DataV-Note揭秘AI数据分析报告评估体系,通过量化标准和多维度评估模型,提升报告质量和准确性。
原文标题:如何让AI写出高质量的数据分析报告?DataV-Note的评估体系揭秘
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章中强调了智能体的原子性,为什么避免智能体“三心两意”如此重要?在实际应用中,如何把握智能体切分的尺度才能达到最佳效果?
3、文章提到了纵向和横向对比评估,这两种方法分别侧重于评估报告的哪些方面?在实际应用中,如何结合这两种方法来全面评估AI生成的数据分析报告?
原文内容

阿里妹导读
本文围绕DataV-Note智能分析创作平台的评估体系建设展开,旨在探索如何在AI技术快速发展的背景下,构建一套科学、可量化、多维度的数据分析报告评估体系。
一、前言
在AI技术蓬勃发展的时代浪潮中,我部门于两年前推出DataV-Note智能分析创作平台,通过提供数据分析洞察、行业数据分析报告、学术/医学研究报告的智能仿写等创新服务,致力于实现数据价值与文字表达的深度融合。
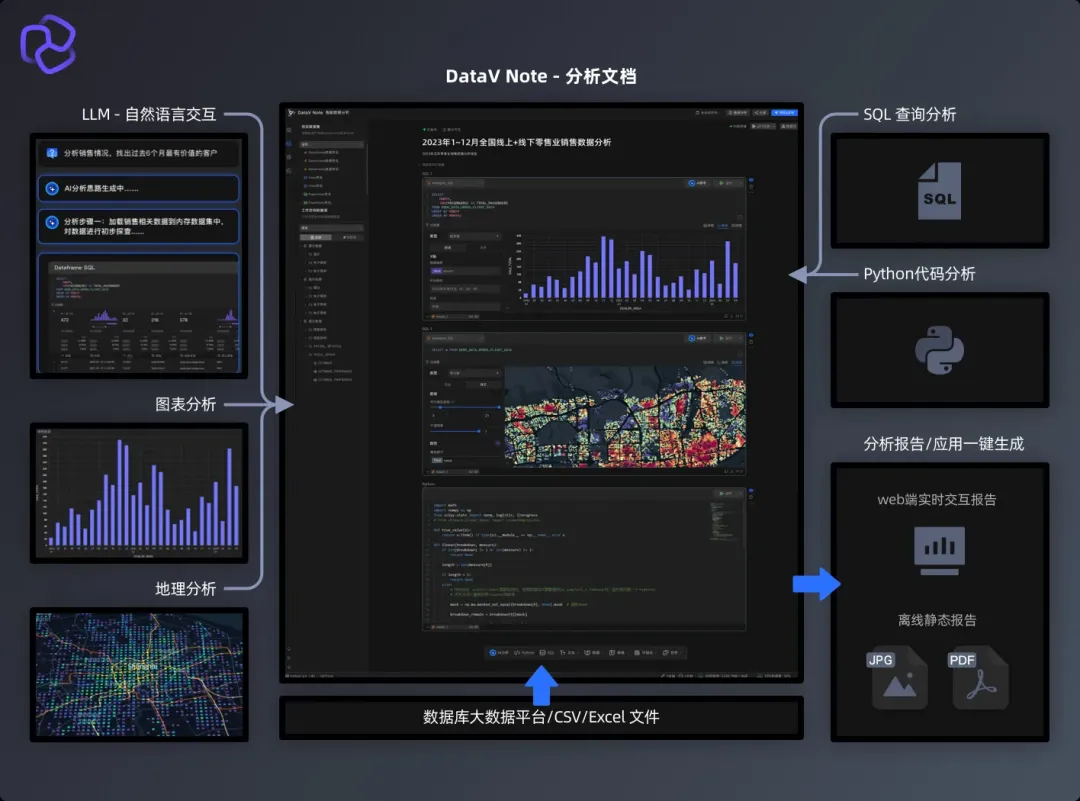
DataV智能化生成大屏、数据地图、数据报告体验链接:https://datav.aliyun.com/ai
随着各类Data/Analyze Agent相继涌现,行业生态面临前所未有的市场压力。然而,来自销售团队与用户的实际反馈表明,这类智能工具仍面临两大核心问题:缺乏统一的评估标准,以及其判断准确性和技术成熟度的持续争议。这种认知差异不仅影响产品价值的有效传达,也给行业规范化发展带来重要挑战。
