Sapient Intelligence提出的分层推理模型HRM,以小参数实现了复杂推理任务上的卓越性能,或将变革大模型架构。
原文标题:只用2700万参数,这个推理模型超越了DeepSeek和Claude
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到HRM通过可视化展现了其解决迷宫、数独和ARC任务的推理过程,那么这种可视化方法对于我们理解AI的决策过程有什么帮助?我们还能通过哪些方式来进一步提升AI模型的可解释性?
3、文章中提到HRM在小数据集上表现出色,并且不需要CoT数据,这对于资源有限的研究者来说是个好消息。你认为这种小样本学习的优势未来是否会成为一种趋势?它可能会如何影响AI研究和应用的方向?
原文内容
编辑:泽南、陈陈
像人一样推理。
大模型的架构,到了需要变革的时候?
在对复杂任务的推理工作上,当前的大语言模型(LLM)主要采用思维链(CoT)技术,但这些技术存在任务分解复杂、数据需求大以及高延迟等问题。
近日,受到人脑分层和多时间尺度处理机制启发,来自 Sapient Intelligence 的研究者提出了分层推理模型(HRM),这是一种全新循环架构,能够在保持训练稳定性和效率的同时,实现高计算深度。
具体来说,HRM 通过两个相互依赖的循环模块,在单次前向传递中执行顺序推理任务,而无需对中间过程进行明确的监督:其中一个高级模块负责缓慢、抽象的规划,另一个低级模块负责处理快速、细致的计算。HRM 仅包含 2700 万个参数,仅使用 1000 个训练样本,便在复杂的推理任务上取得了卓越的性能。
该模型无需预训练或 CoT 数据即可运行,但在包括复杂数独谜题和大型迷宫中最优路径查找在内的挑战性任务上却取得了近乎完美的性能。此外,在抽象与推理语料库 (ARC) 上,HRM 的表现优于上下文窗口明显更长的大型模型。ARC 是衡量通用人工智能能力的关键基准。
由此观之,HRM 具有推动通用计算变革性进步的潜力。

-
论文:Hierarchical Reasoning Model
