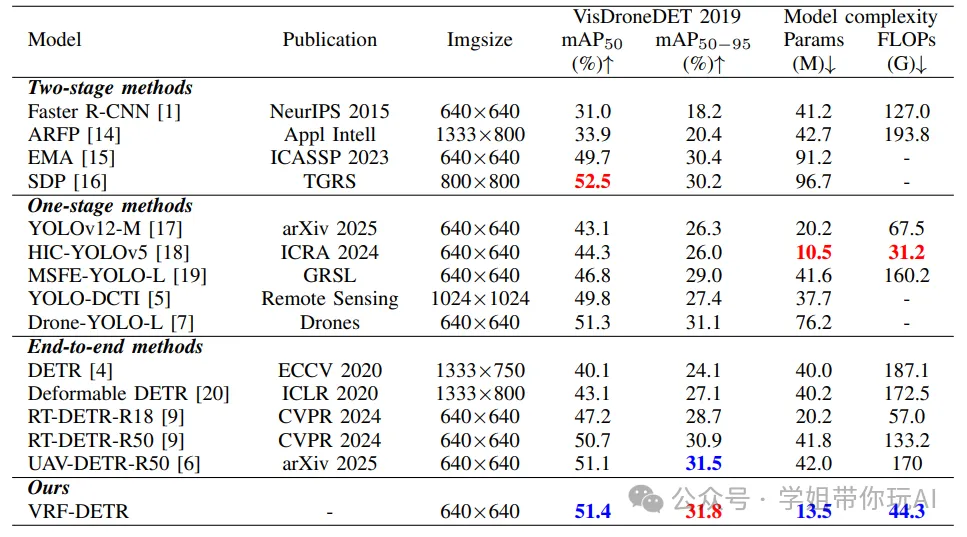
本表展示了VRF-DETR与多种先进目标检测方法在VisDrone-2019-DET验证数据集上的性能对比,包含两阶段、单阶段和端到端三类方法。VRF-DETR在模型复杂度(参数量13.5M、浮点运算44.3G)和检测性能(mAP50为51.4%、mAP50-95为31.8%)上均取得了优异平衡,超越了多种现有方法,如在与RT-DETR-R50对比中,VRF-DETR在保持更低参数量和浮点运算的同时,mAP50高出0.6%,mAP50-95高出0.3%。这表明VRF-DETR能有效应对无人机检测中的小目标、密集遮挡等问题,在资源受限设备上也有良好表现。
编辑:文婧
