清华&NVIDIA 提出 DDO,一种无需额外网络的视觉生成模型优化范式,通过 GAN 式优化目标,突破传统最大似然估计的性能瓶颈,显著提升图像生成质量。
原文标题:ICML 2025 Spotlight | 清华朱军组&NVIDIA提出DDO:扩散/自回归模型训练新范式,刷新图像生成SOTA
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到 DDO 可以和 CFG 等引导方法叠加使用,进一步提升性能,这背后的原理是什么?不同的引导方法之间是如何相互作用的?
3、DDO 方法在视觉生成领域取得了显著成果,你认为它在其他领域,例如自然语言处理、语音合成等方面,是否有应用前景?如果应用,可能面临哪些挑战?
原文内容

文章一作郑凯文为清华大学三年级博士生,研究方向为深度生成模型,曾提出流式扩散模型最大似然估计改进技术 i-DODE,扩散模型高效采样器 DPM-Solver-v3,扩散桥模型采样器 DBIM 以及掩码式离散扩散模型采样器 FHS 等。
清华大学朱军教授团队与 NVIDIA Deep Imagination 研究组联合提出一种全新的视觉生成模型优化范式 —— 直接判别优化(DDO)。该方法将基于似然的生成模型(如扩散模型、自回归模型)隐式参数化为 GAN,从而设计出一种无需额外网络、训练高效的微调方法,并大幅突破传统最大似然训练的性能瓶颈。

-
论文标题:Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a GAN Discriminator
-
论文链接: https://arxiv.org/abs/2503.01103
-
代码仓库: https://github.com/NVlabs/DDO
背景 | 基于似然的生成模型
