阿里云结合MCP Server和大模型,实现云产品管理的自然语言操作,提升效率和体验。通过CherryStudio配置,解决上下文长度限制,并展望未来应用。
原文标题:大模型终于能“听懂”云操作了?
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章提到了解决大模型上下文长度限制的一种方案:先让LLM根据工具的name和description进行判断,选择需要的tool,然后再配置LLM。那么这种方式是否存在风险?例如,LLM可能因为对工具理解的偏差而错误选择,导致最终结果不准确。如何降低这种风险,保证选择的tool是真正符合用户需求的?
3、文章最后展望了MCP的未来,提到了建立每个云产品Agent和搭建Agent矩阵。那么,在Agent数量不断增加的情况下,如何保证Agent之间的协作效率和整体系统的可维护性?是否存在“Agent膨胀”的风险,导致系统变得臃肿和难以管理?
原文内容

阿里妹导读
本文通过 MCP Server 和大模型的结合,实现云产品管理的自然语言操作,极大提升开发者的操作效率和用户体验。
前言
对于阿里云用户而言,管理云产品通常有几种方式:控制台、OpenAPI SDK、CADT、Terraform 等。虽然形式不同,但本质上这些操作都要依赖于 OpenAPI 来完成。在 MCP 出现之前,如果用户希望通过自然语言来操作云产品,唯一的办法就是对照产品文档,手动编写一条条 FunctionCall 描述,再交给大模型进行调用。这种方式不仅繁琐,而且效率低下。几周前,当得知 OpenAPI 推出内测版的 MCP Server 时,我意识到一个重要的机会来了。设想一下,在简单配置好 MCP Server 后,只需问一句:“我在杭州可用区有哪些资源?”、“哪个Region有 L20 显卡,费用是多少?”、“杭州某个 ACK 集群当前的负载情况如何?”等问题,大模型就能自动调用相关工具,然后给出准确的回答。这种交互体验和效率提升将是前所未有的。在这篇小文中,我会结合自己的实际使用情况,和大家一起“趟趟水”、“踩踩坑”。本文主要基于个人的理解与实践,只讲大白话,如有理解错误的地方非常欢迎大家批评、指正。
一、上手体验
以下以CherryStudio为例,简要介绍一下快速上手过程。
1.1 如何配置
总共分三步:
第一步:点击 OpenAPI MCP[1]服务来创建一个云产品的MCP Server,每个云产品最多选30个;
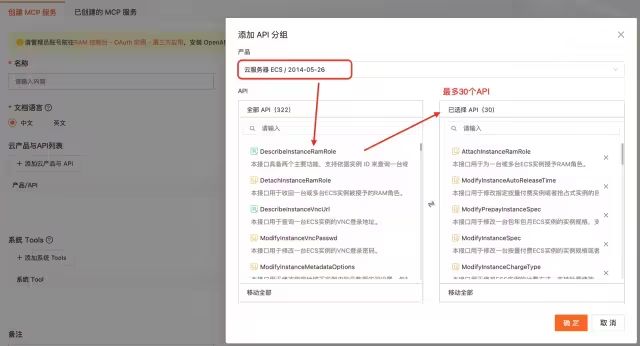
图1. 选择某云产品(如ECS)API列表
第二步:确保已登录阿里云账号,CherryStudio需要通过OAuth2.0来授权,如果使用的是RAM账号的话需要提前添加服务策略;
第三步:配置CherrySudio,该软件是一款国人开发的多模型聚合、一体化工具,有很多现成的智能体(主要是提示词),也和百炼MCP做了深度集成。
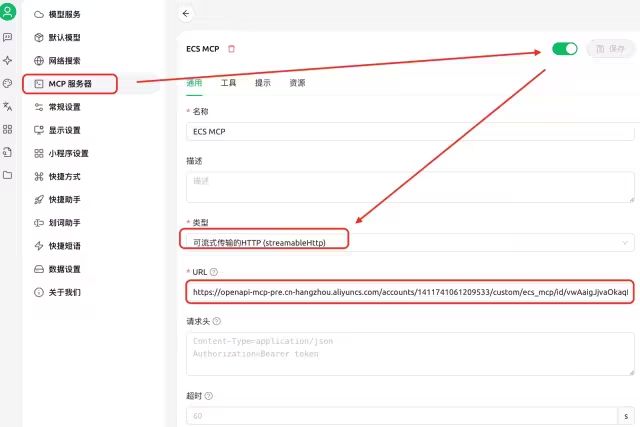
图2. 在CherryStudio里配置MCP Server
当右上角的按钮变成绿色,整个配置就结束了。看,就是这么快。
备注:1、CherryStudio需要大模型API Key,建议到百炼申请;2、第一次使用会跳出一个授权对话框,选择同意即可。
1.2 如何使用
我们选择大模型为“qwen-max",选上MCP服务,在对话框里询问LLM关于云产品相关问题,这里可以看到LLM的调用工具情况。
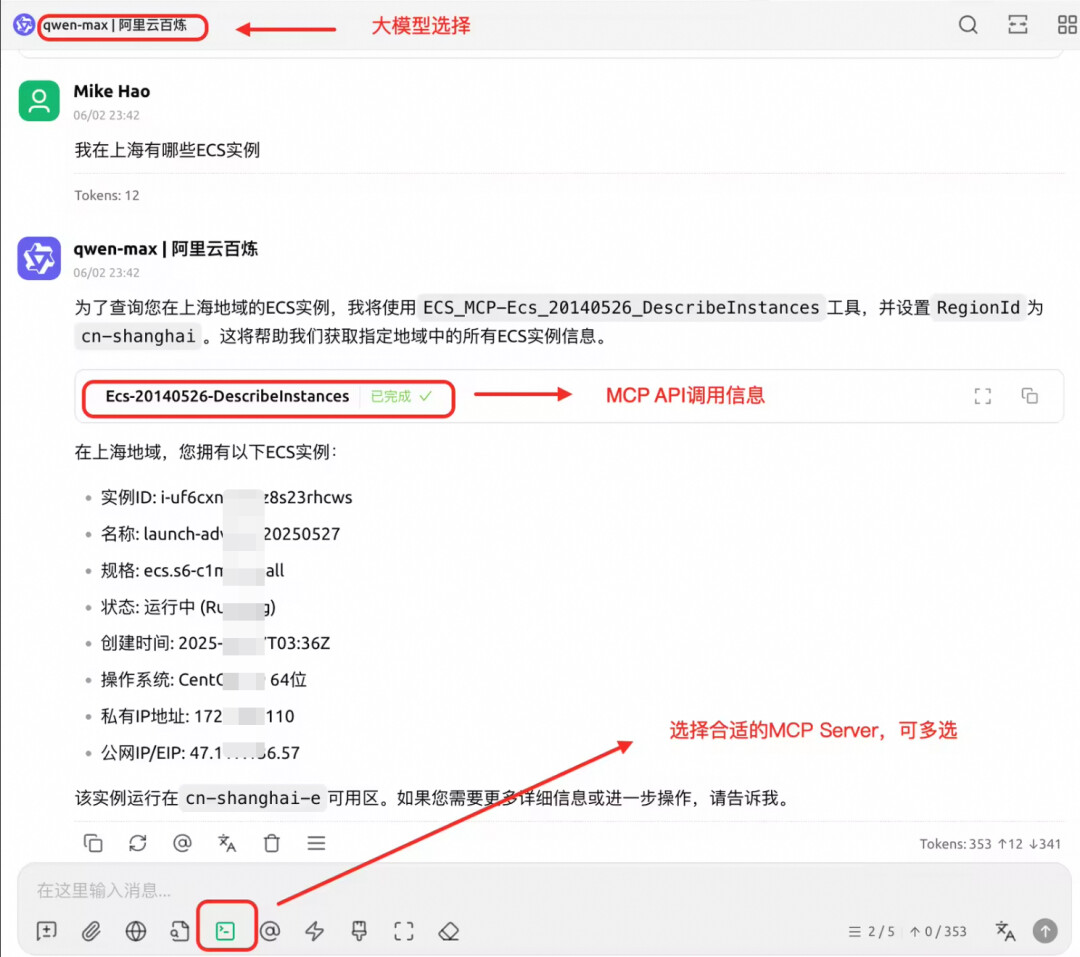
图3. 在CherryStudio查询云产品情况
1.3 有些什么问题
使用中还是不少问题的,比如要频繁选择不同MCP Server、大模型响应慢(qwen3-235b-a22b、max使用效果比较好),其中最主要的问题是下面这个:
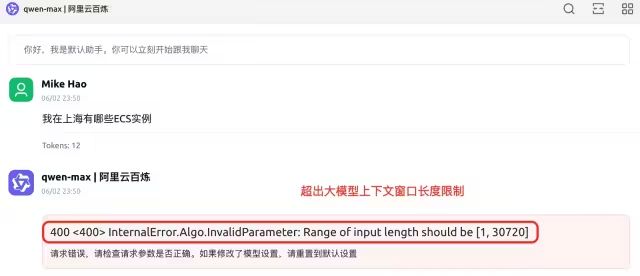
图4. 由于超出大模型上下文窗口长度限制而报错
为了解决这个问题,我们只能在设置里手工disable此次询问可能不需要的工具,之后大模型又能正确工作了。
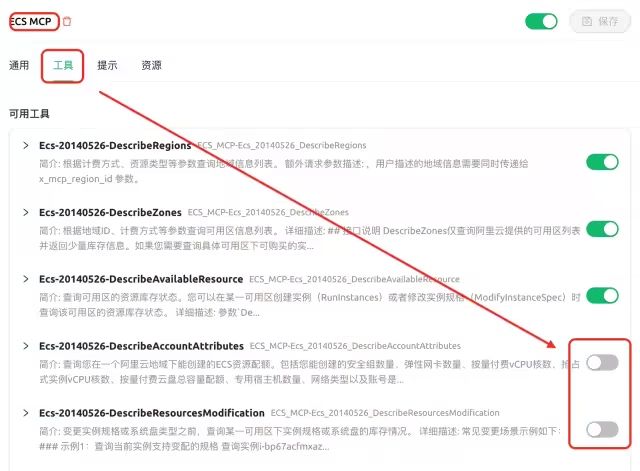
图5. 设置中取消部分API以减少上下文长度
