本文解析了模型上下文协议(MCP)的概念、演进与实践,对比了MCP与RAG架构的差异,并概括了MCP的核心能力,旨在帮助开发者更好理解和应用。
原文标题:独家|MCP实践指南:从理解原理到实践应用(上)
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章将MCP比作AI应用的“USB-C接口”,你觉得这个比喻恰当吗?还有没有其他的比喻可以更形象地描述MCP的作用?
3、文章提到了MCP的三种核心能力:Resources、Tools和Prompts,你认为哪一种能力在实际应用中最为关键?为什么?
原文内容

翻译:夏舒淇校对:赵茹萱
本文约4400字,建议阅读10+分钟
曾经我不明白为何AI助手需要MCP服务器——直到我读到了这篇指南。
本文将分为上下两篇,本文为上篇。
上篇目录
1.引言:我为什么写这篇文章
2.LLM工具集成的演变
3.什么是模型上下文协议(MCP)?
4.等等,MCP 听起来像RAG……但真的是吗?
4.1在基于MCP的系统中
4.2在传统的RAG 系统中
4.3传统RAG的实现方式
4.4 MCP的实现方式
5.快速回顾!
6.MCP服务器的核心能力
下篇目录
7.真实案例:Claude Desktop + MCP(预构建服务器)
8.自己动手:从零构建自定义MCP服务器
9.恭喜,你已经掌握了MCP!
10.参考文献
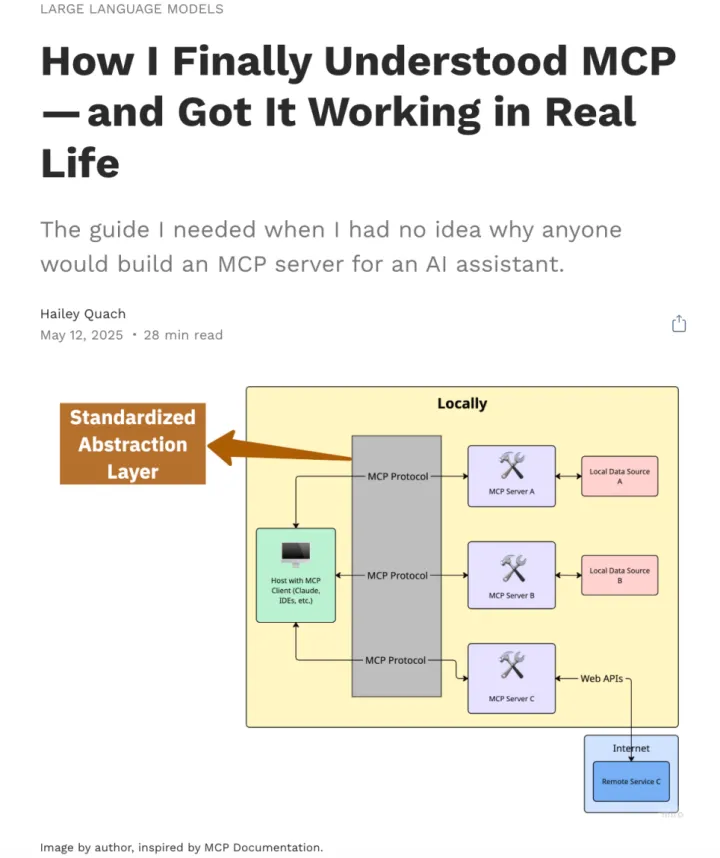
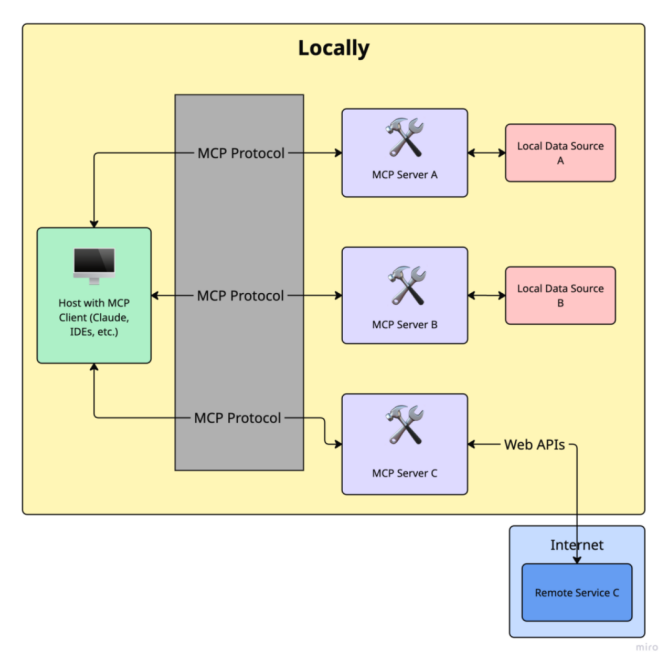
1. 引言:我为什么写这篇文章
实不相瞒。第一次看到“模型上下文协议”(Model Context Protocol,简称 MCP)这个术语时,我和大多数开发者一样:随便扫了一眼教程,然后就默默跳过了。我当时心想:“太抽象了”。
但后来,当我尝试将一些自定义工具集成到Claude Desktop 中——比如需要内存或访问外部工具的那种——,突然间,MCP 突然变成了关键所在。
问题是:我找到的那些教程对初学者一点都不友好。大多数一上来就讲“如何构建一个自定义 MCP 服务器”,完全没解释你为什么一开始就需要一个服务器——而且,事实上,市面上已经有现成的MCP 服务器可以直接拿来使用。