-
论文链接:https://arxiv.org/abs/2506.21734
如下图所示:左图 ——HRM 的灵感源自大脑的层级处理和时间分离机制。它包含两个在不同时间尺度上运行的循环网络,用于协同解决任务。右图 —— 仅使用约 1000 个训练样本,HRM(约 2700 万个参数)在归纳基准测试(ARC-AGI)和具有挑战性的符号树搜索谜题(Sudoku-Extreme、Maze-Hard)上就超越了最先进的 CoT 模型,而 CoT 模型则完全失败。HRM 采用随机初始化,无需思维链,直接根据输入完成任务。

分层推理模型
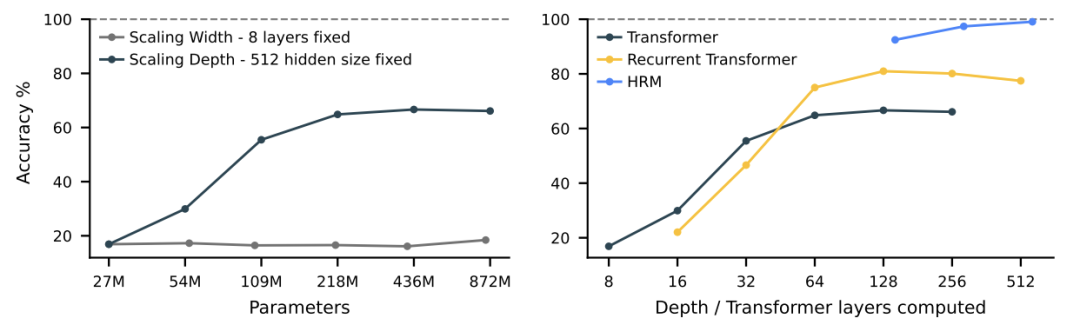
复杂推理中深度的必要性如下图所示。
左图:在需要大量树搜索和回溯的 Sudoku-Extreme Full 上,增加 Transformer 的宽度不会带来性能提升,而增加深度则至关重要。右图:标准架构已饱和,无法从增加深度中获益。HRM 克服了这一根本限制,有效地利用其计算深度实现了近乎完美的准确率。
HRM 核心设计灵感来源于大脑:分层结构 + 多时间尺度处理。 具体包括:
分层处理机制:大脑通过皮层区域的多级层次结构处理信息。高级脑区(如前额叶)在更长的时间尺度上整合信息并形成抽象表示,而低级脑区(如感觉皮层)则负责处理即时、具体的感知运动信息。
时间尺度分离:这些层次结构的神经活动具有不同的内在时间节律,体现为特定的神经振荡模式。这种时间分离机制使得高级脑区能稳定地指导低级脑区的快速计算过程。
循环连接特性:大脑具有密集的循环神经网络连接。这种反馈回路通过迭代优化实现表示精确度的提升和上下文适应性增强,但需要额外的处理时间。值得注意的是,这种机制能有效规避反向传播时间算法(BPTT)中存在的深层信用分配难题。
HRM 模型由四个可学习的组件组成:输入网络 f_I (・; θ_I ),低级循环模块 f_L (・; θ_L) ,高级循环模块 f_H (・; θ_H) 和输出网络 f_O (・; θ_O) 。