大家看到这里是不是都会心里凉了一把,“这也太麻烦了,我还得提前根据客户问什么再看选什么API列表,这么折腾谁用啊”。实话说,我当时也是这么想的。到了这里我觉得更有必要去细致研究一下,探究内部原理到底是啥。
提前说一句,本文第三章给出一种通用解决方案、可以有效解决该问题,请大家继续往下看:-)。
二、原理探究
这里以Qwen-max、Agno(本文称为LLM框架,也是MCP Host)、ECS OpenAPI MCP Server为例进行梳理。
Agno框架已有27.6K star(对比LangGraph 13.4k),不限所用模型,运行速度快。
2.1 基础背景
以下四条是理解原理的基础背景,我们会以这些原则来理解后续一系列动作。
1、大模型是无状态、无记忆的:除非有内部偏好或记忆设置,各家大模型基本上都是无状态的,也只有这样才能撑起高并发;
2、关注同一个会话里的上下文:在浏览器的对话窗口里,每次会话都会把对话历史信息再发给大模型(根据模型上下文长度限制进行滑动截取),原因也是第一条。在框架里为了灵活控制,一般由用户来选择是否把历史信息发给大模型;
3、框架会做很多事:为了方便用户使用,框架会做很多事情,有些暴露给客户,有些则内部处理而不通知客户,如果不看源码和帮助文档,框架的行为将是一个黑盒;
4、Agent就是“专家”:只要是围绕着LLM组织起来、具备某种专项能力的,就是Agent,也可以理解为专家。Agent的实现形式,可以是简单地定制一个SystemPrompt,也可以是使用WorkFlow、Memory、RAG等复杂组件来实现。从这个角度看,框架(LangChain、Agno等)也是AI Agent。
2.2 整体框架
这里的Host可以是Agno框架,也可以是CherryStudio应用。
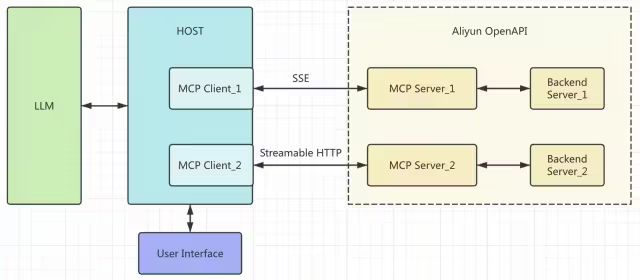
图6. MCP整体框架
简要说明:
1)Host会采用1:1的方式创建MCP Client,与远端MCP Server建连,可选SSE或Streamable http两种方式,建议优选Streamable http,因为其性能高、资源消耗低;
2)Host通过MCP协议拿到所有Tools(也就是API),发送给LLM供选择;
3)LLM根据用户提问选择相关工具,将信息发给Host,Host调用MCP服务后返回响应;
4)当所需工具调用完,LLM会综合分析结果,然后由Host反馈给到用户。
通过上图我们可以看到,MCP Server基本上起一个代理的做用,也可以看做是MCP协议的卸载点。因此,如果MCP Server本身比较轻量、主要由后端提供服务的话,它完全可以做得很轻,甚至集成到AI网关里。
需要说明的是,OpenAPI MCP Server都是远程连接的,而MCP Client本身也支持本地连接(采用STDIO模式),这种情况下MCP Server运行在本地,一般会运行Node.js(使用npx命令,下载到本地后运行)或Python(使用uv命令,也是下载到本地后运行)。具体可参考本文文末的参考资料。
2.3 交互流程
这里以Agno的视角来看具体交互流程,其他框架类似。
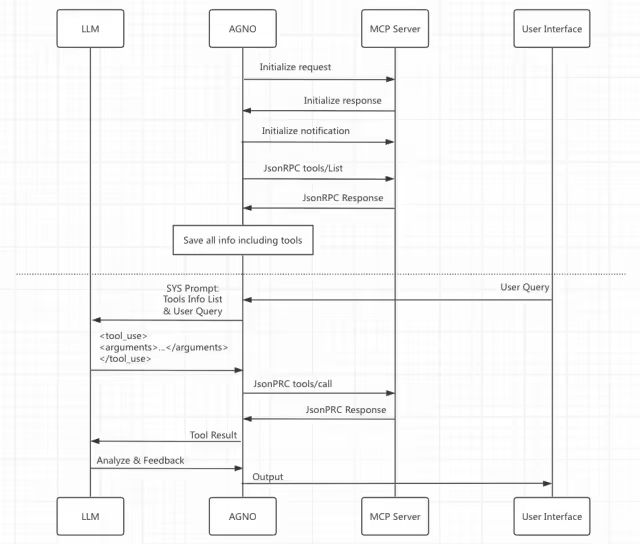
图7. MCP交互流程
简要说明:
1)Agno根据MCP Server个数建立相应个数的MCP Client,使用JsonRPC方式与MCP Server交互;
2)初始化完成后,通过tools/list获得Server提供的所有工具列表;
3)当客户发来查询请求时,Host将所有工具信息放在SystemPrompt、连同用户请求一起发给LLM;
4)LLM判断需要调用工具时,发送<tool_use>给Agno,Agno据此调用tools/call来返回响应;
5)整个交互过程中,根据用户配置来显示调用信息,返回最终的LLM输出信息。
2.4 MCP Inspector
MCP官网提供了一个Node工具,可以很方便地本地运行这个工具来对MCP Server进行验证。
-
使用方式:本地窗口运行“npx @modelcontextprotocol/inspector”,该命令会从远端拉取服务并在本地运行,通过浏览器打开“Http://127.0.0.1:6274”来使用。
-
典型使用:
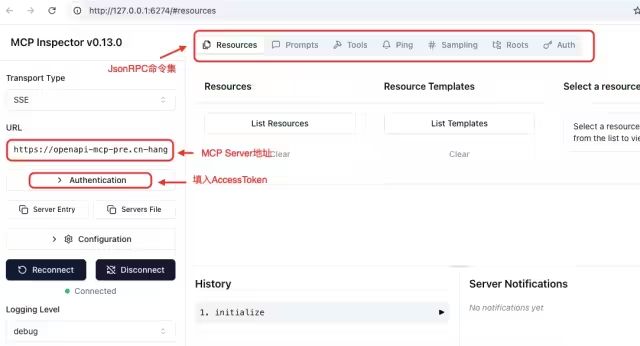
图8. Inspector配置
