Unsloth团队发布强化学习教程,讲解RLHF、PPO到GRPO,并分享用GRPO训练推理模型的技巧,助力入门。
原文标题:从RLHF、PPO到GRPO再训练推理模型,这是你需要的强化学习入门指南
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到设计良好的奖励函数是GRPO成功的关键,那么,如何避免奖励函数出现偏差,导致模型学到不符合预期的行为?
3、文章中提到GRPO适用于数学和代码等可验证任务,那么,如何将GRPO应用到更广泛的、难以直接验证的任务中,例如文本生成或创意写作?
原文内容
作者:Unsloth Team
强化学习(RL)已经成为当今 LLM 不可或缺的技术之一。从大模型对齐到推理模型训练再到如今的智能体强化学习(Agentic RL),你几乎能在当今 AI 领域的每个领域看到强化学习的身影。
近日,Daniel Han 和 Michael Han 两兄弟组成的团队 Unsloth(用于微调模型的同名开源项目 GitHub 星数已超过 4 万)发布了一个强化学习教程,其中从吃豆人谈起,简单易懂地从 RLHF、PPO 介绍到 GRPO,还分享了如何用 GRPO 训练推理模型的技巧。

-
原文地址:https://docs.unsloth.ai/basics/reinforcement-learning-guide
-
开源项目:https://github.com/unslothai/unsloth