二、建立量化评估标准,构建评估模型
2.1、评估模型的目标确立
在构建评估模型前,我们需系统梳理其核心目标及应用场景,以细化后续系统设计工作:
-
产品验证:建立可量化的准确度评估指标;输出符合行业标准的评估报告;
-
竞品分析:通过多维度对比,生成差异化竞争力评估报告;
-
自动化测试:对于模型的频繁切换、提示词优化、AI工程优化等需求进行回归测试评估;
-
准确度提升:通过将评估模型深度嵌入产品优化闭环系统,动态校准原有智能体的幻觉;
2.2、评估模型的初步设计
(1)设计前言
在着手搭建评估模型前,我们先研究现有分析报告的产物,这将有助于更优雅地设计把握模型设计的架构:
以下图片是对自然灾害的分析报告部分片段
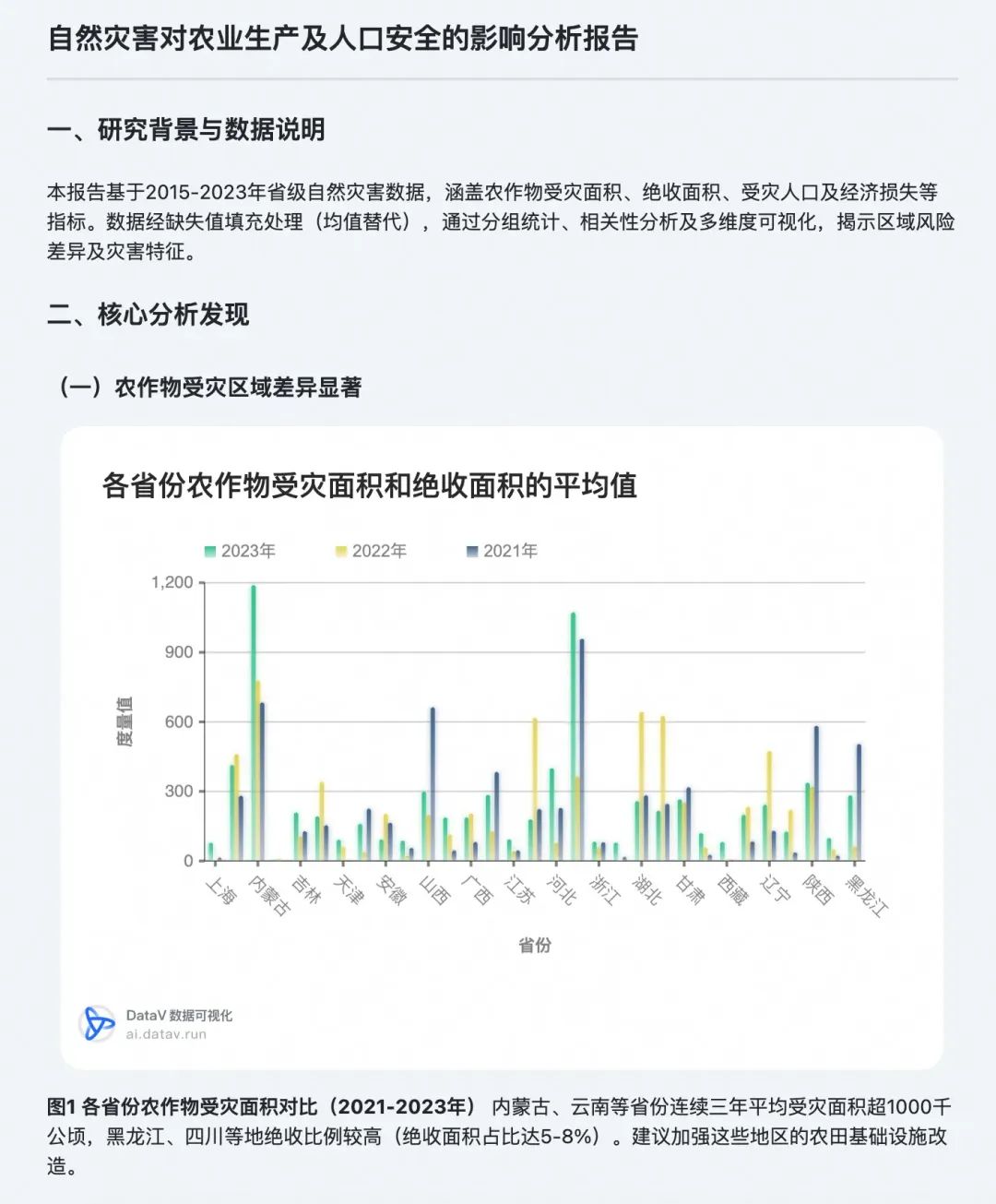
从上图可以看出,与传统评估模型侧重文字和数值判断不同,我们的评估体系覆盖了更立体的分析维度。评估范围不仅包含文本、图表、代码、表格,还延伸至整体分析框架和方法论。大多数的数据分析产品通常输出PDF、Word、PNG或HTML格式的产物。因此,我们设计的模型既需要识别多模态的内容,也需要支持读取丰富格式的导出产物。
(2)设计架构
经过综合考量,我们选用了Qwen VL模型负责内容提取,Qwen 3模型承担内容评估工作,并据此制定了以下技术架构方案:
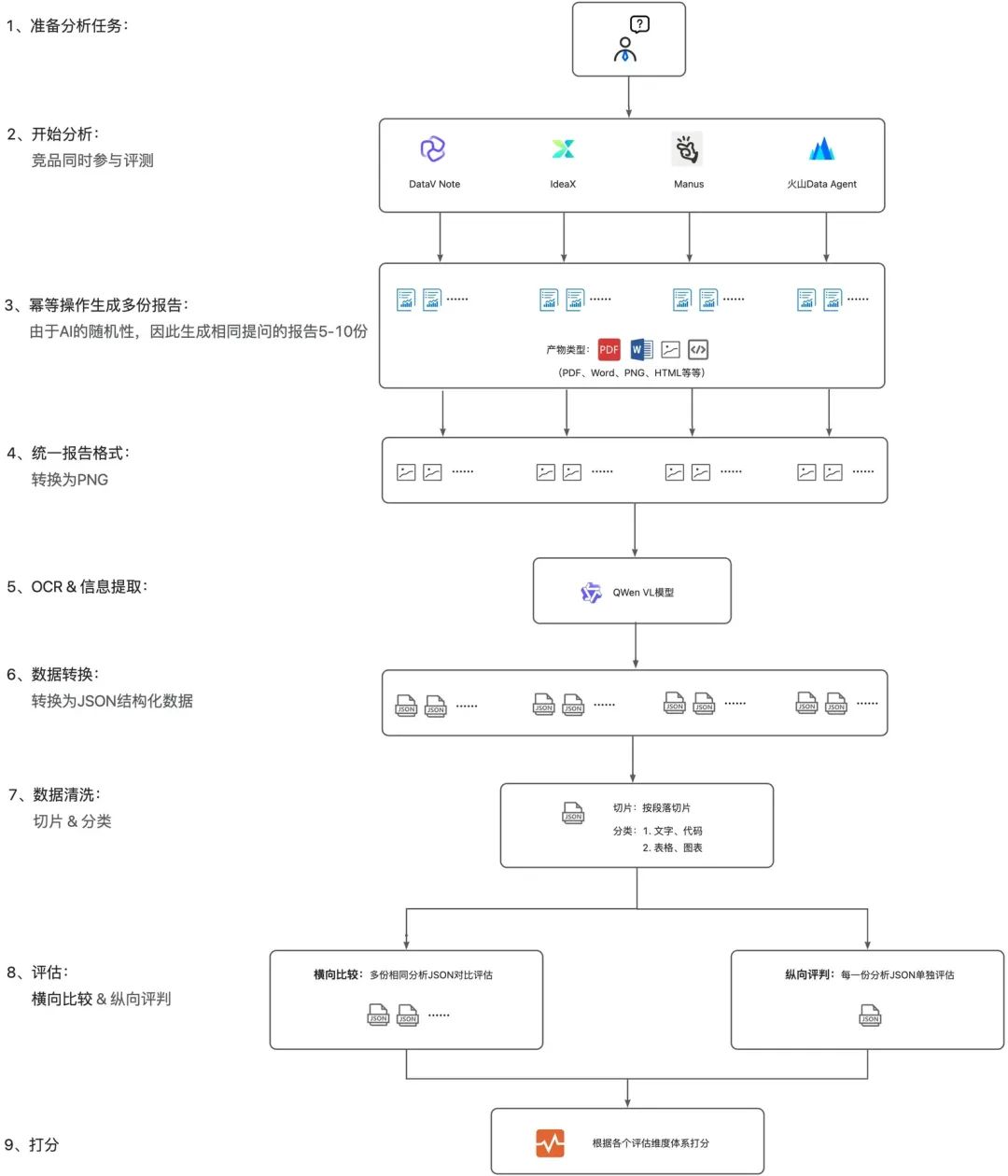
(3)设计细节
在搭建评估系统时,我们经历了不少挑战,也摸索出不少改进方法。接下来重点分享其中几个关键细节:
虽然市面上已有不少提示词优化工具和教程,但对于涉及视觉识别的任务来说,这些工具往往只能实现70-80分的水平。如下面例子所示,这类任务需要我们特别注意:
-
完整描述视觉元素:清晰地描述所有的视觉元素,以及所有元素的特征;
-
明确操作流程:将复杂任务拆解为可执行的步骤,每个可执行的步骤必须清楚、细致;
-
严格的边界限制:以免幻觉和意外的结果发生;
视觉识别Prompt
## 角色
你是一位专业的图像分析专家,擅长从图片中提取图表、表格、代码和文字等类型的内容,并能够准确描述对应内容的详细信息和数值。
任务
任务1:提取图表类型的对应信息
- 1、特别仔细的观察图片,图表的背景和报告的背景颜色明显不同
- 2、识别图表的图表类型,可通过图表展示或者图表的上下文提示来进行识别,如柱状图、折线图、饼图等等
- 3、识别图表的标题,假如图表上方出现加粗的字体,则为图表的标题,若没有图表上方加粗字体,则输出"无"
- 4、识别图表的元信息,例如:柱状图需要识别x、y轴信息,饼图需要识别每个扇区的名称等等
- 5、识别图表的内容,即图表的完整具体数据,数据只允许来源于图表识别,识别不出则输出"无法识别"
任务2:提取表格类型的对应信息
- 1、识别表格的元信息,即表格的头部(columns)信息,数据只允许来源于表格识别,识别不出则输出"无法识别"
- 2、识别表格的内容,即表格的具体数据,数据只允许来源于表格识别,识别不出则输出"无法识别"
任务3:提取代码类型的对应信息
- 1、识别代码中的类型,请识别语言的类型,类型有"SQL"和"Python"
- 2、识别代码中的内容
任务4:提取文字类型的对应信息