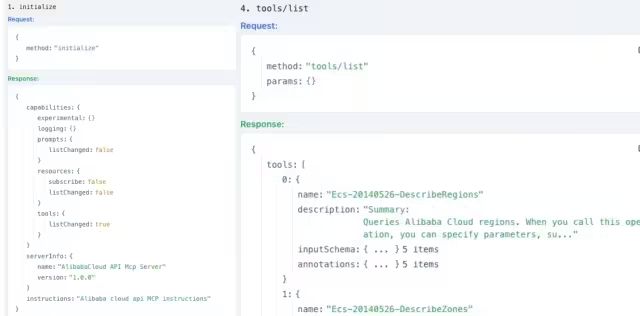
图9. Initialize和tools/list命令及响应
三、代码验证
以下代码均在本地Mac中调试通过,如需移植到其他平台(如ECS)需要提工单申请配置OAuth CallBack路径。
3.1 OAuth2.0授权
首先,按照OAuth标准的“Metadata Discovery”方式,通过在MCP Server地址拼接".well-known/oauth-authorization-server"来获得OAuth服务器信息:
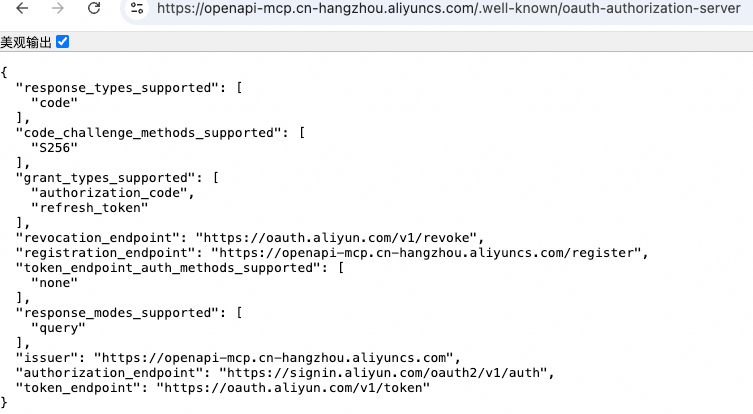
图10. OAuth服务器元数据信息
接着,使用PKCE方式来获取AccessToken,注意这里的ClientID可使用预先定义的ID,若无则需重新注册一下:
from utility import set_keyapp = Flask(name)
app.secret_key = secrets.token_urlsafe(16)CLIENT_ID = “40711518457*******”
REDIRECT_URI = “http://127.0.0.1:5000/oauth/callback”DISCOVERY_URL = “https://openapi-mcp.cn-hangzhou.aliyuncs.com/.well-known/oauth-authorization-server”
def fetch_discovery_info():
“”“从 discovery url 获取 Oauth 端点信息”“”
try:
resp = requests.get(DISCOVERY_URL, timeout=5)
if resp.status_code == 200:
data = resp.json()
return {
“authorization_endpoint”: data.get(“authorization_endpoint”),
“token_endpoint”: data.get(“token_endpoint”),
“registration_endpoint”: data.get(“registration_endpoint”)
}
except Exception as e:
print(f"Failed to fetch discovery info: {e}")
return {}默认端点
AUTHORIZATION_ENDPOINT = “https://signin.aliyun.com/oauth2/v1/auth”
TOKEN_ENDPOINT = “https://oauth.aliyun.com/v1/token”def generate_pkce():
“”“生成 PKCE 的 code_verifier 和 code_challenge”“”
code_verifier = base64.urlsafe_b64encode(secrets.token_bytes(32)).decode().rstrip(“=”)
# 计算 S256 code_challenge
digest = hashlib.sha256(code_verifier.encode()).digest()
code_challenge = base64.urlsafe_b64encode(digest).decode().rstrip(“=”)
return code_verifier, code_challenge@app.route(“/”)
def home():
return’<a href=“/login”>Login with OAuth</a>’@app.route(“/login”)
def login():
registration_endpoint = “”
# 尝试用 discovery 信息覆盖端点
discovery = fetch_discovery_info()
print(f"Discovery info: {discovery}“)
if discovery.get(“authorization_endpoint”):
AUTHORIZATION_ENDPOINT = discovery[“authorization_endpoint”]
