本文综述了通用视觉模型(VGM)的研究进展,涵盖模型设计、评测与应用。VGM旨在统一处理多模态视觉输入和多样化任务,未来将在自动化标注和多模态应用中发挥重要作用。
原文标题:大模型时代,通用视觉模型将何去何从?
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到VGM面临数据获取和标注的瓶颈,除了自动化标注,还有什么其他可能的解决方案?
3、通用视觉模型在伦理和偏见方面存在哪些潜在风险?如何确保模型的公平性和安全性?
原文内容

过去几年,通用视觉模型(Vision Generalist Model,简称 VGM)曾是计算机视觉领域的研究热点。它们试图构建统一的架构,能够处理图像、点云、视频等多种视觉模态输入,以及分类、检测、分割等多样的下游任务,向着「视觉模型大一统」的目标迈进。
然而,随着大语言模型 LLM 的迅猛发展,研究热点已经悄然发生转移。如今,多模态大模型兴起,视觉被看作是语言模型众多输入模态中的一种,视觉模态数据被离散化为 Token,与文本一起被统一建模,视觉的「独立性」正在被重新定义。
在这种趋势下,传统意义上以视觉任务为核心、以视觉范式为驱动的通用视觉模型研究,似乎正在逐渐被边缘化。然而,我们认为视觉领域仍应保有自己的特色和研究重点。与语言数据相比,视觉数据具有结构化强、空间信息丰富等天然优势,但也存在视觉模态间差异大、难替代的挑战。例如:如何统一处理 2D 图像、3D 点云和视频流等异质输入?如何设计统一的输出表示来同时支持像素级分割和目标检测等不同任务?这些问题在当前的多模态范式中并未被充分解决。
正因如此,在这个多模态模型席卷科研与工业的新时代,回顾并总结纯视觉范式下的通用视觉模型研究仍然是一件十分有意义的事情。清华大学自动化系鲁继文团队最近发表于 IJCV 的综述论文系统梳理了该方向的研究进展,涵盖输入统一方法、任务通用策略、模型框架设计、模型评测应用等内容,希望能为未来视觉模型的发展提供参考与启发。

-
论文标题:Vision Generalist Model: A Survey
-
论文链接: https://arxiv.org/abs/2506.09954
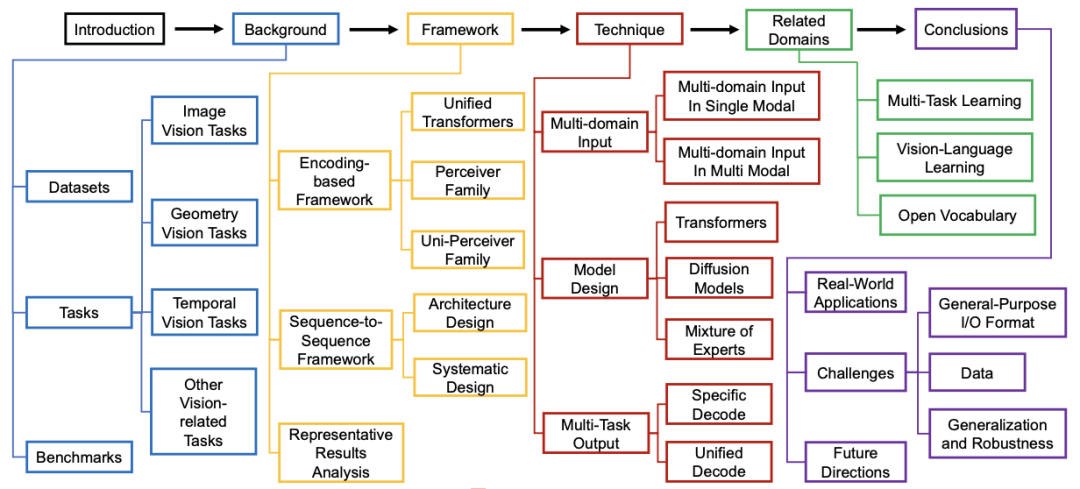
VGM 到底解决了什么问题?
