腾讯混元开源Hunyuan-A13B混合推理模型,擅长Agent工具调用与长文本理解,性能媲美同类模型,推理速度更快,并开源两个数据集。
原文标题:腾讯混元推出首款开源混合推理模型:擅长Agent工具调用和长文理解
原文作者:AI前线
冷月清谈:
怜星夜思:
2、Hunyuan-A13B 支持的快慢思考模式,在实际应用中如何权衡?有没有具体的场景案例可以分享?
3、文章提到的 ArtifactsBench 和 C3-Bench 数据集,分别解决了大模型 Agent 评估中的哪些痛点?对于大模型开发者来说,如何有效利用这些数据集?
原文内容

6 月 27 日,腾讯混元宣布开源首个混合推理 MoE 模型 Hunyuan-A13B,总参数 80B,激活参数仅 13B,效果比肩同等架构领先开源模型,但是推理速度更快,性价比更高。模型已经在 Github 和 Huggingface 等开源社区上线,同时模型 API 也在腾讯云官网正式上线,支持快速接入部署。
开源地址:
Github :https://github.com/Tencent-Hunyuan
HuggingFace:https://huggingface.co/tencent
据介绍,这是业界首个 13B 级别的 MoE 开源混合推理模型,基于先进的模型架构,Hunyuan-A13B 表现出强大的通用能力,在多个业内权威数据测试集上获得好成绩,并且在 Agent 工具调用和长文能力上有突出表现。
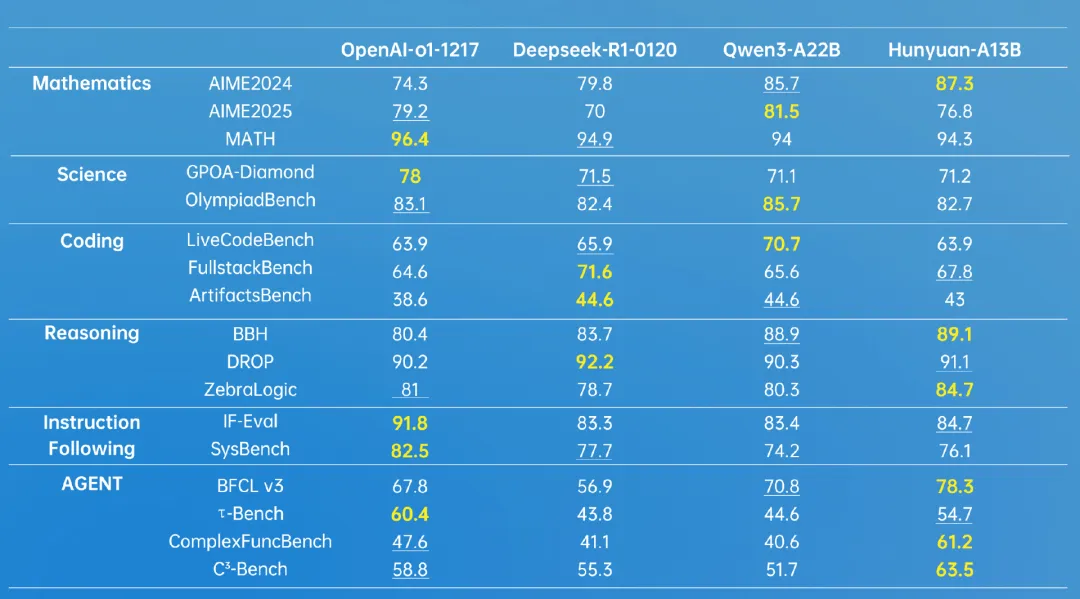
_* 加粗为最高分,下划线表示第二名,数据来源于模型各个公开的测试数据集得分 _
对于时下热门的大模型 Agent 能力,腾讯混元建设了一套多 Agent 数据合成框架,接入了 MCP、沙箱、大语言模型模拟等多样的环境,并且通过强化学习让 Agent 在多种环境里进行自主探索与学习,进一步提升了 Hunyuan-A13B 的效果。
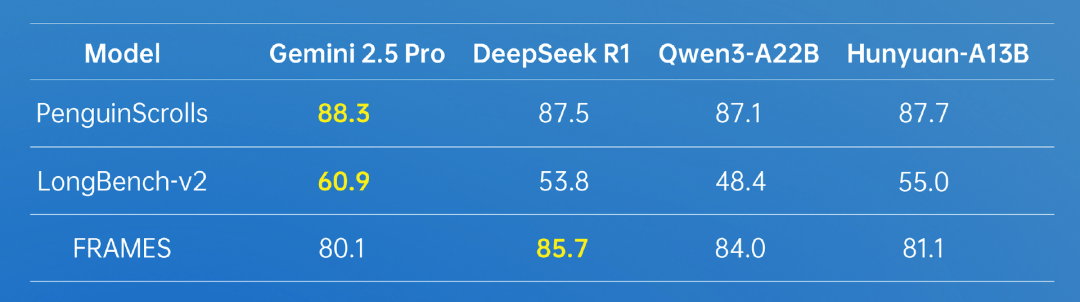
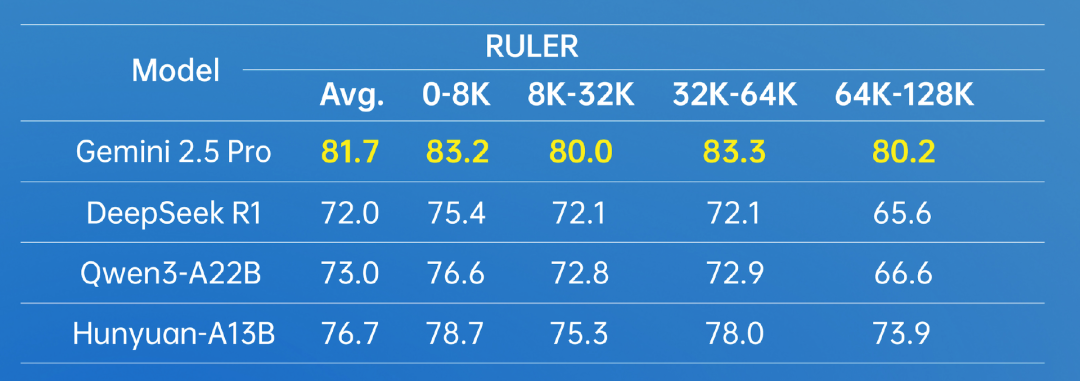
在长文方面,Hunyuan-A13B 支持 256K 原生上下文窗口,在多个长文数据集中取得了优异的成绩。
在实际使用场景中,Hunyuan-A13B 模型可以根据需要选择思考模式,快思考模式提供简洁、高效的输出,适合追求速度和最小计算开销的简单任务;慢思考涉及更深、更全面的推理步骤,如反思和回溯。这种融合推理模式优化了计算资源分配,使用户能够通过加 think/no_think 切换思考模式,在效率和特定任务准确性之间取得平衡。