所以,我决定从头开始学习MCP。
我尽可能地阅读资料,动手试验了预构建的和自定义的MCP 服务器,把它们集成进 Claude Desktop,并尝试把它讲给我的没有任何MCP基础的朋友。如果他们也听懂并认可了,那么任何人都能理解MCP,哪怕他是五分钟前才第一次听说MCP。
这篇文章将帮你拆解:MCP到底是什么?它为什么重要?它和像 RAG 这样的流行架构有什么不同?我们会从“这到底是什么?”一路走到“自己搭建一个能跑的 Claude 集成”——你完全不需要 MCP 的预备知识。如果你曾为 AI 模型的上下文能力太差而苦恼,那这篇文章你一定得看看。
2. LLM 工具集成的演变
在深入了解MCP 之前,让我们先回顾一下将大语言模型(LLMs)与外部工具和数据连接的演进过程:
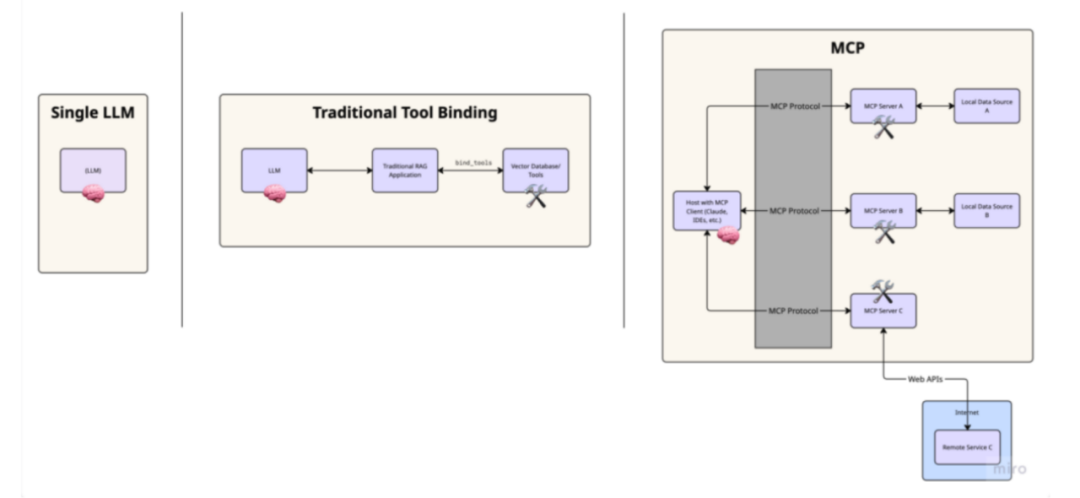
独立运行的LLM:最初,像GPT 和 Claude 这样的模型是“孤立运行”的,只能依赖其训练时的数据。它们无法访问实时信息,也无法与外部系统交互。
工具绑定:随着LLM 的发展,开发者开始设计方法,将工具直接“绑定”到模型上。例如,使用 LangChain 或类似框架,你可以实现“额外”的功能:
llm = ChatAnthropic()
augmented_llm = llm.bind_tools([search_tool, calculator_tool])
这种方式在处理单个脚本时效果不错,但在多个应用之间扩展起来就不那么容易了。因为像LangChain 这样的框架中的工具绑定,通常是围绕单会话、无状态的交互设计的。也就是说,每次你启动一个新的代理或函数调用时,往往都需要重新定义它可以访问哪些工具。没有一种集中式的方法可以在多个界面或用户上下文之间统一管理工具。
应用集成的挑战:当你想要把各种工具集成到AI 驱动的应用中时,比如代码编辑器(如 Cursor、VS Code)、聊天界面(如 Claude Desktop)或其他生产力工具。每个应用都需要为各种可能的工具或数据源构建自定义连接器,从而形成一个错综复杂的集成网络。
这正是MCP 的意义——它提供了一个标准化的抽象层,将AI 应用与外部工具和数据源连接起来。
3. 什么是模型上下文协议(MCP)?