if discovery.get(“token_endpoint”):
TOKEN_ENDPOINT = discovery[“token_endpoint”]
if discovery.get(“registration_endpoint”):
registration_endpoint = discovery[“registration_endpoint”]
# 注册一个 client(如果 CLIENT_ID 未设置或为占位符)
client_id = CLIENT_ID
if (not client_id) or client_id.endswith(”*******“):
ifnot registration_endpoint:
return"Registration endpoint not available”, 400
# 注册 client
reg_data = {
“redirect_uris”: [REDIRECT_URI],
“grant_types”: [“authorization_code”],
“response_types”: [“code”],
}
try:
reg_resp = requests.post(registration_endpoint, json=reg_data, timeout=5)
if reg_resp.status_code != 201:
return f"Client registration failed: {reg_resp.text}“, 400
reg_json = reg_resp.json()
client_id = reg_json.get(“client_id”)
ifnot client_id:
return"No client_id returned from registration”, 400
session[“client_id”] = client_id
except Exception as e:
return f"Client registration exception: {e}", 400
else:
session[“client_id”] = client_id# 生成 PKCE 参数
code_verifier, code_challenge = generate_pkce()
# 生成随机 state 防止 CSRF
state = secrets.token_urlsafe(16)
# 保存到 session
session.update({
“code_verifier”: code_verifier,
“state”: state
})
# 构造授权请求 URL
params = {
“response_type”: “code”,
“client_id”: session[“client_id”],
“redirect_uri”: REDIRECT_URI,
“code_challenge”: code_challenge,
“code_challenge_method”: “S256”,
“state”: state
}
auth_url = f"{AUTHORIZATION_ENDPOINT}?{urllib.parse.urlencode(params)}"
return redirect(auth_url)@app.route(“/oauth/callback”)
def callback():
# 检查错误响应
if"error" in request.args:
return f"Error: {request.args[‘error’]}"
# 验证 state
if request.args.get(“state”) != session.get(“state”):
return"Invalid state parameter", 400
# 获取授权码
auth_code = request.args.get(“amp;code”) or request.args.get(‘code’) # 尝试两种可能的参数名
ifnot auth_code:
return"Missing authorization code", 400
# 用授权码换取 token
data = {
“grant_type”: “authorization_code”,