Hunyuan-A13B 模型对个人开发者较为友好,在严格条件下,只需要 1 张中低端 GPU 卡即可部署。目前,Hunyuan-A13B 已经融入开源主流推理框架生态,无损支持多种量化格式,在相同输入输出规模上,整体吞吐是前沿开源模型的 2 倍以上。
Hunyuan-A13B 集合了腾讯混元在模型预训练、后训练等多个环节的创新技术,这些技术共同增强了其推理性能、灵活性和推理效率。
预训练环节,Hunyuan-A13B 训练了 20T tokens 的语料,覆盖了多个领域。高质量的语料显著提升了模型通用能力。此外,在模型架构上,腾讯混元团队通过系统性分析,建模与验证,构建了适用于 MoE 架构的 Scaling Law 联合公式。这一发现完善了 MoE 架构的 Scaling Law 理论体系,并为 MoE 架构设计提供了可量化的工程化指导,也极大的提升了模型预训练的效果。
后训练环节,Hunyuan-A13B 采用了多阶段的训练方式,提升了模型的推理能力,同时兼顾了模型创作、理解、Agent 等通用能力。

图:Hunyuan-A13B 后训练四个步骤
为更好的提升大语言模型能力,腾讯混元也开源了两个新的数据集,以填补行业内相关评估标准的空白。其中,ArtifactsBench 用于弥合大语言模型代码生成评估中的视觉与交互鸿沟,构建了一个包含 1825 个任务的新基准,涵盖了从网页开发、数据可视化到交互式游戏等九大领域,并按难度分级以全面评估模型的能力;C3-Bench 针对 Agent 场景模型面临的三个关键挑战:规划复杂的工具关系、处理关键的隐藏信息以及动态路径决策,设计了 1024 条测试数据,以发现模型能力的不足。