HRM 将输入向量 x 映射到输出预测向量 y´。首先,输入 x 被网络投影成一个表示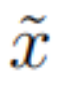 :
:
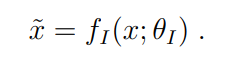
模块在一个周期结束时的最终状态为:
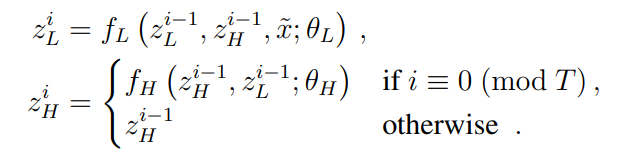
最后,在经过 N 个完整周期后,从 H 模块的隐藏状态中提取预测 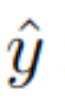 。
。
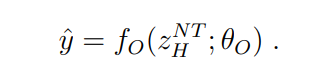
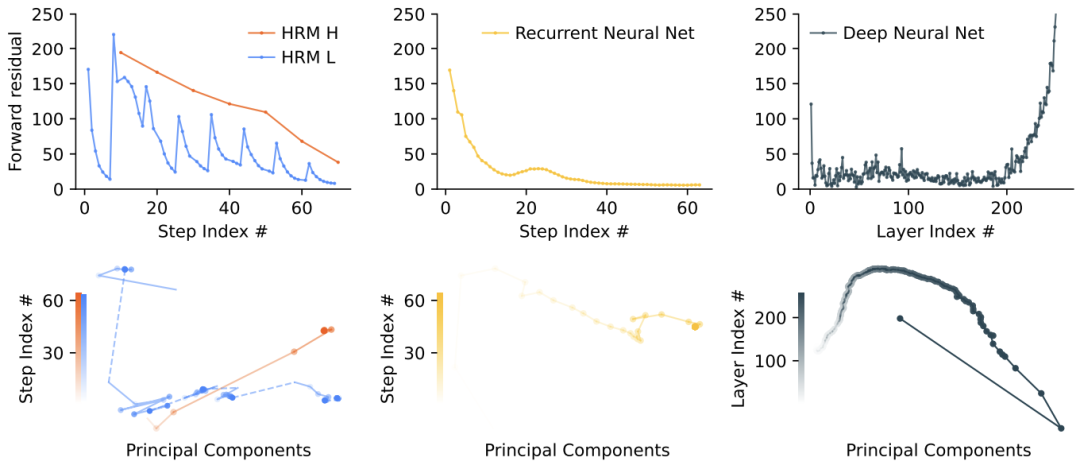
HRM 表现出层级收敛性:H 模块稳定收敛,而 L 模块在周期内反复收敛,然后被 H 重置,导致残差出现峰值。循环神经网络表现出快速收敛,残差迅速趋近于零。相比之下,深度神经网络则经历了梯度消失,显著的残差主要出现在初始层(输入层)和最终层。
HRM 引入了:
首先是近似梯度。循环模型通常依赖 BPTT 计算梯度。然而,BPTT 需要存储前向传播过程中的所有隐藏状态,并在反向传播时将其与梯度结合,这导致内存消耗与时间步长 T 呈线性关系(O (T))。
HRM 设计了一种一步梯度近似法,核心思想是: 使用每个模块最后状态的梯度,并将其他状态视为常数。
上述方法需要 O (1) 内存,不需要随时间展开,并且可以使用 PyTorch 等自动求导框架轻松实现,如图 4 所示。

其次是深度监督,本文将深度监督机制融入 HRM。
给定一个数据样本 (x, y),然后对 HRM 模型进行多次前向传递,每次传递称为一个段。令 M 表示终止前执行的段总数。对于每个段 m ∈ {1, ..., M},令![]() 表示段 m 结束时的隐藏状态,包含高级状态分量和低级状态分量。图 4 展示了深度监督训练的伪代码。
表示段 m 结束时的隐藏状态,包含高级状态分量和低级状态分量。图 4 展示了深度监督训练的伪代码。