- 1、识别代码中的文字类型,类型有"内容"、“注释”。注释一般是较小的字体,有可能伴随着斜体,颜色会比正常内容更浅
- 2、识别代码中的内容,需要识别图上除了图表标题以为的所有问题
输出格式
- 参照以下例子的格式作为输出格式:
{
‘文件名’: ‘xxx’,
‘标题’: ‘xxx’,
‘正文’: [{
‘章节标题’: ‘xxx’,
‘内容’: [{
‘类型’: ‘xx’, // 类型为“图表”、“表格”、“代码”和“文字”等类型
‘内容’: ‘xxxx’
}, {
‘类型’: ‘xx’,
‘内容’: ‘’
}, {
‘类型’: ‘xx’,
‘图表类型’: ‘xxx’, // 只有“图表”类型有
‘标题’: ‘’, // 只有“图表”类型有
‘元信息’: ‘’, // 只有“图表”类型有
‘内容’: xxx, // “图表”类型中,内容输出json格式
}]
}]
}
限制
- 只针对图片内容进行描述和分析,不涉及其他无关信息
- 提取信息过程忽略页头和页尾
- 必须按照图片报告的排版顺序进行解析
- 在描述图片时,确保信息的准确性和完整性
- 在提取“文字”信息时,确保文字的清晰度和可读性
- 在提取“图表”信息时,确保图表的信息准确性和完整性,必须输出所有内容,不能省略某些信息
- 在提取“图表”的“内容”字段信息时,内容可以根据所在章节的上下文进行数值校验,以文字描述为主
- 判断类型时,严格按照给定的类型进行分类
请再三检查,严格按标准的输出格式进行输出,输出的JSON格式不能有语法错误
三心两意,对于打工人“牛马”都做不到,更何况现在“不太聪明”的智能体。因此,智能体必须保持原子性,主要体现到以下两点:
-
功能/角色原子性:每个智能体都是相对独立的功能单元。例:不能让智能体既要做图片识别的工作又要评估的工作。
-
维度/类别原子性:每个智能体都是单独维度、类别的单元。例:在“评估推理大师”的角色中,不能让大模型既要做“归因分析”的评估,又要做“可视化”的评估。
常见的误解:在设计智能体时要把握好切分的尺度,过度拆分会导致增加token消耗,又可能导致并发负载过高。举个实际场景,在分析报告时,"中位数"和"平均数"这类同属统计维度的概念,完全可以通过同一个智能体完成识别解析,没有必要拆分。
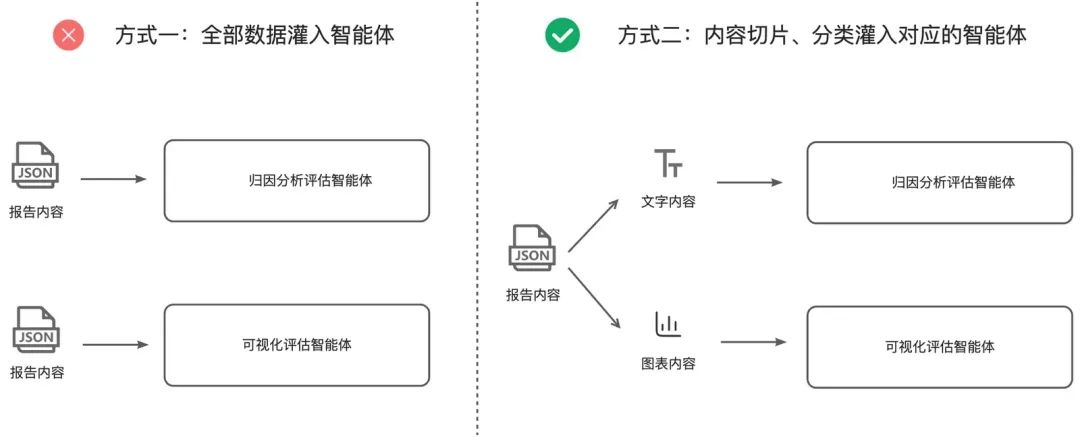
输入数据的过滤、清洗尤为关键,主要体现为以下两点:
-
千万不要用大模型来做数据清洗工作。大模型虽然擅长搜索和推理,但在处理数据清洗、字段拼接这类操作时效率较低,而且结果往往不如预期理想。
-
遵循最小化原则。如【2】所述,每个智能体都是相对独立的功能单元,通过最小化数据输入既能减少token消耗,也能让模型更专注处理核心内容片段。
如下图所示,“归因分析评估智能体”主要聚焦于文本内容分析,“可视化评估智能体”则专注于图表识别。若直接将完整报告内容全部输入,不仅会显著增加各智能体的处理负担,导致token消耗激增,还可能引发模型输出偏差(幻觉)。建议通过内容切片、分类机制,按需输入对应模块所需数据,既能提升处理效率,又能保证分析准确性。
2.3、评估标准的建立
在实际体验中,当用户提问数次都未能获得有效反馈时,用户就很可能给这款AI产品判“死刑”。因此,在搭建评估体系时,必须从各个维度全面地评估产品,并且不能忽视大模型的随机性。具体来说,我采用两种评估方式:
-
纵向评估:我会针对同一问题生成5-10份分析报告。以“基础维度”、“可视化维度”、“归因分析维度”来作为评估的维度,并且会给每一份报告打分。
-
横向对比评估:将多份报告并列比对时,重点排查“主题”、“建议”、“核心指标”等异常的情况。
值得注意的是:在进行横向对比时,需要特别注意前提条件的严格把控,不能出现“牛头不搭马嘴”的情况。例:当我们比较核心指标时,必须确保统计维度、计算规则和业务背景都保持一致。
(1)纵向(单份报告评估)评估体系
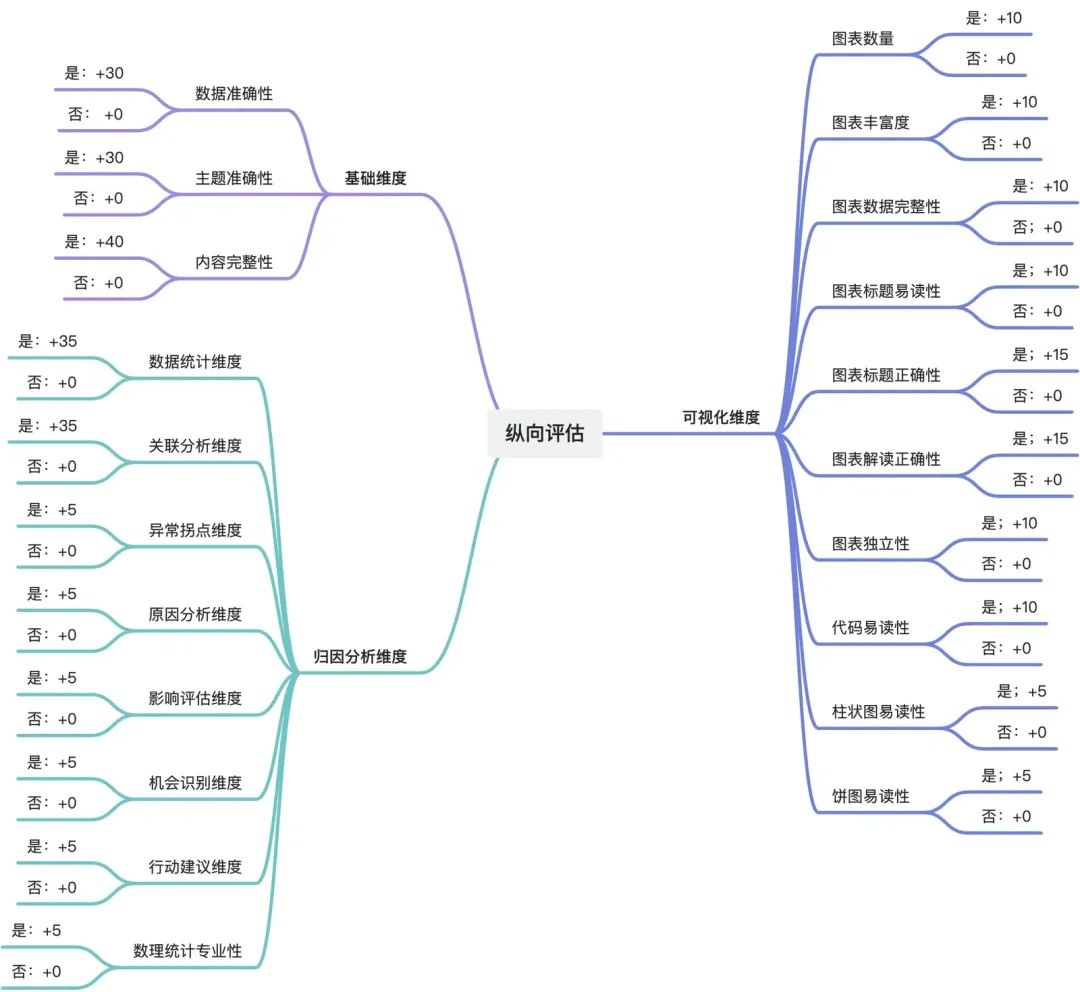
考虑到篇幅限制,我将重点呈现"归因分析维度"的评估内容:
### 归因分析维度
* 数据统计维度
* 内容:内容中是否存在“基础统计分析”、“分析特征”、“趋势变化分析”等维度进行分析;并输入其上下文
* 评分:
- 0分:否
- 35分:是
* 关联分析维度
* 内容:内容中是否存在“因素相关性”、“交叉分析”、“维度组合分析”、“地理、时间、群体、流程、成本、收益、技术等等维度对比”等维度进行分析;并输入其上下文
* 评分:
- 0分:否
- 35分:是
* 异常拐点维度
* 内容:内容中是否存在“数据异常点”、“特殊模式”、“变化拐点”等维度进行分析;并输入其上下文
* 评分:
- 0分:否
- 5分:是
* 原因分析维度
* 内容:内容中是否存在“直接原因”、“根本原因”、“关联因素”等维度进行相关分析;并输入其上下文
* 评分:
- 0分:否
- 5分:是
