中科院&字节提出BridgeVLA,一种高效的3D视觉语言操作新范式,通过2D空间对齐实现数据效率和操作能力的飞跃,并在多项基准测试中取得领先成果。
原文标题:3D VLA新范式!中科院&字节Seed提出BridgeVLA,斩获CVPR 2025 workshop冠军!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 BridgeVLA 在长周期任务(L4)中的表现仍然有限,你认为有哪些方法可以改善模型在长周期任务中的表现?
3、BridgeVLA 在真实机器人实验中表现出较强的鲁棒性,尤其是在视觉干扰方面。你认为这种鲁棒性主要来源于哪些因素?
原文内容

只需要三条轨迹,就能取得 96.8% 的成功率?视觉干扰、任务组合等泛化场景都能轻松拿捏?或许,3D VLA 操作新范式已经到来。
当前,接收 2D 图像进行 Next Action Token 预测的「2D VLA」模型已经展现出了实现通用机器人操作的潜力;同时,接受 3D 信息作为输入,并以下一时刻的关键帧作为输出的「3D 操作策略」已被证明拥有极高的数据效率(≈10 条操作轨迹)。
那么,直觉上来讲,一个好的「3D VLA」模型应该能够综合以上的优点,兼具 efficient 和 effective 的特点。然而,当前 3D VLA 的模型设计并未实现上述期待。