自适应计算时间(ACT)。大脑在自动化思维(System 1)与审慎推理(System 2)之间动态切换。
受上述机制的启发,本文将自适应停止策略融入 HRM,以实现快思考,慢思考。
图 5 展示了两种 HRM 变体的性能比较。结果表明,ACT 能够根据任务复杂性有效地调整其计算资源,从而显著节省计算资源,同时最大程度地降低对性能的影响。
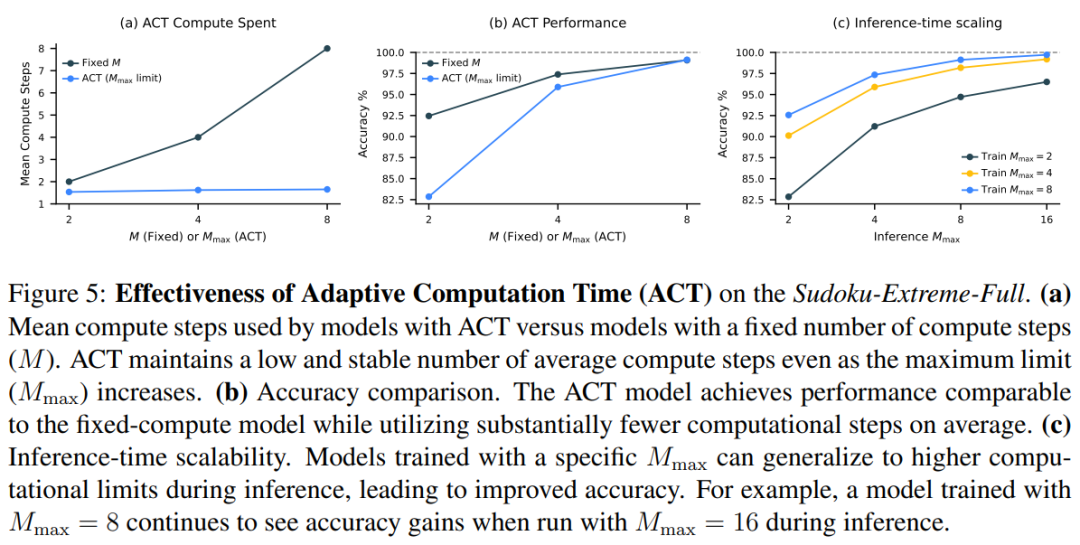
推理时间扩展。有效的神经模型应当能够在推理阶段动态利用额外计算资源来提升性能。如图 5-(c) 所示,HRM 模型仅需增加计算限制参数 Mmax,即可无缝实现推理计算扩展,而无需重新训练或调整模型架构。
实验及结果
该研究中,作者跑了 ARC-AGI、数独和迷宫基准测试,结果如图 1 所示:
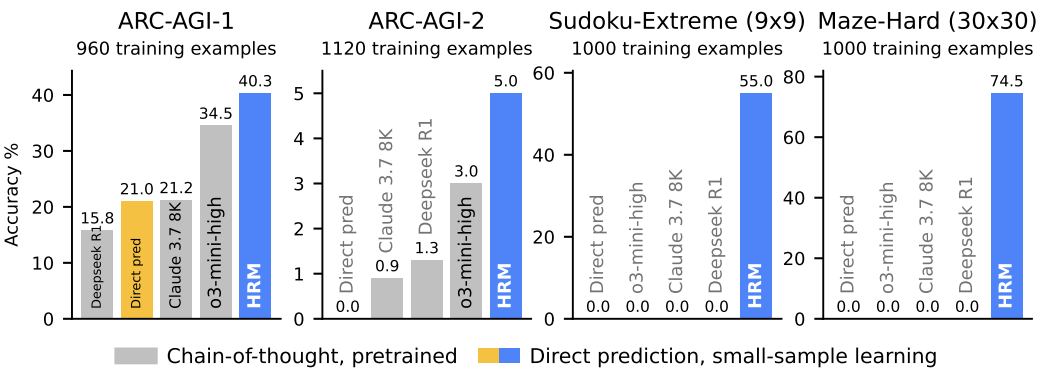
HRM 在复杂的推理任务上表现出色,但它引出了一个耐人寻味的问题:HRM 神经网络究竟实现了哪些底层推理算法?解答这个问题对于增强模型的可解释性以及加深对 HRM 解决方案空间的理解至关重要。
作者尝试对 HRM 的推理过程进行可视化。在迷宫任务中,HRM 似乎最初会同时探索多条潜在路径,随后排除阻塞或低效的路径,构建初步解决方案大纲,并进行多次优化迭代;在数独任务中,该策略类似于深度优先搜索方法,模型会探索潜在解决方案,并在遇到死胡同时回溯;HRM 对 ARC 任务采用了不同的方法,会对棋盘进行渐进式调整,并不断迭代改进,直至找到解决方案。与需要频繁回溯的数独不同,ARC 的解题路径遵循更一致的渐进式,类似于爬山优化。
更重要的是,该模型可以适应不同的推理方法,并可能为每个特定任务选择有效的策略。不过作者也表示,我们还需要进一步研究以更全面地了解这些解题策略。
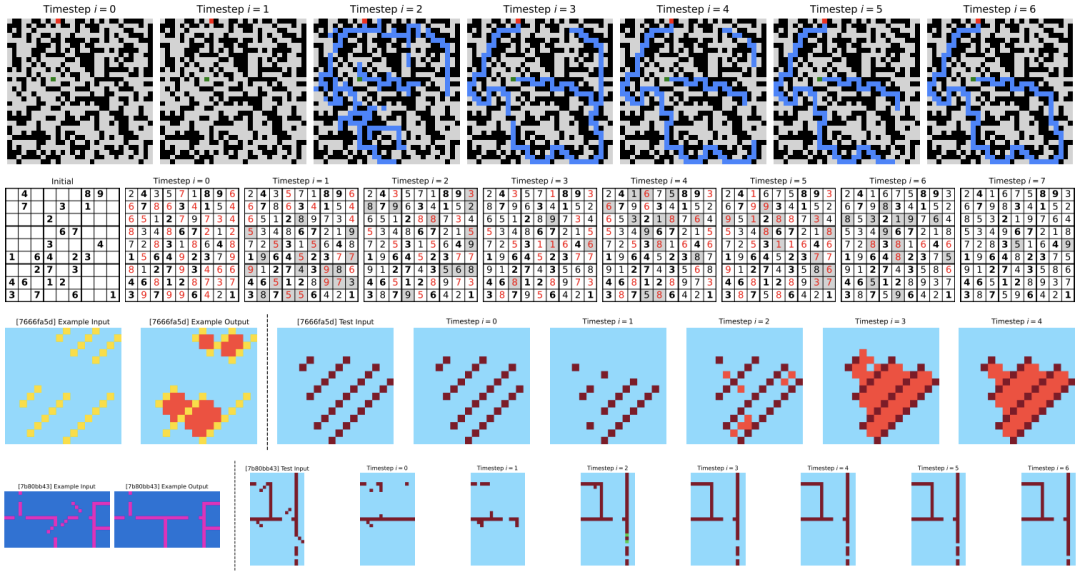