全面了解强化学习以及如何使用 GRPO 训练你自己的推理模型。这是一份从初学者到高级的完整指南。
🦥你将学到什么
-
什么是强化学习 (RL)?RLVR?PPO?GRPO?RLHF?RFT?对于强化学习来说,运气 is All You Need?
-
什么是环境?agent?动作?奖励函数?奖励?
本文涵盖了你需要了解的关于 GRPO、强化学习 (RL) 和奖励函数的所有内容 —— 从初学者到高级,还有基于 Unsloth 使用 GRPO 的基础知识。
如果你正需要学习如何一步步实现 GRPO,这份指南值得一读。
❓什么是强化学习 (RL)?
强化学习的目标是:
-
增加获得「好」结果的几率。
-
降低出现「坏」结果的几率。
就这么简单!「好」和「坏」的含义错综复杂,「增加」和「降低」也许斟酌,甚至「结果」的含义也各不相同。
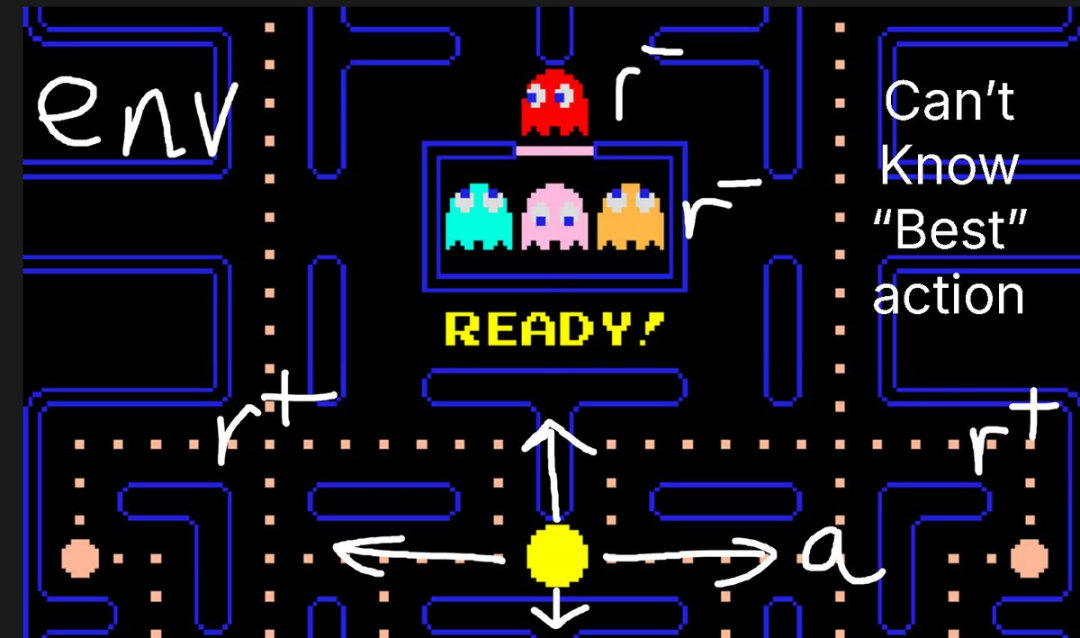
举个例子,在吃豆人(Pacman)游戏中:
-
环境就是游戏世界。
-
动作包括向上、向左、向右和向下。
-
如果你吃掉一块饼干,奖励是好的;如果你碰到敌人,奖励是坏的。
在强化学习中,你无法知道自己可以采取的「最佳动作」,但你可以观察中间步骤,或者最终的游戏状态(胜或负)。
再来个例子,假设你被问到这个问题:「What is 2 + 2?」 (4)
一个未对齐的语言模型会输出 3、4、C、D、-10 等等各种乱七八糟的答案。
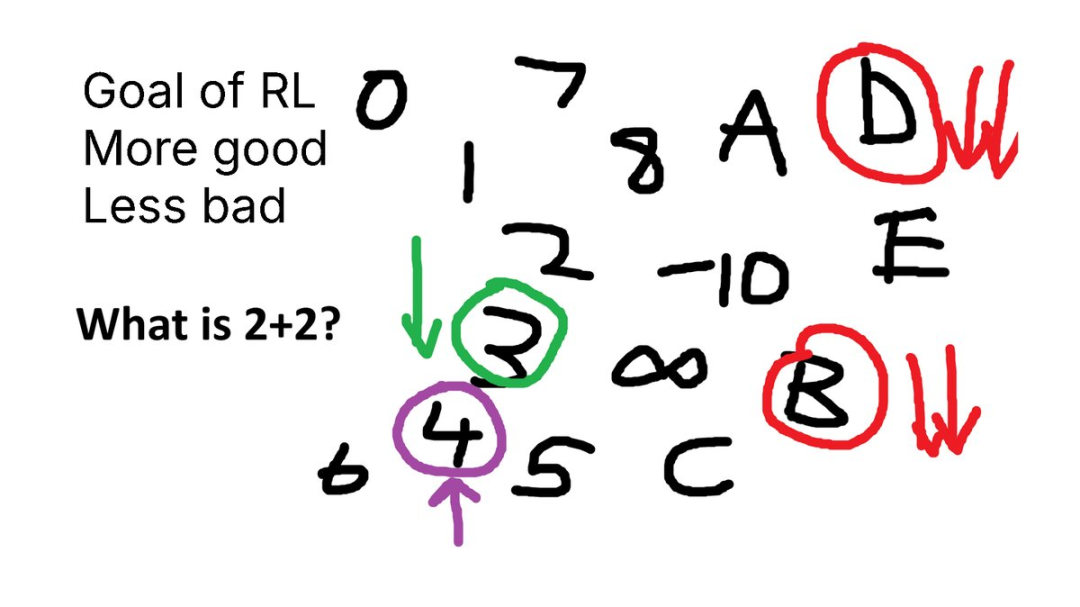
