新研究 SeqPO-SiMT 框架通过序贯策略优化,显著提升同声传译质量并控制延迟,在低延迟下翻译质量超越现有模型,甚至媲美离线翻译。
原文标题:ACL 2025 | AI字幕慢半拍,不知道大家在笑什么?新方法让同传性能直逼离线翻译
原文作者:机器之心
冷月清谈:
怜星夜思:
2、SeqPO-SiMT 框架提到用大语言模型(LLM)做策略模型,那么选择不同的 LLM 会对结果有什么影响?未来是否可以针对同传任务定制 LLM?
3、SeqPO-SiMT 框架在实验中已经能媲美甚至超越一些离线翻译模型,那么它在实际应用中还面临哪些挑战?
原文内容

本文第一作者是徐婷,是香港中文大学博士生,主要研究兴趣是大模型的后训练;通讯作者分别是黄志超和程善伯,来自字节跳动Seed团队。
你是否经历过这样的场景:观看一场激动人心的全球发布会,AI 字幕却总是慢半拍,等你看到翻译,台上的梗已经冷掉了。
或者,在跨国视频会议上,机器翻译的质量时好时坏,前言不搭后语,让人啼笑皆非。
这就是同声传译(Simultaneous Machine Translation, SiMT)领域一直以来的核心技术挑战:“质量 - 延迟” 权衡问题(Quality-Latency Trade-off)。
现在,这些问题迎来了新的解决方案。来自香港中文大学、字节跳动 Seed 和斯坦福大学的研究团队联手提出了一种面向同声传译的序贯策略优化框架 (Sequential Policy Optimization for Simultaneous Machine Translation, SeqPO-SiMT)。
该方法将同传任务巧妙地建模为序贯决策过程,通过优化完整的决策序列,显著提升了翻译质量,同时有效控制了延迟,其性能直逼、甚至在某些方面超越了同等大小的离线翻译模型。

-
论文标题: SeqPO-SiMT: Sequential Policy Optimization for Simultaneous Machine Translation
-
论文链接:https://arxiv.org/pdf/2505.20622
研究背景
同声传译的核心在于机器需要动态地决定 “继续听”(READ)还是 “开始说”(WRITE)。这个决策直接影响最终的翻译效果。例如,当模型接收到英文单词 “bark” 时,它面临一个困境:如果立即翻译,可能会译为 “狗叫”,但若后文出现 “of the tree”,则正确翻译应为 “树皮”。