HRM 在基准任务中对中间预测结果的可视化。上图:MazeHard—— 蓝色单元格表示预测路径。中图:Sudoku-Extreme—— 粗体单元格表示初始给定值;红色突出显示违反数独约束的单元格;灰色阴影表示与上一时间步的变化。下图:ARC-AGI-2 任务 —— 左图:提供的示例输入输出对;右图:求解测试输入的中间步骤。
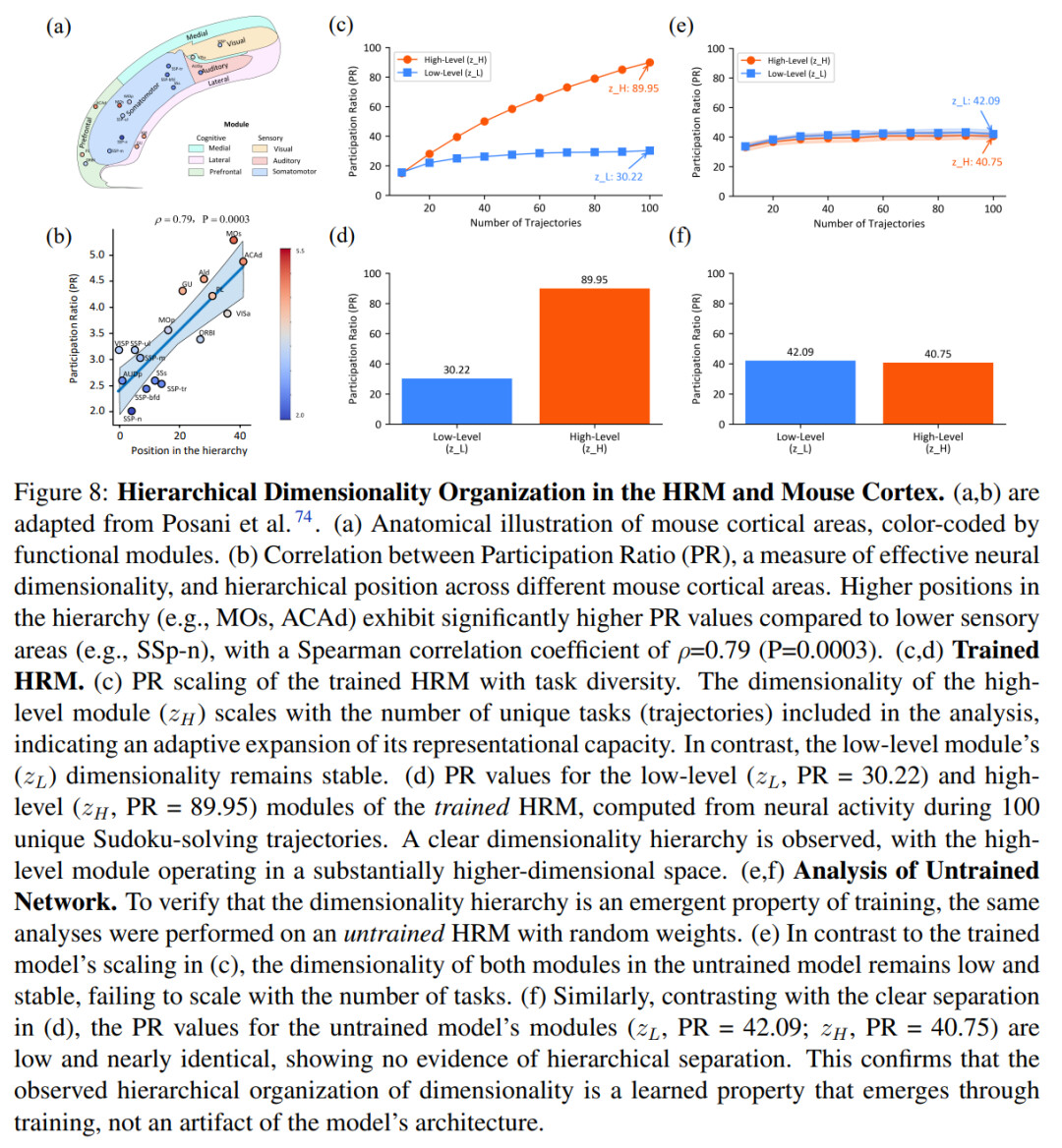
下图为 HRM 模型与小鼠皮层的层级维度组织结构对比。
例如,在小鼠皮层中可以观察到维度层次,其中群体活动的 PR( Participation Ratio )从低水平感觉区域到高水平关联区域单调增加,支持维度和功能复杂性之间的这种联系(图 8 a,b)。
图 8-(e,f) 所示的结果显示出明显对比:未经过训练的模型中,高层模块与低层模块没有表现出任何层级分化,它们的 PR 值都较低,且几乎没有差异。
这一对照实验表明,维度层级结构是一种随着模型学习复杂推理任务而自然涌现的特性,并非模型架构本身固有的属性。
作者在进一步讨论中表示,HRM 的图灵完备性与早期的神经推理算法(包括 Universal Transformer)类似,在给定足够的内存和时间约束的情况下,HRM 具有计算通用性。
换句话说,它克服了标准 Transformer 的计算限制,属于可以模拟任何图灵机的模型类别。再加上具有自适应计算能力,HRM 可以在长推理过程中进行训练,解决需要密集深度优先搜索和回溯的复杂难题,并更接近实用的图灵完备性。
除了 CoT 微调之外,强化学习(RL)是最近另一种被广泛采用的训练方法。然而,最近的证据表明,强化学习主要是为了解锁现有的类似 CoT 能力,而非探索全新的推理机制 。此外,使用强化学习进行 CoT 训练以其不稳定性和数据效率低而闻名,通常需要大量的探索和精心的奖励设计。相比之下,HRM 从基于梯度的密集监督中获取反馈,而不是依赖于稀疏的奖励信号。此外,HRM 在连续空间中自然运行,这在生物学上是合理的,避免了为每个 token 分配相同的计算资源进而导致的低效。
更多内容,请参阅原论文。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]