“code”: auth_code,
“redirect_uri”: REDIRECT_URI,
“client_id”: session.get(“client_id”, CLIENT_ID),
“code_verifier”: session[“code_verifier”]
}
response = requests.post(TOKEN_ENDPOINT, data=data)
if response.status_code != 200:
return f"Token request failed: {response.text}“, 400
token_info = response.json().get(“access_token”)
# 存储到本地配置文件
print(f"Your access_token: {token_info}”)
set_key(“ALI_OPENAPI_ACCESS_TOKEN”, token_info)# 删掉session参数
session.pop(“code_verifier”, None)
session.pop(“state”, None)
return response.json()
if name == “main”:
app.run(port=5000, debug=True)
最后,在已经登录阿里云账号的状态下使用浏览器访问“http://127.0.0.1:5000”来获取access_token,将此token存入到本地配置文件中。与1.1节里CherryStudio在弹出的界面里要求授权一样,两者的目的都是为获得access_token,这个token将在下次访问MCP Server时配置在Heard中的Authorization中,其格式为{'Authorization': f'Bearer {access_token}'}。类似的,在2.4节中的MCP Inspector中也要配置此项。
说明:1)access_token默认有效时长259199s(3天),在失效前建议使用refresh_token来请求更新access_token;2)官方Python SDK的MCP Client也支持OAuth鉴权,读者可参照说明自行实现。
3.2 第一个MCP应用
拿到access_token后,我们就可以实现这个应用:
print(f"Current path is {os.getcwd()}") load_keys()async def run_agent(message: str) -> None:
server_params = StreamableHTTPClientParams(
url = "https://openapi-mcp.cn-hangzhou.aliyuncs.com/accounts/1411741061209533/custom/ecs_tst_agno/id/RXPfhaBVHq7w3wkp/mcp, # ECS
headers = {‘Authorization’: f’Bearer {os.getenv(“ALI_OPENAPI_ACCESS_TOKEN”)}'}
)async with MCPTools(server_params=server_params, transport=“streamable-http”, timeout_seconds=30 ) as mcp_tools:
# Initialize the model
model=OpenAILike(id=“qwen-max”,
api_key=os.getenv(“DASHSCOPE_API_KEY”),
base_url=“https://dashscope.aliyuncs.com/compatible-mode/v1”)
# Initialize the agent
agent = Agent(model=model,
tools=[mcp_tools],
instructions=dedent(“”"
你是一个阿里云云计算专家,请根据用户的问题,使用MCP服务查询阿里云的云产品信息,给出详细的解释。
请使用中文回答
“”"),
markdown=True,
show_tool_calls=True)# Run the agent
await agent.aprint_response(message, stream=True)Example usage