我们来逐步拆解这个概念:
Model(模型):指的是你应用中的核心LLM,比如 GPT、Claude 等。它是一个强大的推理引擎,但模型常常会受限于它的训练数据以及它所能容纳的上下文信息。
Context(上下文):指的是模型完成任务所需的额外信息,比如文档、搜索结果、用户偏好、最近的交互历史等。上下文能够将模型的能力扩展到训练数据之外。
Protocol(协议):一种标准化的组件间通信方式。你可以把它理解为一种通用语言,让你的模型可以以可预测的方式与工具和数据源进行交互。
把这三者结合起来,MCP就是一个将模型与上下文信息及工具连接起来的框架,它通过一种一致、模块化、可互操作的接口实现这些连接。
就像HTTP 通过标准化浏览器与服务器之间的通信方式推动了 Web 的发展一样,MCP 正在标准化 AI 应用如何与外部数据和功能交互。
专家提示!
简单理解,可以把MCP想象成:面向整个AI 技术栈的“工具绑定”机制,而不仅仅是针对某一个代理(agent)。
这也正是为什么Anthropic 会把 MCP 形容为:“AI 应用的 USB-C 接口。”
就像USB-C 可以统一连接各种设备,MCP 也为 AI 应用提供了一种统一、标准化的方式来连接各种工具与数据源。
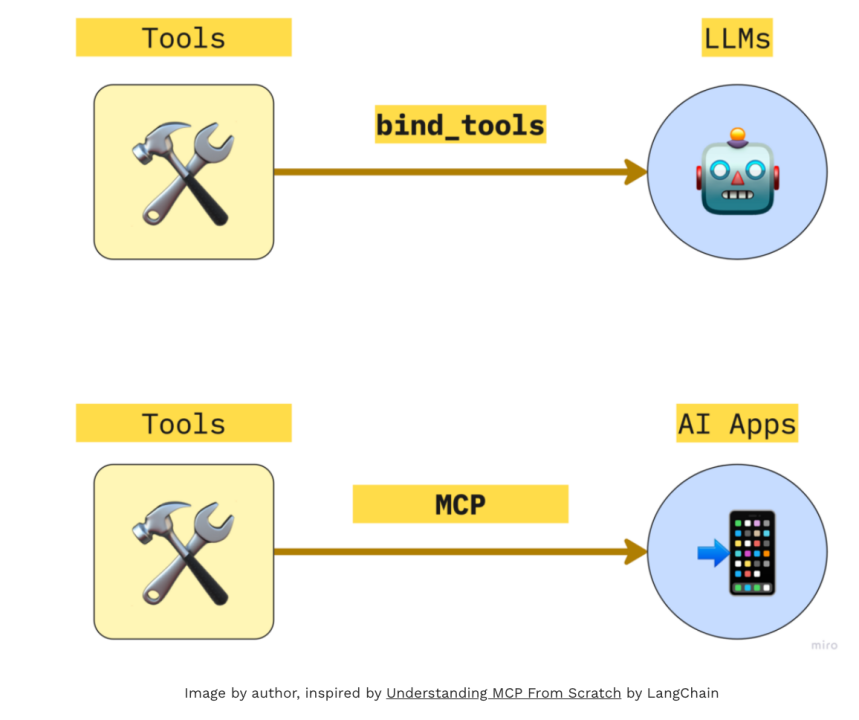
4. 等等,MCP 听起来像 RAG……但真的是吗?