* 影响评估维度
* 内容:内容中是否存在“问题严重度”、“影响范围”、“持续时间”等维度进行相关分析;并输入其上下文
* 评分:
- 0分:否
- 5分:是
* 机会识别维度
* 内容:内容中是否存在“改进空间”、“优化机会”、“创新点”等维度进行相关分析;并输入其上下文
* 评分:
- 0分:否
- 5分:是
* 行动建议维度
* 内容:内容中是否存在“解决方案”、“实施路径”、“效果评估”等维度进行分析;并输入其上下文
* 评分:
- 0分:否
- 5分:是
* 数理统计专业性
* 内容:是否使用了专业数理统计分析理论,如“平均数、标准差、标准误、变异系数率、均方、检验推断、相关、回归、聚类分析、判别分析、主成分分析、正交试验、模糊数学、灰色系统理论、CAGR(复合增长率)、泰尔指数”、“斯皮尔曼相关性”、“皮尔逊相关系数矩阵”等等;并说明使用了什么数理统计分析理论
* 评分:
- 0分:否
- 5分:是
(2)横向(多份报告对比评估)评估体系
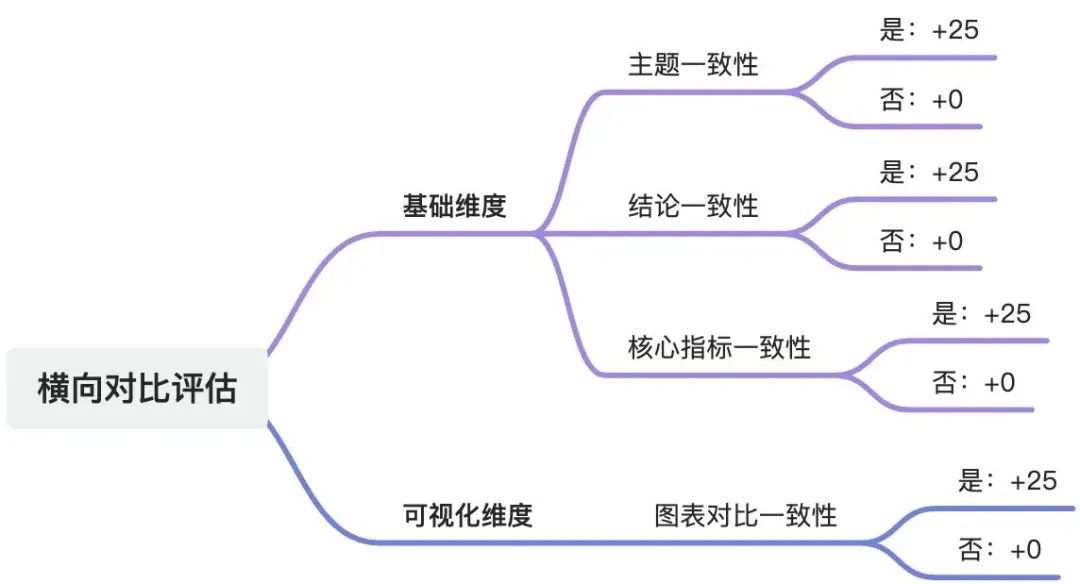
### 异常对比维度
* 主题对比一致性
* 内容:各份JSON数据之间的分析主题是否相似或统一;并输出对应文件中具体差异点
* 评分:
- 0分:否
- 25分:是
* 结论对比一致性
* 内容:各份JSON数据之间的结论或建议是否相似或统一;并输出对应文件中具体差异点
* 评分:
- 0分:否
- 25分:是
* 核心指标对比一致性
* 内容:各份JSON数据之间的“文字”类型的内容中,是否出现统计维度、计算方法、上下文含义完全相同的核心统计指标不一致;并输出对应文件中具体差异点