if name == “main”:
asyncio.run(run_agent(“我在上海有哪些ECS实例?”))
程序运行结果如下:
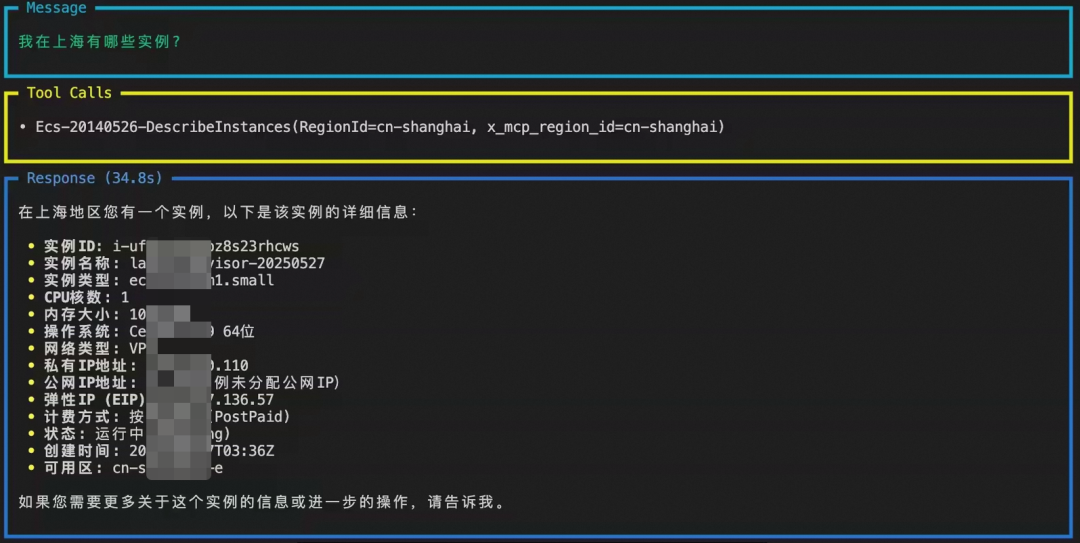
图11. MCP应用运行结果
说明:1)Agno框架的mcp.py的174行有bug,先使用“client_timeout = self.timeout_seconds”来跳过;2)运行时会报错“JSONRPCRequest.method. Field required [type=missing, input_value={'result': 'ok'}”,这个主要与Server端实现有关,内部已排期修复。不影响正常使用。
3.3 解决"Input length ouf of range"
1.3节中我们使用的ECS MCP Server有26个工具,在使用全量工具集、模型为Qwen-max的时候CherryStudio会报“超出上下文长度限制”的错误。在Agno中,报错类似:

图12. Agno报错上下文长度超限
由2.3的交互流程可以发现,上下文超标主要是因为tools集合数据太多导致。进一步观察后,发现每个tool由name、description、inputSchema、annotaions四部分组成,其中inputSchema的占用量最大。为此,我们可以让LLM先根据全集列表中的name、description判断一把,告诉我们需要哪些tool,然后再配置LLM,这样便能有效减少上下文长度。具体流程如下:

图13. 预筛选-调用流程
代码实现如下:
1)使用mcp client 获取全量tools信息,然后由LLM根据用户请求判断要哪些工具。注意这里的提示词里要明确说明不能返回"```"、"json"等字符串,不然无法进行格式化。
def get_selected_tools_list(server_url, hearders, llm_api_key, user_question): from mcp.client.streamable_http import streamablehttp_client from mcp import ClientSession import asyncio from agno.agent import Agent, RunResponse from agno.models.openai.like import OpenAILike import json # Important: Just to avoid such logging error like "JSONRPCError.jsonrpc Field required ... import logging logging.disable(logging.CRITICAL) # 1. Get all tools via tools/list all_tools = None async def get_all_tools(): # Connect to a streamable HTTP server async with streamablehttp_client(url=server_url,headers=hearders)as(read_stream, write_stream,_): # Create a session using the client streams async with ClientSession(read_stream, write_stream) as session: await session.initialize() all_tools = await session.list_tools() print(f"Number of tools: {len(all_tools.tools)}") return all_tools all_tools = asyncio.run(get_all_tools()) # 2. Collect all tools brief info brife_tools_info = [ { "name": tool.name, "description": tool.description, } for tool in all_tools.tools] # 3. Create an agent simple_agent = Agent( model=OpenAILike( id="qwen-max", api_key=llm_api_key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ), system_message=""" 你是一个云计算专家,严格按照请客户提供的上下文信息回答问题。 """, ) # 4. Run the agent to tell us which tools are needed for user questio prompt = ( f"请根据提供的工具信息以及用户请求,你需要给出可能需要调用的api列表,以Json形式返回,要精简、不需要其他信息。格式上,返回值不带```、json等字符串," f"工具信息如下:{json.dumps(brife_tools_info)}," f"现在客户提问:{user_question}" ) response: RunResponse = simple_agent.run(prompt) print(response.content) tool_to_use_list = json.loads(response.content) print(f"Selected Tool List: {tool_to_use_list}") return tool_to_use_list
2)MCPTools构造时加入白名单(include_tools=config["tool_to_use_list"]),只有白名单上的tool可以被调取,然后正式发起查询。
print(f"Current path is {os.getcwd()}") load_keys()async def run_agent(config):
# Setup agent with MCP tools
server_params = StreamableHTTPClientParams(url=config[“server_url”], headers=config[“headers”])
async with MCPTools(server_params=server_params,
transport=“streamable-http”,
timeout_seconds=30,
include_tools=config[“tool_to_use_list”]) as mcp_tools:
# Initialize the model
model=OpenAILike(id=“qwen-max”,
api_key=config[“llm_api_key”],
base_url=“https://dashscope.aliyuncs.com/compatible-mode/v1”)
# Initialize the agent
agent = Agent(model=model,
tools=[mcp_tools],
instructions=dedent(“”"
你是一个阿里云云计算专家,请根据用户的问题,使用MCP服务查询阿里云的云产品信息,给出详细的解释。
请使用中文回答
“”"),
markdown=True,
show_tool_calls=True)# Run the agent
await agent.aprint_response(config[“user_question”], stream=True)Example usage
if name == “main”:
# 1. User question goes here
user_question = “我在上海有哪些ECS实例?”# 2. Prepare arguments for the agent
url = “https://openapi-mcp.cn-hangzhou.aliyuncs.com/accounts/1411741061209533/custom/ecs_mcp/id/vwAaigJjvaOkaqHf/mcp” # Full ECS List
headers = {‘Authorization’: f’Bearer {os.getenv(“ALI_OPENAPI_ACCESS_TOKEN”)}'}