很多人会问:“MCP和RAG 有什么不同?”这是个非常好的问题。
乍一看,MCP 和 RAG 的目标确实相同:让语言模型能够访问相关的外部信息。但它们的实现方式——以及维护的便利程度——却有着显著差异。
在基于MCP的系统中:
-
你的AI 应用(作为主机或客户端)连接到一个 MCP 文档服务器。
-
你通过一个标准化协议与上下文交互。
-
你可以在无需修改应用本身的前提下添加新的文档或工具。
-
所有功能都通过一致的接口实现,行为统一、稳定可靠。
在传统的RAG系统中:
-
你的应用需要手动构建并查询向量数据库。
-
通常需要自己实现自定义的embedding 逻辑、检索器和加载器。
-
每当你想添加新的数据源时,就必须重写一部分应用代码。
-
每一次集成都像是“量身定制”,与你的应用逻辑高度耦合。
关键区别在于抽象层级:Model Context Protocol 中的 “Protocol(协议)” 本质上就是一个标准化的抽象层,它定义了MCP 客户端/主机 与 MCP 服务器之间的双向通信方式。
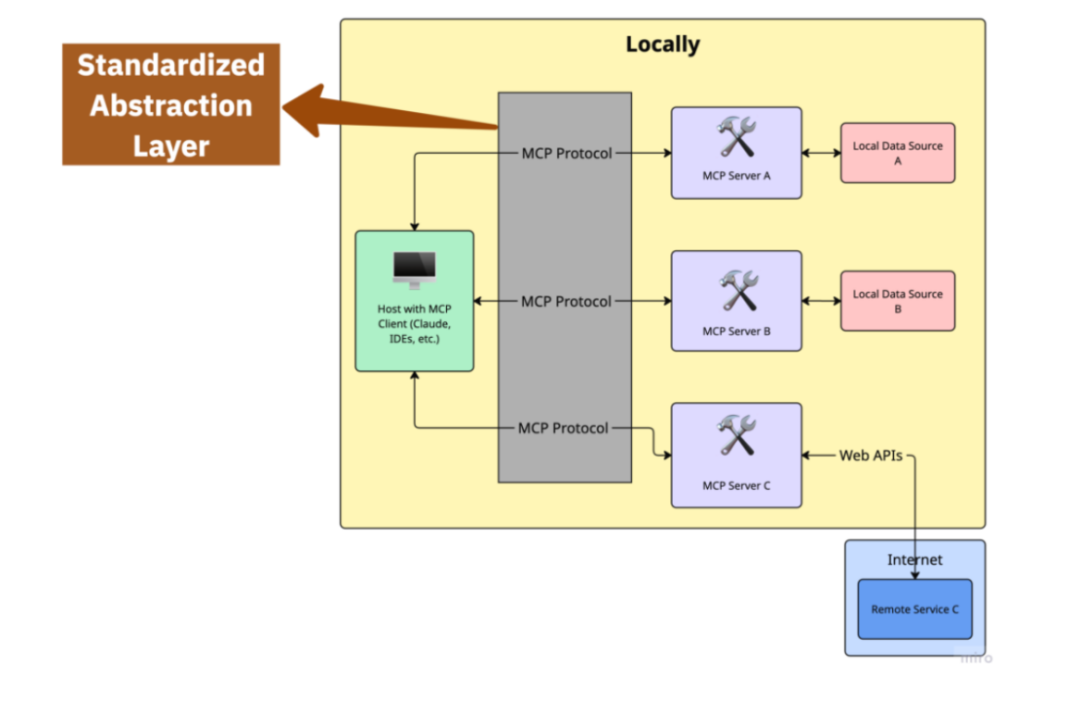
MCP赋予你的应用这样一种能力:“给我关于 X 的信息”,而无需知道这些信息是如何存储或检索的。
而在RAG 系统中,你必须由应用自身来管理这一切。
使用MCP 时,即使文档来源不断变化,你的应用逻辑也可以保持不变。
下面我们通过一些高级代码示例,来看看这两种方法之间的差异:
传统RAG 的实现方式
在传统的RAG 实现中,你的应用代码需要直接管理与文档数据源的连接:
# Hardcoded vector store logic
vectorstore = FAISS.load_local("store/embeddings")
retriever = vectorstore.as_retriever()
response = retriever.invoke("query about LangGraph")
使用工具绑定时,你需要先定义工具,再将其绑定到LLM 上,但当你想引入新的数据源时,仍然需要修改工具的具体实现。同样地,如果后端发生变化,你也必须更新工具的实现代码。
@tooldef search_docs(query: str):
return search_vector_store(query)
MCP 的实现方式
使用MCP 时,你的应用只需连接到一个标准化的接口,而由服务器来处理文档来源的具体细节:
# MCP Client/Host: Client/Host stays the same
# MCP Server: Define your MCP server# Import necessary librariesfrom typing import Anyfrom mcp.server.fastmcp import FastMCP
# Initialize FastMCP server
mcp = FastMCP("your-server")
# Implement your server's tools
@mcp.tool()async def example_tool(param1: str, param2: int) -> str:
"""An example tool that demonstrates MCP functionality.