为了解决上述问题,中科院自动化所谭铁牛团队联合字节跳动 Seed 推出 BridgeVLA,展示了一种全新的 3D VLA 范式,实现了模型能力与数据效率的同步飞跃,并斩获了 CVPR 2025 GRAIL workshop 的 COLOSSEUM Challenge 冠军。目前代码与数据已经全面开源。

-
论文标题:BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
-
论文链接:https://arxiv.org/abs/2506.07961
-
项目主页:https://bridgevla.github.io/
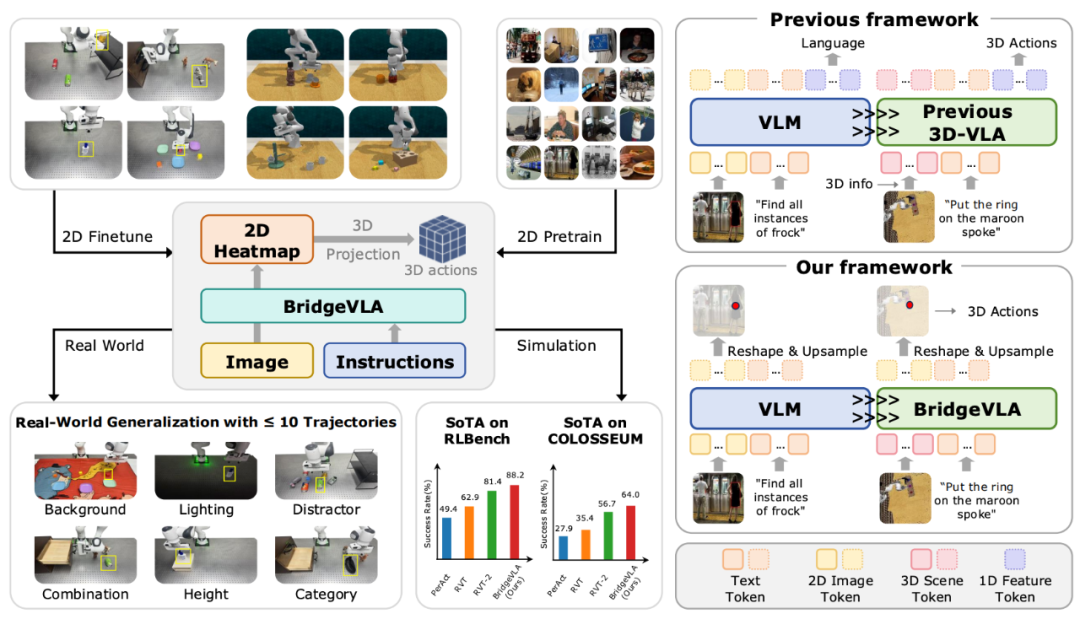
出发点:对齐 VLM 与 VLA
BridgeVLA 的核心理念是将预训练和微调的输入输出对齐到统一的 2D 空间,从而「bridge」VLM 和 VLA 之间的 gap。从这个理念出发,作者认为不应该使用传统 3D VLA 的 3D 位置编码或 3D 信息注入,而是将 VLA 输入与 VLM 对齐,即仅输入图片和文字指令。
同时,作者将模型的输出方式从 Next token prediction 变更为 Heatmap prediction,通过这种方式,将输出从无空间结构的 token 变成有空间结构的 2D Heatmap,既能充分利用 3D 空间结构先验,又能将模型的输入输出进一步在 2D 空间中对齐。
预训练:赋予 VLM 预测 2D Heatmap 的能力