llm_api_key = os.getenv(“DASHSCOPE_API_KEY”)# 3. Get selected tools list by user question
seleted_tools = get_selected_tools_list(url, headers, llm_api_key, user_question)
# print(seleted_tools)# # 4. Setup config
config = {
“server_url”: url,
“llm_api_key”: llm_api_key,
“headers”: headers,
“user_question”: user_question,
“tool_to_use_list”: seleted_tools
}
# 5. Query LLM
asyncio.run(run_agent(config))
当用户询问“我在上海有哪些ECS实例?”时,LLM判断只要一个工具(Ecs-20140526-DescribeInstances)就够了,然后再次装载MCPTools后程序运行正常,结果如下:
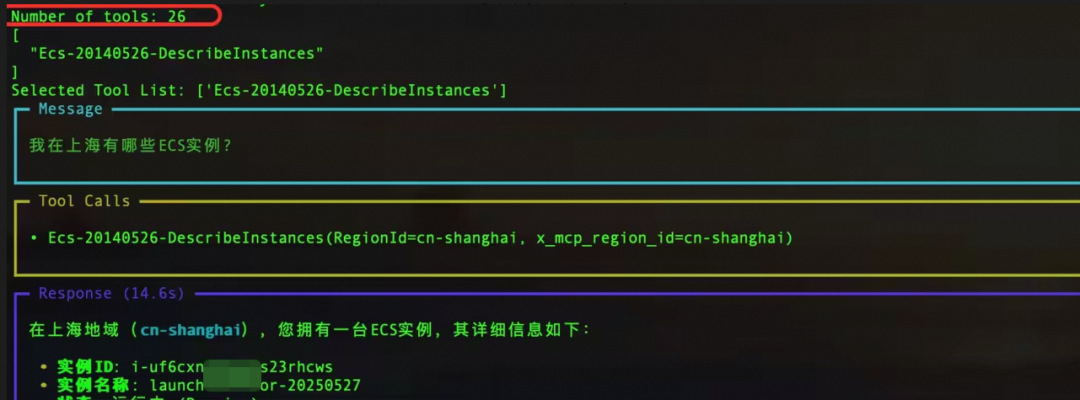
图14. 从26个tools中挑选1个来查询
3.4 后续优化
以上三个小实验只是从代码层面验证了MCP的基本功能,离真正的工程生产还相差甚远,后续将在以下方面优化:
1)将每个云产品的MCP Server按照不同维度拆分,比如按照操作类型分为Describe*、Get*、Modify*、Create/Run*等,建立不同种类的MCP Server。这样可以做到更细粒度的拆分,从源头减少Tools数量问题;
2)使用MultiMCPTools来组装多个MCP Server,使LLM可以同时使用多个Server;
3)进一步优化工具筛选,根据客户请求分析多个MCP Server,然后给出筛选建议;
4)使用图形化界面,将筛选、运行组装成一个工作流,白屏化操作;
5)对非查询类(如Create、Delete、Update)的MCP需要引入客户交互,告知客户风险,由客户确认每一步是否可以操作。
四、未来展望
开放平台现有2W多个OpenAPI,在MCP Server的帮助下这些API可以被更加灵活地利用起来,相信有非常多的实用场景会被创造出来,届时云对普通大众来说也许就是“一两句话的事儿”。
在此从个人角度地展望一下:
1、推动文档完善:LLM能否有效调用tool的关键在于文档(描述、参数说明等),只有表达更清楚、更全面才能更有利于LLM决策。这方面开放平台也允许用户自行调优;
2、控制幻觉:LLM一大优势是能帮我们补充各种细节,选工具、填参数、分析结果,可另一方面它也有幻觉,可以生成很多貌似正确的东西,且不同的模型幻觉程度也不一样,因此必须由人做最终控制和决策。当然,也可以加入另一个LLM来审核前一个LLM的动作,减轻人的工作量;
3、建立每个云产品Agent:ECS、NAS、RocketMQ等都可以建立自己的专业Agent(搭配RAG),用户只要描述需求,剩下将由专业Agent在最佳实践基础上一键搞定;
4、搭建Agent矩阵:通过A2A协议在不同的云产品间进行协作,为客户提供完整解决方案;
5、实现高度安全:制定整体安全框架,确保Agent所有行为安全、可控。
附:参考资料
1、阿里云官网 - OpenAPI MCP控制台:https://api.aliyun.com/mcp
2、Model Context Protocol:https://modelcontextprotocol.io/docs/concepts/architecture
3、MCP - Python SDK:https://github.com/modelcontextprotocol/python-sdk
4、Agno - Full-stack framework for building Multi-Agent System:https://docs.agno.com/introduction
通义千问3 + MCP:一切皆有可能
MCP 协议通过标准化交互方式解决 AI 大模型与外部数据源、工具的集成难题;通义千问3 原生支持 MCP 协议,能更精准调用工具;阿里云百炼上线了业界首个全生命周期 MCP 服务,大幅降低 Agent 开发门槛,用户只需 5 分钟即可构建增强型智能体。
点击阅读原文查看详情。