近年来,扩散模型(Diffusion Models)和自回归模型(Autoregressive Models)在图像生成中占据主导地位,如 NVIDIA 的 EDM 系列扩散模型和字节跳动以 VAR 为代表的视觉自回归模型。相比 GAN(Generative Adversarial Networks)这类直接优化数据生成过程的隐式生成模型,扩散模型和自回归模型均属于基于似然的生成模型(Likelihood-Based Generative Model),它们显式估计数据的对数似然(log-likelihood),具有训练稳定、样本多样性强、容易规模化的特点。
然而,这类模型广泛采用的最大似然估计(Maximum Likelihood Estimation, MLE)训练损失对应的是正向 KL 散度,会导致「mode covering」问题:模型倾向于覆盖所有数据模式而非聚焦主要分布,并且会在低估数据集中任何样本的似然时遭受严厉惩罚,从而使生成结果模糊或失真,在模型容量不足时限制了生成质量。例如,i-DODE 作为专注于似然的模型,虽然在密度估计任务上达到了最先进水平,但在 FID 等视觉质量指标下表现不佳。现有视觉生成模型也往往依赖引导(guidance)方法,如无需分类器的引导(Classifier-Free Guidance, CFG),来抑制低质量生成样本。
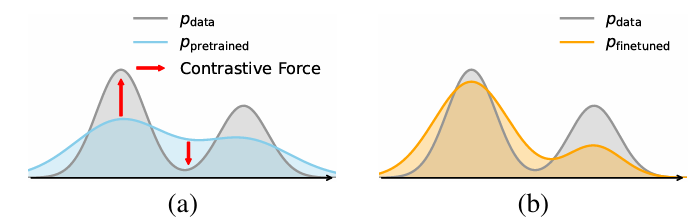
方法 | 把生成模型当判别器用,直接优化
为解决 MLE 的局限性,文章考虑使用 GAN 式判别的思想,在训练目标中引入反向 KL 散度的成分,强化模型在真实数据附近的密度,同时抑制错误区域,将模型分布由图(a):强调密度覆盖,微调为图(b):强调密度集中,从而提高生成保真度与有限模型容量下的生成质量。然而,直接使用 GAN 损失会引入额外的判别器网络与工程优化上的复杂性,尤其对于扩散/自回归模型这类需要迭代式多步生成的模型。