Args:
param1: First parameter description
param2: Second parameter description
Returns:
A string result from the tool execution
"""
# Tool implementation
result = f"Processed {param1} with value {param2}"
return result
# Example of adding a resource (optional)
@mcp.resource()async def get_example_resource() -> bytes:
"""Provides example data as a resource.
Returns:
Binary data that can be read by clients
"""
return b"Example resource data"
# Example of adding a prompt template (optional)
mcp.add_prompt(
"example-prompt",
"This is a template for {{purpose}}. You can use it to {{action}}.")
# Run the serverif __name__ == "__main__":
mcp.run(transport="stdio")
接下来,你只需要通过更新配置文件,
将主机或客户端(例如Claude Desktop)配置为使用该MCP 服务器。
{
"mcpServers": {
"your-server": {
"command": "uv",
"args": [
"--directory",
"/ABSOLUTE/PATH/TO/PARENT/FOLDER/your-server",
"run",
"your-server.py"
]
}
}}
如果你更改了资源或文档的存储位置或存储方式,你只需要更新服务器,而无需改动客户端。
这就是“抽象封装”的魔力所在。
对于许多使用场景来说—— 尤其是在生产环境中,比如 IDE 插件或商业应用 —— 你甚至根本不能碰客户端的代码。
在这种情况下,MCP的解耦特性不仅是“锦上添花”,而是必不可少的基础能力。
它将应用逻辑与底层资源隔离开来,这样你只需要演进服务端的逻辑(工具、数据源或向量嵌入方式),而主机应用可以完全不动。
这就使得你可以快速迭代和实验,而不会引入回归bug 或违反现有应用的限制。
5. 快速回顾!
希望现在你已经明白:MCP 为什么重要。
想象一下你正在构建一个AI 助手,它需要具备以下能力:
-
访问一个知识库;
-
执行代码或脚本;
-
跟踪用户的历史对话。
如果没有MCP,你就不得不为每一个功能点编写大量自定义的“胶水代码”来完成集成。
当然,这样做也行。但迟早会翻车,因为这种方式脆弱、混乱,而且在规模化时几乎无法维护。
MCP通过充当模型与外部世界之间的通用适配器,解决了这个问题。你可以在不重写模型逻辑的前提下,接入新的工具或数据源。
这样做的优势在于:迭代更快、代码更干净、Bug更少、构建出的AI 应用真正具有模块化、可维护性。
还记得之前说的那点吗?MCP 支持主机(客户端)与服务器之间的双向通信。
这正是MCP 最强大的用例之一:持久化记忆(persistent memory)!
出厂状态下,LLM的记忆能力像金鱼——它们什么都记不住,除非你手动把整段历史对话记录一次性塞进上下文窗口。
但有了MCP,你可以实现:
-
存储和检索过去的交互记录
-
追踪用户的长期偏好与行为
-
构建真正“记得住”项目全貌或长时间会话的智能助手
MCP的出现,让你不再需要那些笨拙的 prompt 拼接技巧,或脆弱的“记忆补丁”。MCP 给你的模型配备了真正的“大脑”,而不仅仅是一段即时记忆。
6. MCP 服务器的核心能力
现在我们已经很清楚了:MCP 服务器就是整个协议的 MVP(最有价值组成)。
它是核心枢纽,负责定义模型实际可以使用的能力模块,主要包括三种类型:
Resources(资源):可以理解为:外部数据源 —— 比如 PDF 文档、API 接口、数据库等。模型可以将它们引入作为上下文信息,但不能修改它们,因为他们是只读的。
Tools(工具):指的是模型可以调用的实际功能 —— 如运行代码、搜索网页、生成摘要等等天马行空的功能。
Prompts(提示模板):即预定义的提示或模板,用于引导模型的行为或规范回答格式,类似给模型一本“操作手册”或“剧本”。
MCP强大的地方在于:
上述所有这些能力,都通过同一个统一的协议传输给模型。
这意味着模型可以:请求资源、调用工具、使用提示模板,且全部不需要为每个功能单独写自定义逻辑。只需接入MCP 服务器,一切都可以“即插即用”。
编辑:黄继彦

译者简介

翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