传统的同传方法,它每一步决策(是继续听,还是开始翻译)都是孤立的。它可能会因为眼前的 “小利”(比如翻译出一个词)而牺牲掉全局的 “大利”(整个句子的流畅度和准确性)。
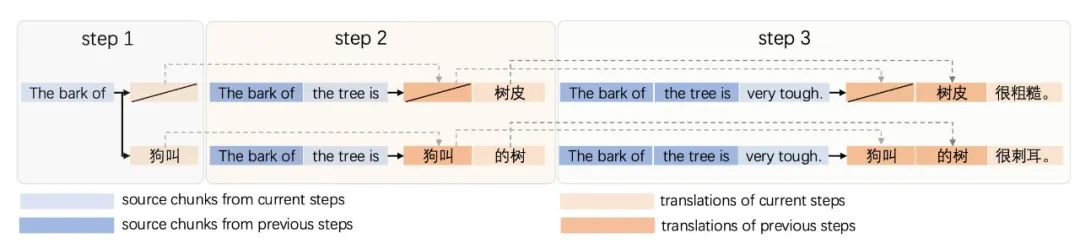
核心方法
针对这一难点,该论文提出了 SeqPO-SiMT 框架。其核心思想是将同声传译任务建模为一个序贯决策问题,综合评估整个翻译流程的翻译质量和延迟,并对整个决策序贯进行端到端的优化。
该方法的主要特点是:它不再孤立地评估每一步决策的好坏,而是将一整句话的翻译过程(即一个完整的决策序贯)视为一个整体,更符合人类对同传的评估过程。
同声传译采样阶段:使用一个大语言模型(LLM)充当策略模型 ![]() 。在每个时间步 t,模型会接收新的源语言文本块
。在每个时间步 t,模型会接收新的源语言文本块 ![]() ,并基于已有的所有源文本
,并基于已有的所有源文本 ![]() 和之前的翻译历史
和之前的翻译历史 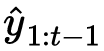 ,来生成当前的翻译块
,来生成当前的翻译块 ![]() 。这个决策过程可以被形式化地表示为:
。这个决策过程可以被形式化地表示为: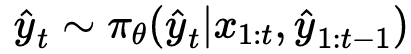 。该框架的一个关键灵活性在于,如果模型决定等待更多上下文,输出的
。该框架的一个关键灵活性在于,如果模型决定等待更多上下文,输出的 ![]() 可以为空,其长度完全由策略模型
可以为空,其长度完全由策略模型 ![]() 自行决定。
自行决定。
奖励函数:在优化阶段,对于一个 batch 内的第 i 个样本,系统会通过一个在最终步骤 T 给予的融合奖励 ![]() 来评估整个过程的优劣。这个奖励同时评估翻译质量(Quality)和延迟(Latency)。具体而言,首先计算出原始的质量分
来评估整个过程的优劣。这个奖励同时评估翻译质量(Quality)和延迟(Latency)。具体而言,首先计算出原始的质量分 ![]() 和延迟分
和延迟分 ![]() ,然后对两者进行归一化处理以统一量纲得到