DDO 首次提出:你训练的似然生成模型,其实已经是一个「隐式判别器」。
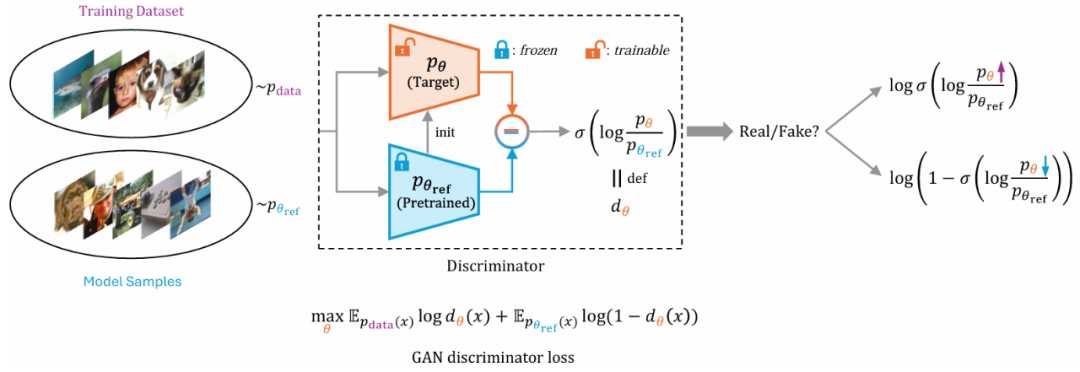
具体来说,DDO 引入待微调的目标模型和一个冻结的参考模型(均初始化为预训练模型),使用两个模型的对数似然比构造「隐式判别器」,得到可直接应用于扩散模型和自回归模型的 GAN 式优化目标:
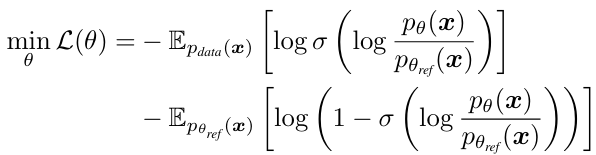
其中为模型对数似然,对于自回归模型由于因果掩码的存在可以通过单次网络前传准确计算,而对于扩散模型则需要结合 Jensen 不等式与证据下界(ELBO)近似估计。使用此训练目标微调时,真实数据来自原数据集,而假数据来自参考模型![]() 的自采样过程。根据 GAN 判别损失的性质,可以证明此目标下的最优模型分布
的自采样过程。根据 GAN 判别损失的性质,可以证明此目标下的最优模型分布![]() 恰为真实数据分布。
恰为真实数据分布。
在实际训练时,可通过多轮自对弈(self-play)进一步提升性能,做法是将下一轮的参考模型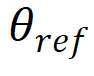 设置为上一轮表现最优的模型。
设置为上一轮表现最优的模型。
DDO 为扩散模型和自回归模型提供了即插即用的新训练目标,其微调后的模型和原模型具有完全相同的网络结构和采样方式,而在生成质量上大大增强。
实验 | 无需引导,刷新多项 SOTA
DDO 在多个标准图像生成任务中显著提升已有模型的生成质量,并刷新现有 SOTA。
-
ImageNet 512×512 无引导 FID 1.96 → 1.26。