在使用机器人数据进行微调之前,需要先通过预训练以赋予 VLM 目标检测的能力。为此,作者提出了一种新颖的可扩展预训练方法:给模型输入图片-目标文本对,并提取模型的输出中对应图像的 token,再将这部分图像 token 进行重新排列作为图像的隐藏状态,最后,通过可学习的凸上采样方法将其还原成与输入图片相同大小的 Heatmap。通过交叉熵损失监督训练模型,使其具有 Heatmap 预测的能力。通过这个 Heapmap 即可获取被操作的目标物体的像素位置。
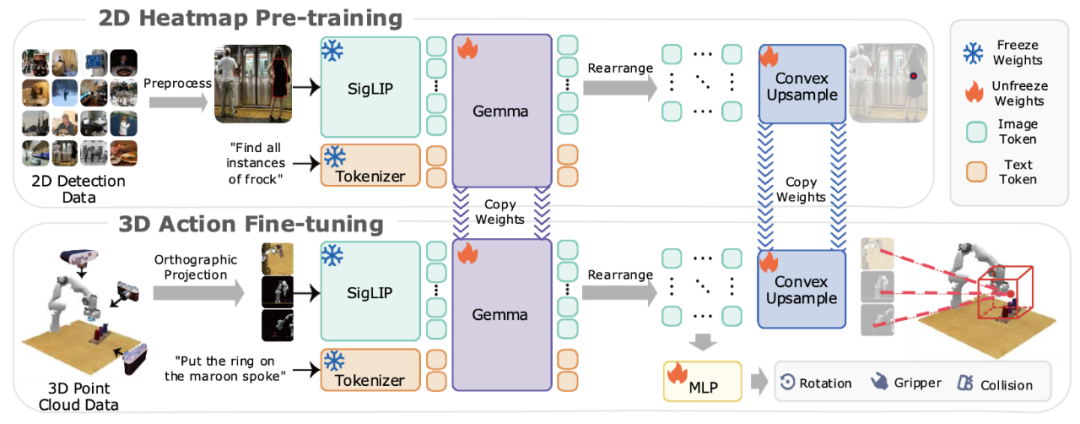
微调:赋予模型预测 Action 的能力
与 RVT、RVT-2 等典型的 3D 操作策略类似,BridgeVLA 通过预测关键点来得到下一时刻的动作。具体来说,BridgeVLA 采用场景的点云和指令文本作为原始输入。但为了将微调过程的输入与预训练的输入进行对齐,作者将点云从正面、上面、右侧这三个方向进行正交投影,产生 3 张 2D 图像输入给模型。模型采用与预训练相同的方式输出 Heatmap 后,通过将 3 个 Heatmap 进行反投影,进而估计 3D 空间内所有结构化网格点的分数,并选用得分最高的点作为机械臂末端执行器的平移目标。对于旋转、夹持器状态以及碰撞检测,BridgeVLA 将提取到的全局特征和局部特征进行拼接,然后输入给 MLP 进行预测。
此外,BridgeVLA 沿用了由粗到细(Coarse-to-fine)的多级预测方式,通过对首次 Heatmap 预测的目标位置附近的点云进行放大和裁剪,并在裁剪后的点云上进行第二次前向传播,从而获得更加精细的位置预测。