通用视觉模型是一种能够处理多种视觉任务和模态输入的模型框架。类似于大语言模型在自然语言处理中的成功,VGM 旨在通过构建一个统一的架构来解决各种计算机视觉任务。传统的视觉模型通常针对特定任务(如图像分类、目标检测、语义分割等)设计,而 VGM 通过广泛的预训练和共享表示,能够在不同的视觉任务之间实现零样本(Zero-shot)迁移,从而无需为每个任务进行专门的调整。
VGM 的关键能力之一是其多模态输入的统一处理能力。不同于传统模型只处理单一类型的视觉数据,VGM 能够同时处理来自多个模态的数据,如图像、点云、视频等,并通过统一的表示方法将它们映射到共享的特征空间。
此外,VGM 还具备强大的多任务学习能力,能够在同一个模型中处理多个视觉任务,从图像识别到视频分析,所有任务都可以在一个通用框架下并行处理。
综述涵盖了哪些核心内容?
数据 + 任务 + 评测:为通用建模打基础
VGM 通常使用大规模、多样化的数据集进行训练和评估。为了支持多模态学习,VGM 使用的训练数据集涵盖了图像、视频、点云等多种类型,本综述列举并介绍了一些常见的多模态数据集。
任务方面,本综述将视觉任务分为四类:图像任务、几何任务、时间序列任务以及其他视觉相关任务。评测方面,主要通过多个综合基准来衡量其在多种任务和数据集上的表现。与传统的单一任务评测不同,现代评测方法更注重模型的跨任务泛化和多模态处理能力。本综述也对现有通用视觉模型的评测基准做了充分的调研与总结。
模型设计范式与技术补充
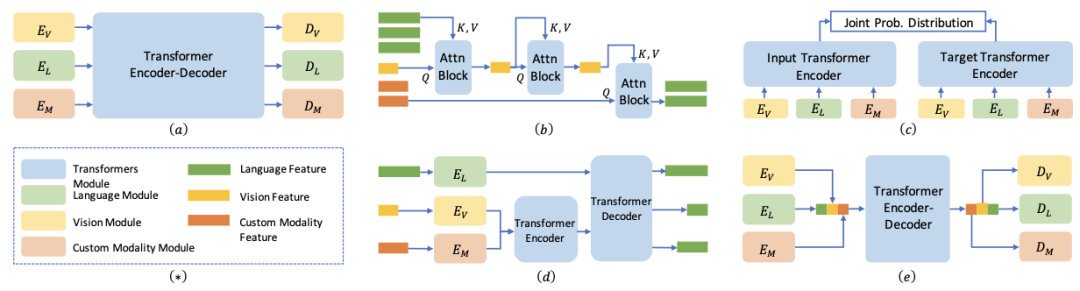
现有通用视觉模型的设计范式主要集中在如何统一处理不同视觉模态输入和多样化任务输出,大致可以分为两种类型:编码式框架和序列到序列框架。
编码式框架(Encoding-based Framework)旨在通过构建一个共享的特征空间来统一不同的输入模态,并使用 Transformer 等模型进行编码。这类框架通常包括领域特定的编码器来处理不同类型的数据,如图像、文本和音频,然后通过共享的 Transformer 结构进行进一步处理,最终生成统一的输出。