-
ImageNet 64×64 无引导 FID 1.58 → 0.97。
-
CIFAR-10 无引导 FID 1.85 → 1.30。

ImageNet 512x512 生成结果。左:原模型 右:DDO 微调后的模型
肉眼观察发现生成图像的细节和真实度得到显著提升,同时多样性没有受到负面影响。
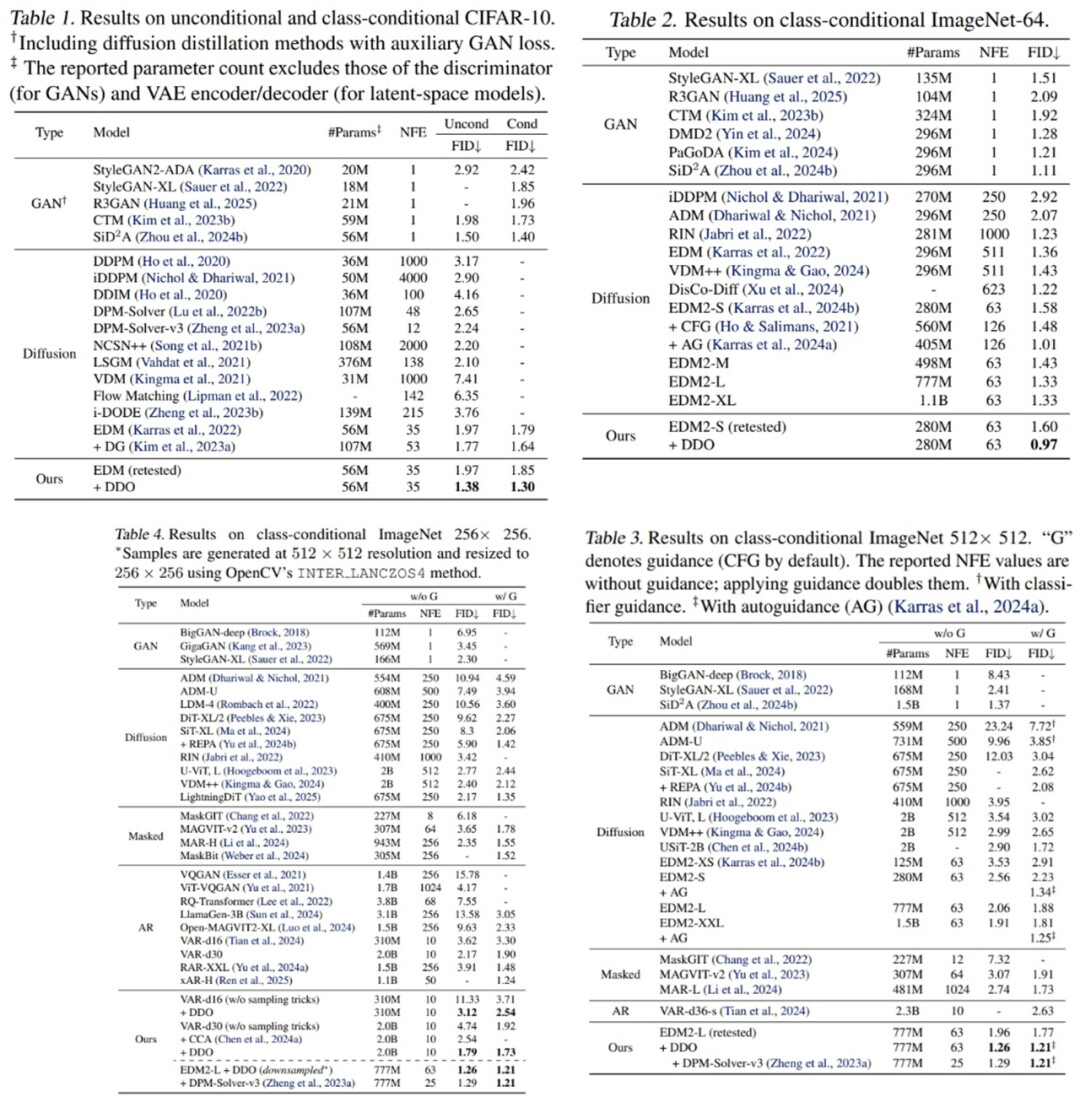
DDO 用于扩散模型时,随着多轮 self-play,FID 指标发生持续下降。
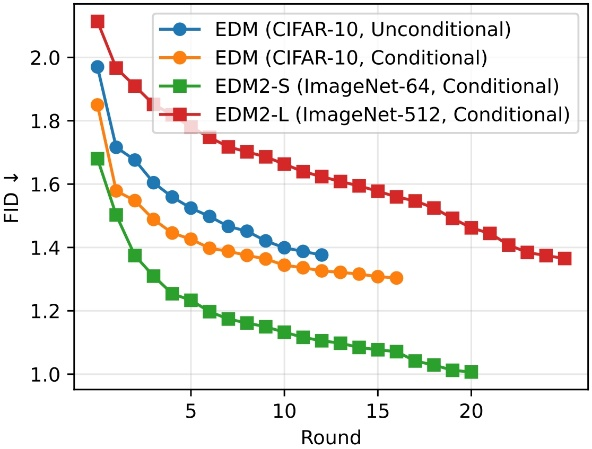
更重要的是,DDO 无需修改网络结构、不增加推理成本,且与主流 CFG 等引导方法兼容,可叠加使用进一步提升性能。如在视觉自回归模型 VAR 上,微调后的模型通过控制 CFG 的强度,得到的 FID-IS 曲线整体显著优于原模型。
展望 | 从视觉生成到语言模型对齐
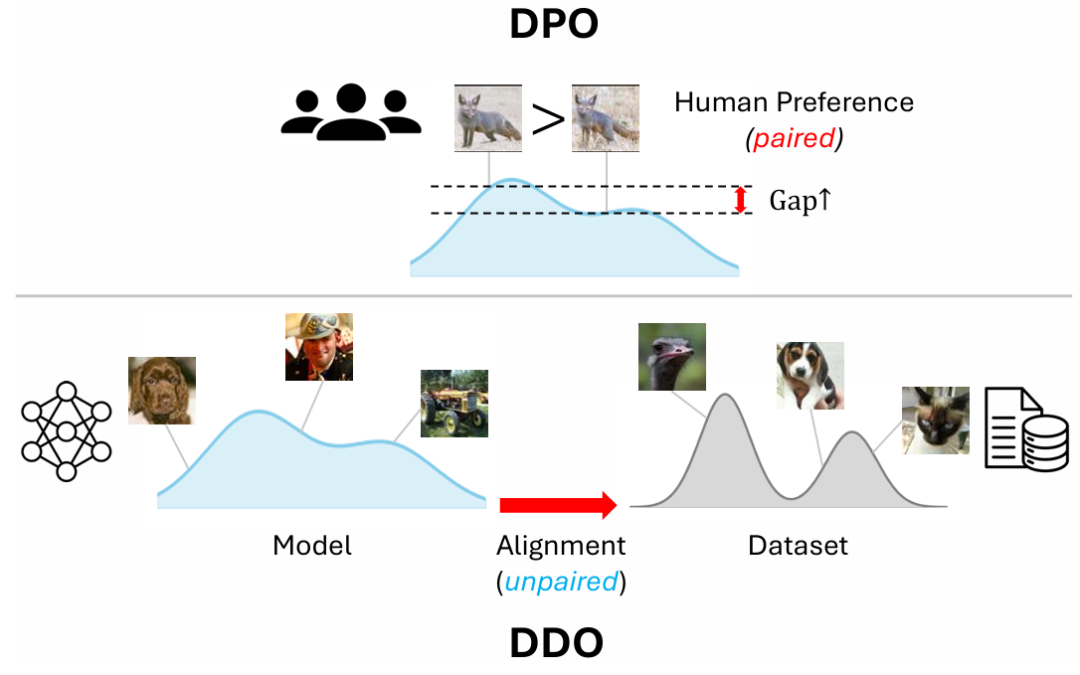
DDO 参数化的灵感来自于语言模型中的直接偏好优化(DPO, Direct Preference Optimization),但其目标从「成对的偏好对齐」扩展到了「分布对齐」,更为通用。DDO 虽然没有「奖励」的概念,但其中使用自生成样本作为负例的思想也与大语言模型中流行的 RL 算法如 GRPO 具有相似性,这允许模型从错误中反思学习。也就是说,GRPO 中负例的作用同样可以解释为使用 reverse KL 散度抑制 mode covering 趋势从而提升生成质量,这在数学推理等任务中具有重要意义。该思路有望扩展至多模态生成等任务,构建统一的对齐范式。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com