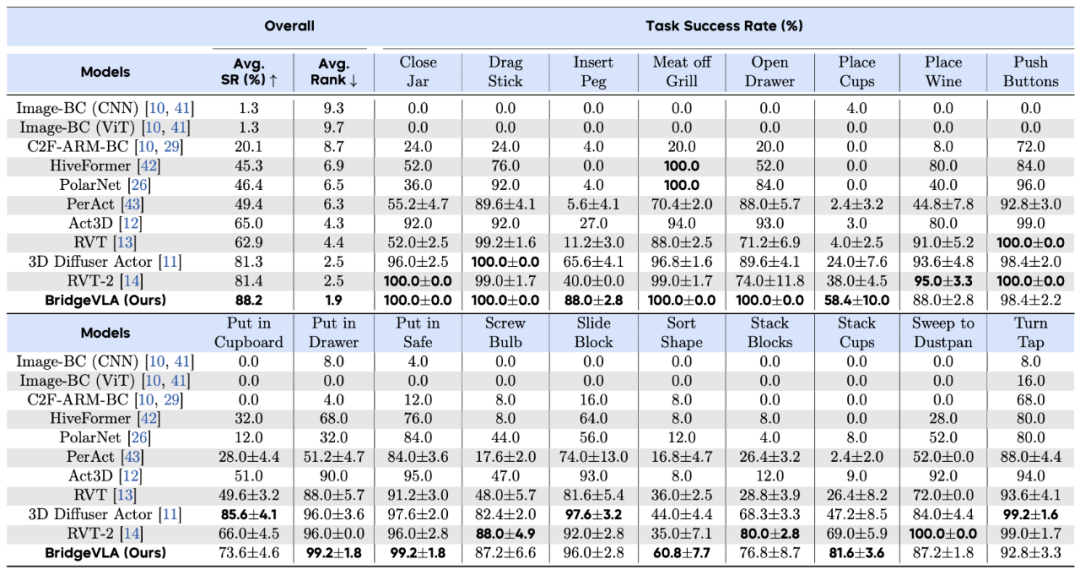
仿真实验:屠榜三项主流 3D 操作任务基准
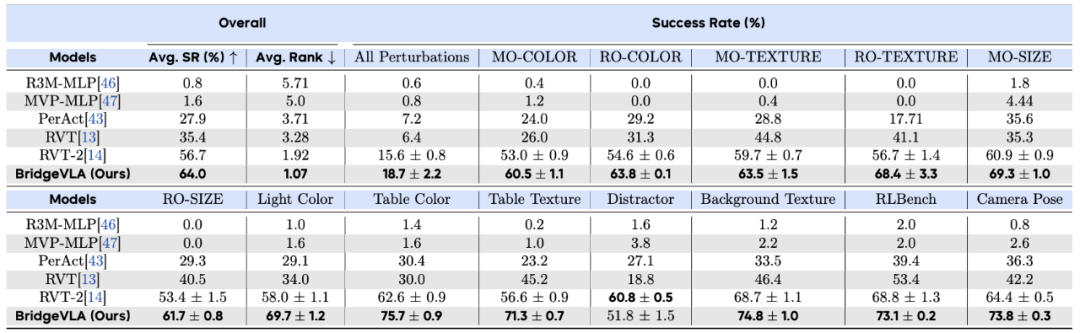
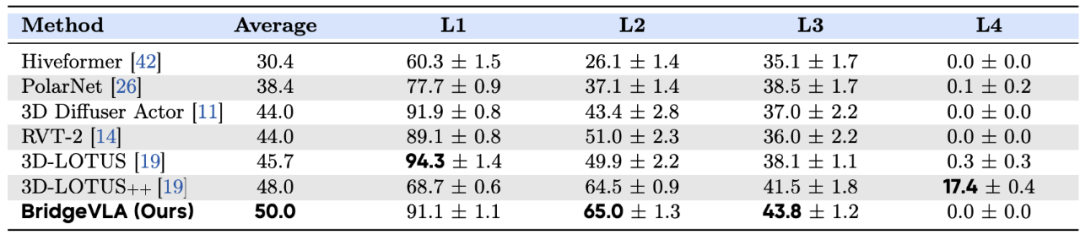
真实机器人实验:远超现有 Baseline
在真实世界评测中,作者设计了 13 个基本任务,并设计了 6 种不同的泛化性能测试(包括干扰物体、光照、背景、高度、组合和类别)以全面评估模型性能。如图所示,BridgeVLA 在七种设置中的六种中均优于最先进的基线方法 RVT-2。
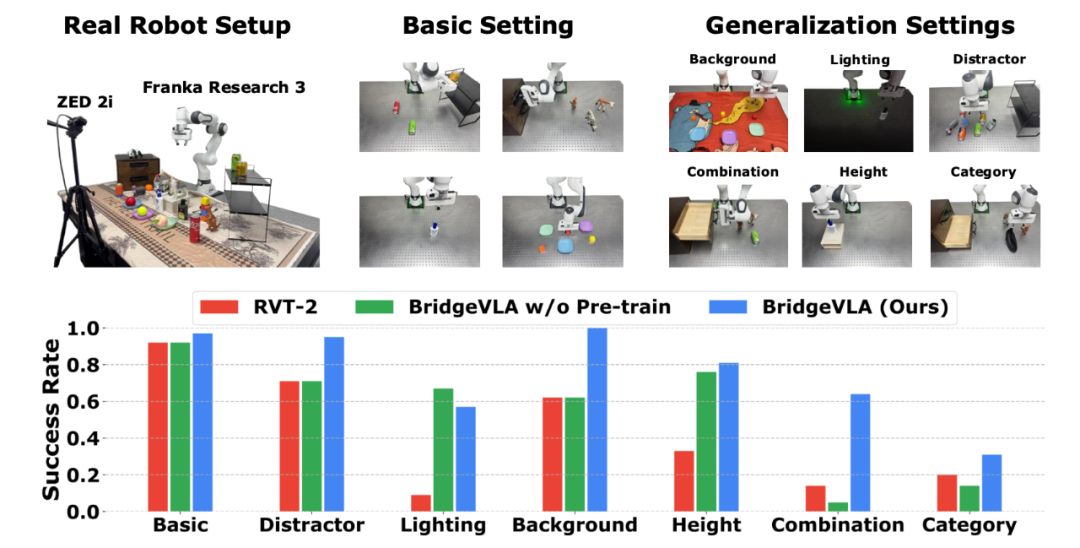
在四种视觉干扰设置中,BridgeVLA 表现出十分显著的鲁棒性,尤其在干扰物和背景变换的设置中,其仍然能够保持超高成功率。此外,作者还发现 2D 热图预训练对于模型理解语言语义和泛化到新的对象-技能组合至关重要。同时,即使在经过机器人动作数据微调后,模型仍能很好地对预训练数据进行预测,证明预训练知识被成功地保留了下来。
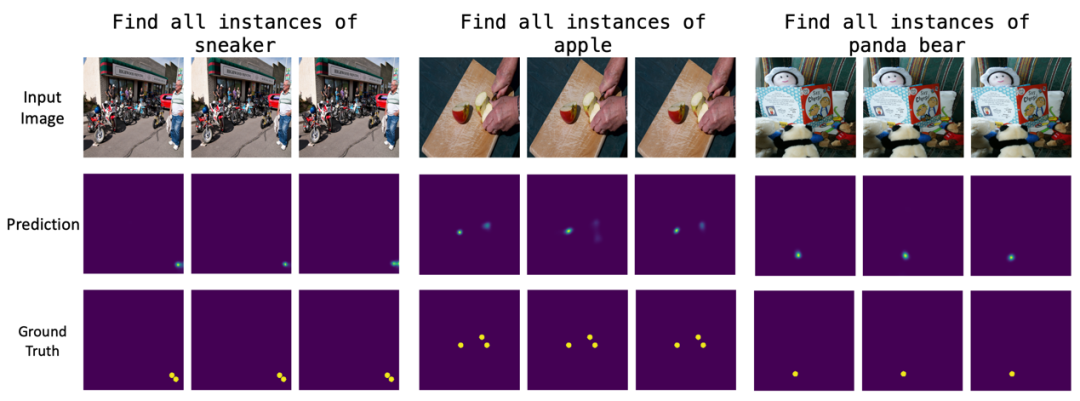
总结和展望
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com