Meta再次出手,挖走OpenAI四位华人学者,或为提升模型微调和多模态对齐能力。Llama 5 会有哪些新突破?
原文标题:刚刚,OpenAI四位华人学者集体被挖,还是Meta重金出手
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 Meta 在模型微调和多模态对齐方面比较薄弱,那么模型微调和多模态对齐具体是指什么?为什么它们在大模型中如此重要?
3、文章中提到了 GPT-4o mini 等轻量化模型,这些轻量化模型有什么优势?在哪些场景下会更有用武之地?
原文内容
编辑:杜伟、大盘鸡
再一次,Meta「搜刮」了 OpenAI 的成员。The Information 发布了文章,谈到 Meta 再聘四名 OpenAI 研究人员。这离上一次 只隔了短短几天时间。

在 4 月发布 Llama 4 AI 模型后,Meta 启动了一波大规模招聘潮。据悉,Llama 4 的表现并未达到 CEO Mark Zuckerberg 的预期,而 Meta 也因其在热门基准测试中所使用的 Llama 版本而受到外界批评。
与此同时,Meta 与 OpenAI 之间也爆发了一轮口水战。OpenAI CEO Sam Altman 声称,Meta 正向人才开出「1 亿美元的签约奖金」,但他补充说,「到目前为止,我们最顶尖的人才」都未被挖走。
对此,Meta CTO Andrew Bosworth 则向员工表示,虽然部分高管确实收到了类似金额的报价,但实际的报价条款远比单纯的一次性签约奖金要复杂得多。换句话说,这不是一次性的即时现金。
上一次被挖走的三位小伙伴都参与了 ViT 等重要研究。这次被挖走的小伙伴也是参与了不少 OpenAI 的重要工作。
他们分别是:
-
Jiahui Yu:领导了 o3、o4-mini 和 GPT-4.1 的研发
-
Hongyu Ren:o3-mini 和 o1-mini 的创建者,o1 的核心贡献者
-
Shuchao Bi:OpenAI 后训练多模态组织负责人
-
Shengjia Zhao:GPT-4 和 o1 的关键贡献者

这些研究员是 OpenAI 模型从 GPT-4 到 GPT-4o,以及轻量化模型(如 o1-mini、o3-mini)研发的中坚力量。暂不知这会不会造成 OpenAI 人才短期断档,对 GPT-5 的到来产生影响。吸收这些人员之后,Meta 在大模型技术栈中最弱的一环 —— 模型微调和多模态对齐 能得到质的飞跃吗?我们可以一起观察一下。

网友对 Llama 5 的有趣猜想
接下来,我们来简单了解下这几位研究者的履历:
Shengjia Zhao
根据领英简历,Shengjia Zhao 在 2022 年 6 月加入 OpenAI。
他本科毕业于清华大学,博士毕业于斯坦福大学(计算机科学),曾获得过 。

加入 OpenAI 之后,Shengjia Zhao 参与了重要大模型的训练,包括 GPT-4、GPT-4o 和 o1。
Jiahui Yu(余家辉)
余家辉在 2023 年 10 月加入 OpenAI,现任 Perception team(感知团队)负责人。在此之前,他曾是谷歌 DeepMind Gemini 项目多模态的负责人。
他本科毕业于中国科学技术大学少年班计算机科学专业,并在伊利诺伊大学厄巴纳 - 香槟分校获得博士学位,师从 Thomas Huang 教授。他的研究领域包括深度学习和高性能计算。

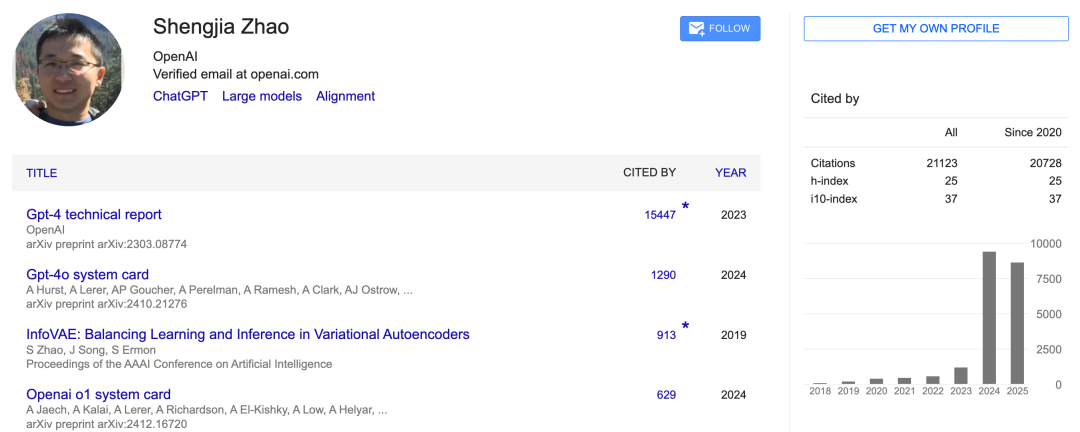
从他的精选项目中,我们可以看到,他作为研究负责人、顾问先后参与了 OpenAI 的「Thinking with Images」、o3 和 o4-mini、GPT-4.1、GPT-4o 及图像生成等重要工作。

