伯克利&Meta提出PEVA模型,通过AI学习身体动作与视觉信息之间的关系,构建更贴近现实的具身智能。
原文标题:伯克利&Meta面向具身智能的世界模型:让AI通过全身动作「看见」未来
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到PEVA可以进行“反事实”推断,即预测如果做另一个动作会看到什么。这种能力在实际应用中有哪些潜在价值?
3、PEVA目前还存在一些局限,例如无法用语言描述目标。你认为未来如何让AI能够像人一样,将语言指令融入到具身智能的世界模型中?
原文内容

本文基于 Yutong Bai、Danny Tran、Amir Bar、Yann LeCun、Trevor Darrell 和 Jitendra Malik 等人的研究工作。

-
论文标题:Whole-Body Conditioned Egocentric Video Prediction
-
论文地址:https://arxiv.org/pdf/2506.21552
-
项目地址:https://dannytran123.github.io/PEVA/
-
参考阅读链接:https://x.com/YutongBAI1002/status/1938442251866411281
几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题:
如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?
在很多早期研究中,世界模型就是一个预测引擎:只要给它一个抽象的控制指令,比如「向前走一米」或者「向左转 30 度」,它就能模拟出未来的图像。这类方式在实验室环境里已经发挥过很大作用,但一旦放到真正复杂的人类生活环境,就常常捉襟见肘。
毕竟,人并不是一个漂浮在空中的摄像头。人有四肢、有关节、有骨骼,也有着非常具体的物理限制:
-
关节的活动范围
-
躯干的稳定性和平衡
-
肌肉力量的极限
这些物理约束决定了:并不是所有动作都能被执行,很多计划只能在可达、可平衡、可承受的范围内完成。而正是这样的物理性,才塑造了人类真实的动作方式,也塑造了我们能够看到的和不能看到的信息。
举一些例子:
-
你想看到身后的情况,就必须转头或者转身
-
你想看清桌下的东西,就必须弯腰蹲下
-
你想拿到高处的杯子,就必须抬起手臂并伸展身体
这些都不是凭空的,而是被身体结构和运动学约束的行为。所以如果 AI 也要像人一样预测未来,就得学会:预测自己的身体能做到什么动作,以及由此产生的视觉后果。
为什么说视觉就是规划的一部分?
从心理学、神经科学到行为学,人们早就发现一个规律:在执行动作之前,人会先预演接下来会看到什么。
例如:
-
走向水杯时,脑子里会提前预测水杯什么时候出现
-
转过一个拐角前,会猜测即将出现的景象
-
伸手的时候,会想象手臂何时进入视野
这种「预演」能力让人类能及时修正动作并避免失误。也就是说,我们并不是光靠看到的画面做出决策,而是一直在用大脑里的「想象」,预测动作的结果。
如果未来的 AI 想在真实环境中做到和人一样自然地计划,就需要拥有同样的预测机制:「我如果这样动,接下来会看到什么?」
世界模型的老思路和新思路
世界模型并不新鲜,从 1943 年 Craik 提出「小规模大脑模型」的概念开始,到 Kalman 滤波器、LQR 等控制理论的出现,再到近年用深度学习做视觉预测,大家都在试图回答:「我采取一个动作,未来会怎样?」
但是这些方法往往只考虑了低维度的控制:像「前进」、「转向」这类参数。相比人类的全身动作,它们显得非常简陋。因为人类的动作:
-
有几十个自由度的关节
-
有清晰的分层控制结构
-
动作对视觉的结果会随着环境不断改变
如果一个世界模型不能考虑身体动作如何塑造视觉信息,它很难在现实世界里生存下来。
PEVA 的小尝试
基于这样的背景,来自加州大学伯克利分校、Meta的研究者们提出了一个看起来简单但非常自然的问题:「如果我真的做了一个完整的人体动作,那接下来从我的眼睛会看到什么?」
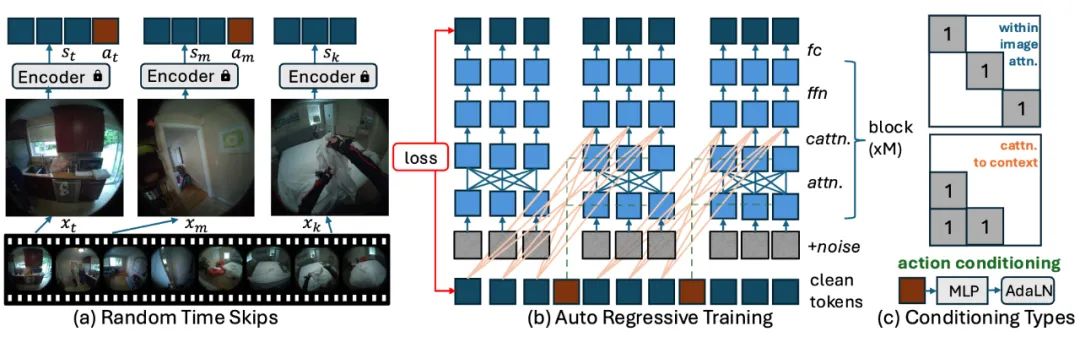
相比传统模型只用「速度 + 方向」做预测,PEVA 把整个人的 3D 姿态(包括关节位置和旋转)一并喂进模型,和历史的视频帧一起输入,从而让 AI 学会:身体的动作,会如何重新组织我们能看到的世界。