,然后对两者进行归一化处理以统一量纲得到 ![]() 和
和 ![]() ,最终的奖励被定义为:
,最终的奖励被定义为:
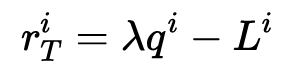
其中,λ 是一个超参数,用于权衡质量与延迟的重要性。
优化目标:模型的最终优化目标最大化期望奖励 ![]() ,同时为了保证训练的稳定性,目标函数中还引入了 KL 散度作为约束项,防止策略模型
,同时为了保证训练的稳定性,目标函数中还引入了 KL 散度作为约束项,防止策略模型 ![]() 与参考模型
与参考模型![]() 偏离过远。这个结合了最终奖励和稳定性约束的优化过程,使得模型能够端到端地学会一个兼顾翻译质量与延迟的最优策略:
偏离过远。这个结合了最终奖励和稳定性约束的优化过程,使得模型能够端到端地学会一个兼顾翻译质量与延迟的最优策略:
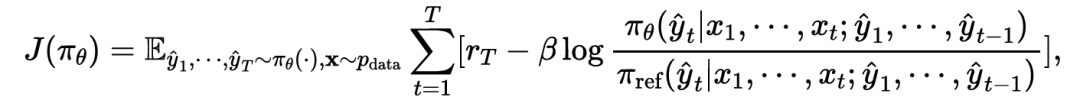
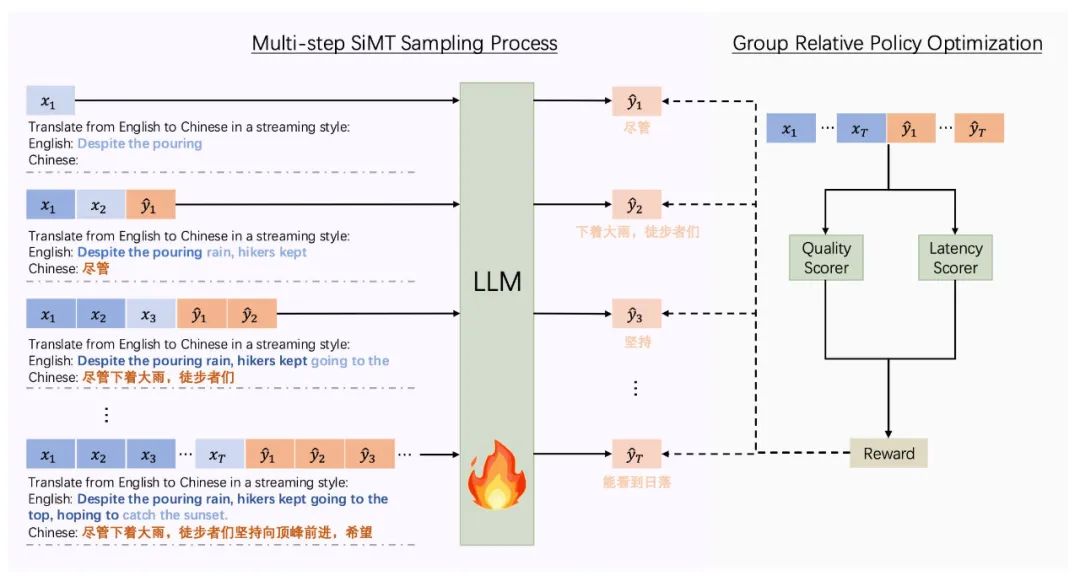

实验结果与分析
为了验证方法的有效性,研究者们在多个公开的英汉互译测试集上进行了实验,并与多种现有的同传模型进行了对比。实验结果显示:在低延迟水平下,SeqPO-SiMT 框架生成的译文质量相较于基线模型有明显提升。

本文将 SeqPO-SiMT 的实时同传结果与多个高性能模型的离线翻译结果进行对比。结果显示,SeqPO-SiMT 的翻译质量不仅优于监督微调(SFT)的离线模型及 LLaMA-3-8B,其表现甚至能媲美乃至超越 Qwen-2.5-7B 的离线翻译水平。这表明该方法在 70 亿参数(7B)规模上实现了业界顶尖(SoTA)的性能。
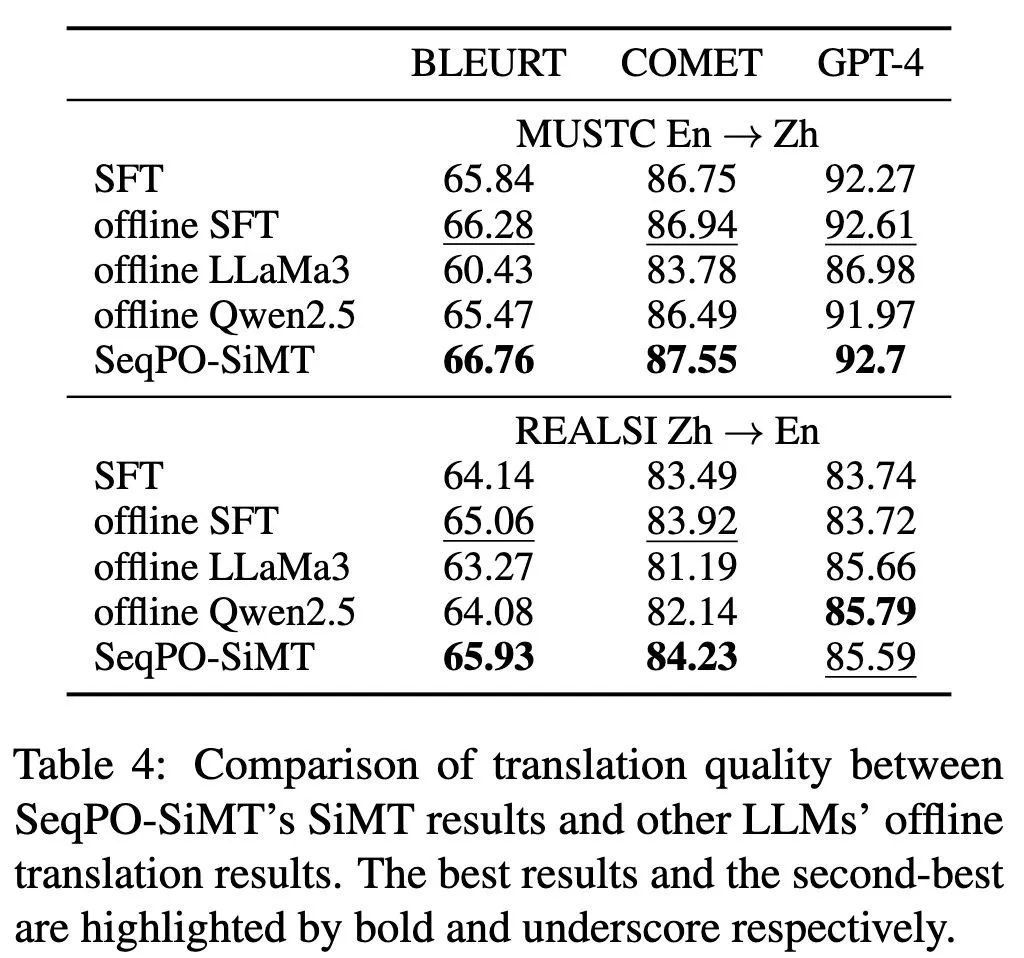
总结与讨论
总的来说,SeqPO-SiMT 这项工作的主要贡献在于,为解决同声传译中的质量 - 延迟权衡问题提供了一个新的视角。它强调了对决策 “序贯” 进行整体优化的重要性。该研究提出的方法,对于需要进行实时、连续决策的自然语言处理任务具有一定的参考意义,并为未来开发更高效、更智能的同声传译系统提供了有价值的探索。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]