Shuchao Bi
Shuchao Bi 在 2024 年 5 月加入 OpenAI,现任后训练 - 多模态(Post-training-Multimodal)负责人。此前,他曾担任谷歌的技术主管(Tech Lead Manager)、YouTube 的工程总监。
他本科毕业于浙江大学,硕博毕业于加州大学伯克利分校。
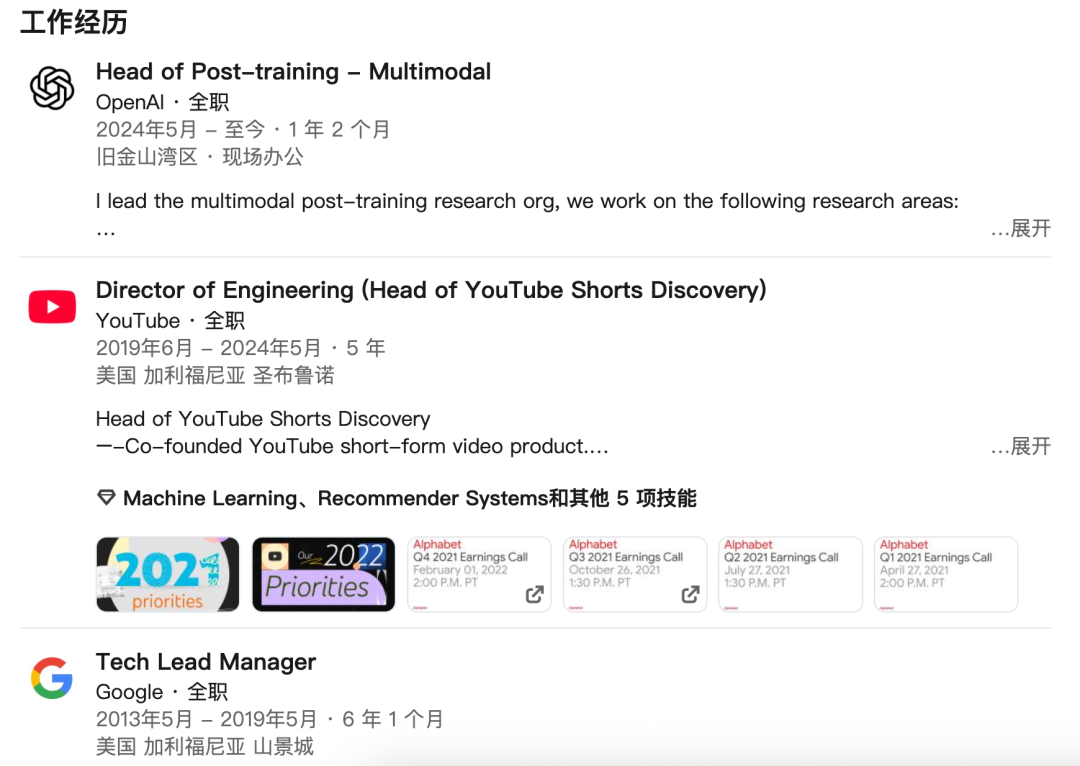
在 OpenAI 期间,他的核心研究方向包括:预训练新范式、多模态推理与高阶计算强化学习、多模态评分模型与评估体系、智能体系统整合、多模态 - 多语言认知协同、具身智能基础模型、多模态蒸馏技术等等。

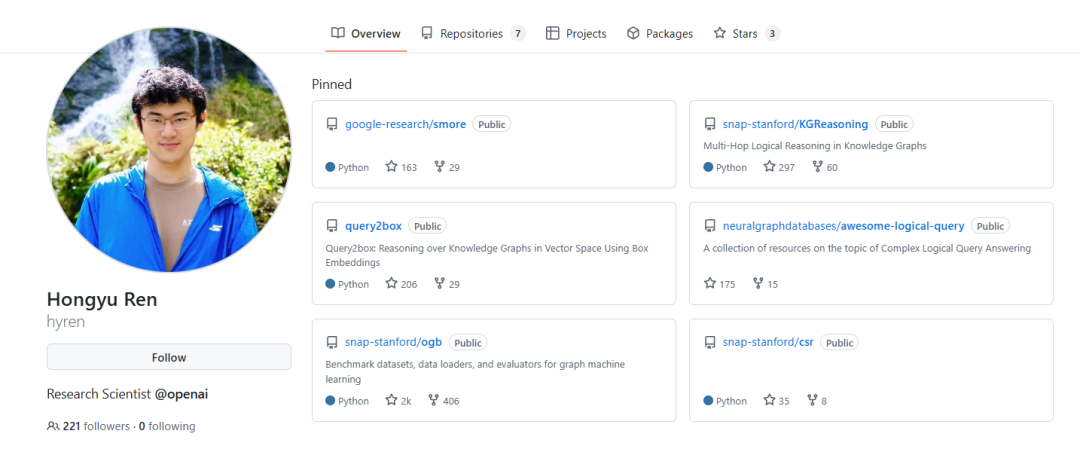
Hongyu Ren(任泓宇)
Hongyu Ren 现为 OpenAI 研究科学家。他在 2023 年 7 月加入了 OpenAI,此前曾在苹果、谷歌等公司工作过。
他拥有斯坦福大学计算机科学博士学位和北京大学计算机科学荣誉学士学位。

在 OpenAI 期间,他参与创建了 o3-mini、o1-mini,并是 o1 的基础贡献者;此外,他还是 GPT-4o mini 的负责人以及 GPT-4o 的核心贡献者;他还领导了一支后训练团队。
参考链接:
https://www.theinformation.com/articles/meta-hires-four-openai-researchers
https://techcrunch.com/2025/06/28/meta-reportedly-hires-four-more-researchers-from-openai/
https://x.com/Yuchenj_UW/status/1939035068909105289

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com