举一些例子:
-
手臂抬起 → 遮挡部分物体,同时也可能露出新的区域
-
蹲下 → 视角高度变化,地面特征出现
-
转头 → 原本背后的信息重新进入可见范围
这就是 PEVA 的核心:预测未来,不只是预测像素,而是预测身体驱动下的视觉后果。

PEVA 的功能
PEVA 目前能做的事情包括:
-
给定未来的 3D 全身动作,预测连续的第一视角视频。
-
分解复杂行为成「原子动作」,例如只控制左手或者头部旋转。

不仅做单次预测,还能生成最长 16 秒的视觉流。
支持「反事实」推断:如果做另一个动作,会看到什么?
在多条动作序列之间做规划,通过视觉相似度挑出更优方案。
在多样化的日常环境中学习,避免过拟合在简单场景。
一句话总结,PEVA 就像一个「身体驱动的可视化模拟器」,让 AI 获得更接近人类的想象方式。
技术细节
PEVA 的技术很简单直接,主要包括:
-
全身动作输入(48 维度的三维姿态)
-
条件扩散模型 + Transformer,兼顾视觉生成和时间逻辑
-
在真实同步的视频 + 动作(Nymeria 数据集)上训练
-
用时间跳跃策略预测到 16 秒
-
做一个可行的多方案规划:在若干个动作轨迹中,用视觉相似度挑一个最可能达成目标的方案。
研究者在文章中也用大篇幅讨论了局限和展望:例如只做了单臂或部分身体的规划,目标意图还比较粗糙,没法像人那样用语言描述目标,这些都值得后续慢慢补齐。
能力小结
从评估看,PEVA 在几个方面算是一个可行的探索:
-
短期视觉预测,与动作对齐度高。
-
长期可达 16 秒的视频,仍保持较好连贯性。
-
原子动作的控制能力,比如只预测手部动作、只预测转身。
-
规划:尝试多动作模拟,挑选最接近目标的一条。
这些能力至少证明了一个方向:用身体驱动未来的视觉预测,是走向具身智能的一种合理切入点。
展望
后续还值得探索的方向包括:
-
语言目标和多模态输入
-
真实交互中的闭环控制
-
对更复杂任务的可解释规划
当 AI 试着像人一样行动时,也许它同样需要先学会:如果我这么动,接下来会看到什么。
结语
或许可以这样说:「人类之所以能看见未来,是因为身体在动,视觉随之更新。」
PEVA 只是一个很小的尝试,但希望为未来可解释、可信任的具身智能,提供一点点启发。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com