* 评分:
- 0分:是
- 25分:否
* 图表对比一致性
* 内容:各份JSON数据之间若存在元信息、图表类型、统计维度、标题含义、所在章节含义完全相同的图表,是否存在数值统计不一致的情况;并输出对应文件中具体差异点
* 评分:
- 0分:是;或不存在相同图表
- 25分:否
2.4、评估结果
以下是针对同一个分析任务生成的5份报告,每份报告不仅包含评分结果,还附有具体评分依据的说明:
任务:分析下各省份、各单位不同时间的平均工资,并且如何为实现共同富裕,对工资进行优化。
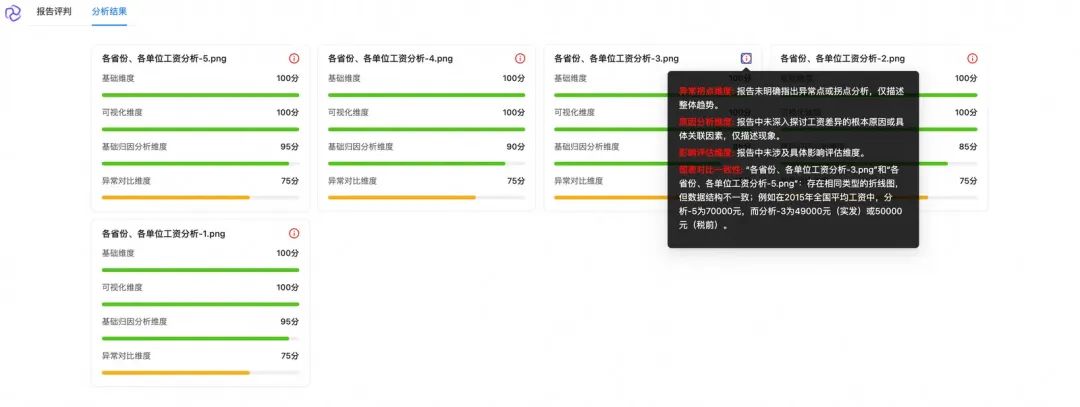
以下是DataV-Note的部分测试结果展示,每个测试案例均基于5份独立生成的报告进行评分:

三、未来规划
3.1、接入自动化
当前我们仍需手动执行跨平台分析任务,并将结果导入评估系统。未来计划接入browser-user实现自动化大规模测试。

3.2、利用评估模型提高准确度
其次,我们计划将评估模型嵌入知识评估、RAG的环节中,以此增强数据分析模型的能力。
四、总结
通过本次评估系统搭建和日常分析报告的评估实践,我们发现尽管大模型展现出强大潜力,但在产品层面实现数据分析的精准把控仍面临诸多挑战。期待大家不吝赐教,共同探讨优化方案。
与 AI 智能体进行实时音视频通话
AI 实时音视频互动是一种旨在帮助企业快速构建 AI 与用户之间的视频或语音通话应用的解决方案。用户只需通过白屏化的界面操作,即可快速构建一个专属的AI智能体,并通过视频云 ARTC 网络与终端用户进行实时交互。
点击阅读原文查看详情。