而序列到序列框架(Sequence-to-Sequence Framework)则借鉴了自然语言处理中的序列建模方法,将输入数据转换为固定长度的表示,然后通过解码器生成相应的输出。这些框架特别适合处理具有可变长度输入输出的任务,如图像生成和视频分析。
尽管有一些工作并不能被定义为通用视觉模型,但它们在联合多模态数据输入、模型架构设计、协同处理多任务输出等方面做出了卓越的技术贡献。本综述也对这些技术进行了详尽的讨论分析。一些相关领域的内容,如多任务学习、视觉-语言学习、开放词汇,也被用来扩充通用视觉模型领域的知识边界。
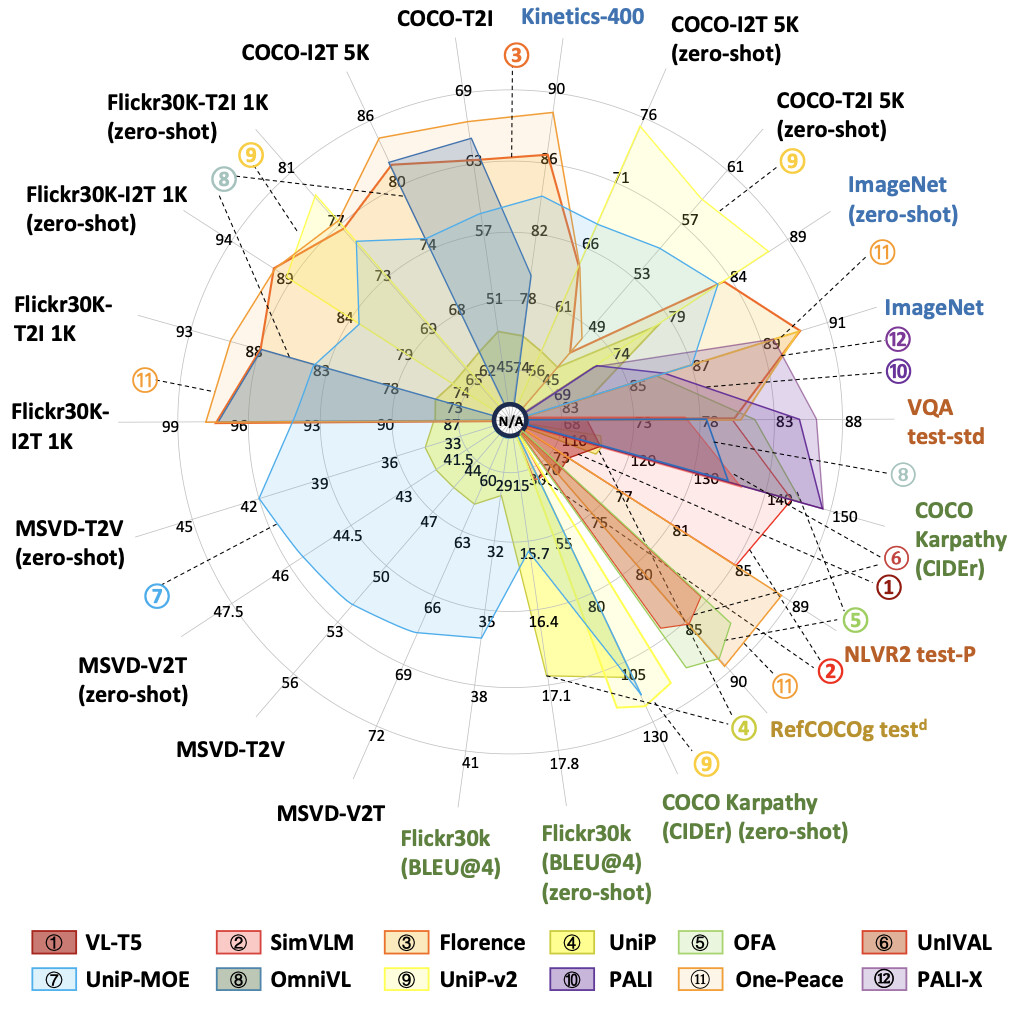
此外,作为一个 case study,本综述对比了收录了多个主流 VGM 模型在 22 个基准数据集上的评测结果:
VGM 的未来在哪里?
最后,本综述总结了 VGM 的当前研究进展和面临的挑战,还强调了其在实际应用中的潜力和未来发展方向。
现有 VGM 在多个任务和多模态输入的统一处理方面已经取得了显著的进展,但仍面临着如何优化统一框架设计、提高训练效率和应对大规模数据等挑战。数据获取和标注仍然是 VGM 发展的瓶颈。
为了解决这一问题,自动化标注技术以及大规模无监督学习方法的研究将成为未来的研究重点。然而,随着模型规模的扩大,VGM 也面临着伦理问题和偏见的挑战。大量未标注的数据中可能包含潜在的偏见,如何确保模型的公平性、透明性和安全性,仍是未来研究中的重要课题。
尽管如此,现有的 VGM 在实际应用中展示了广泛的潜力。它不仅可以用于传统的视觉任务,如图像分类、目标检测和语义分割,还能扩展到更复杂的多模态任务,如视觉问答、图像-文本检索、视频理解等。这些应用涵盖了智能监控、自动驾驶、机器人等多个领域,推动了 VGM 在实际场景中的广泛部署。
希望这篇文章能给研究中的你一些启发。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com