-
数字总比 C 或 D 好,对吧?
-
得到 3 总比得到 8 好,对吧?
-
得到 4 绝对没错!
其实,我们刚刚就设计出了一个奖励函数!
🏃从 RLHF、PPO 到 GRPO 和 RLVR
OpenAI 让 RLHF(基于人类反馈的强化学习)的概念变得人尽皆知。在该方法中,我们需要训练一个 agent 来针对某个问题(状态)生成人类认为更有用的输出。
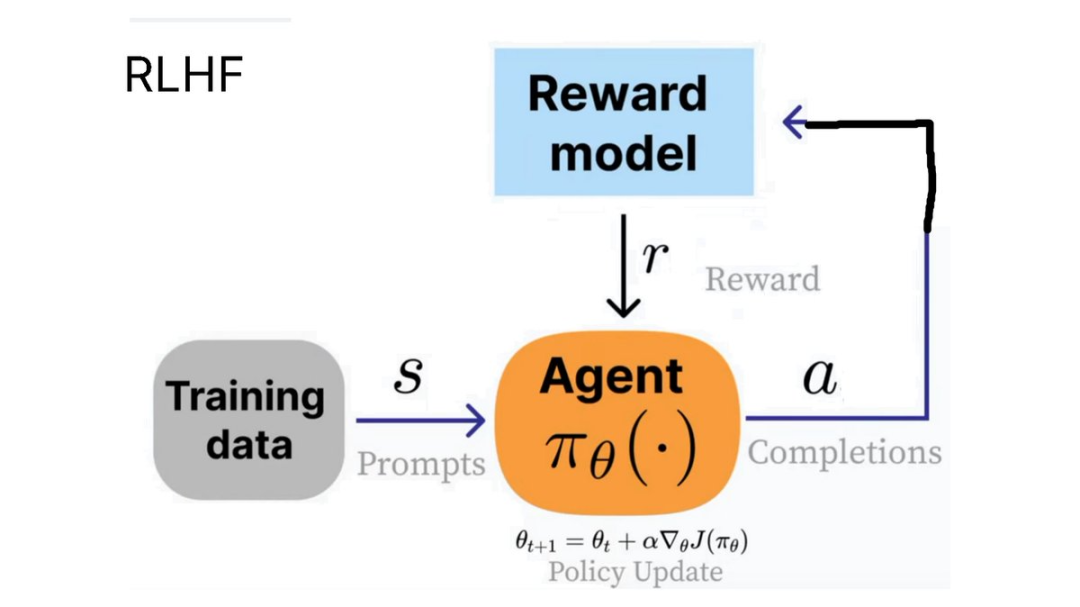
例如,ChatGPT 中的👍和👎符号就可以用于 RLHF 过程。
为了实现 RLHF,PPO(近端策略优化)被开发了出来。
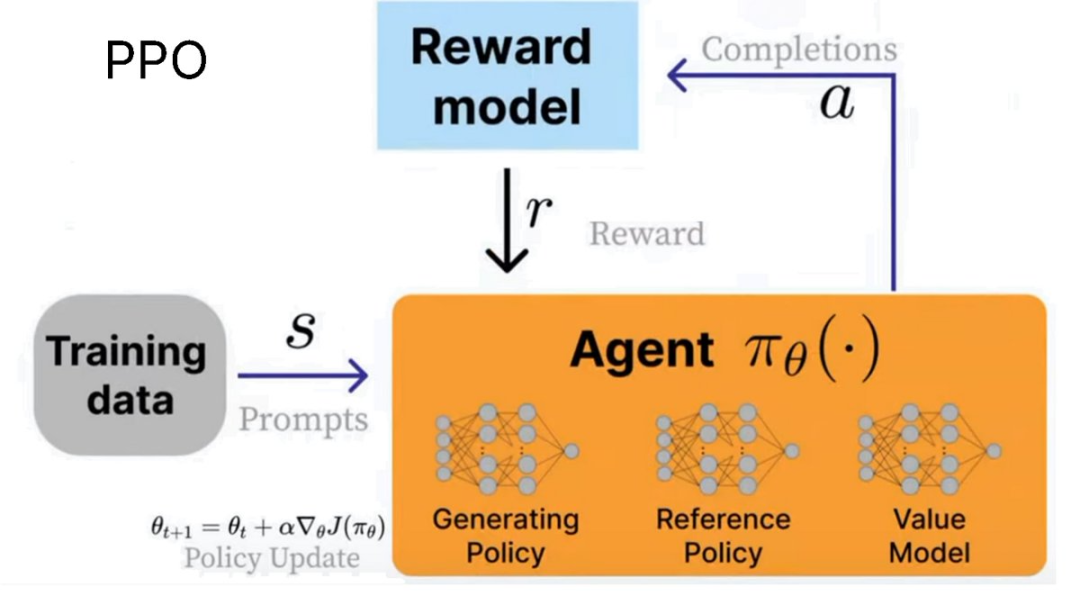
在这种情况下,agent 就是语言模型。事实上,它由三个系统组成:
-
生成策略(当前被训练模型)
-
参考策略(原始模型)
-
价值模型(平均奖励估算器)
我们使用奖励模型来计算当前环境的奖励,而我们的目标就是最大化奖励!
PPO 的公式看起来相当复杂,因为它的设计初衷是保持稳定性。
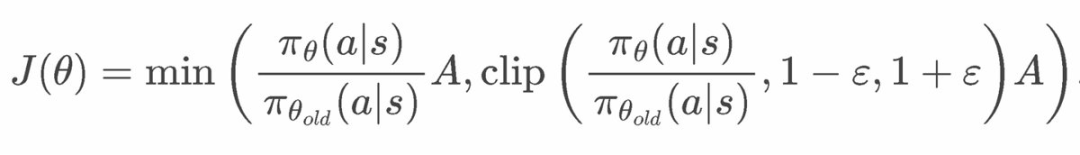
PPO 公式
DeepSeek 开发了 GRPO(组相对策略优化)来训练他们的推理模型。它与 PPO 的主要区别在于:
-
移除了价值模型,取而代之的是多次调用奖励模型的统计数据。
-
移除了奖励模型,取而代之的是自定义奖励函数,RLVR 可以使用该函数。
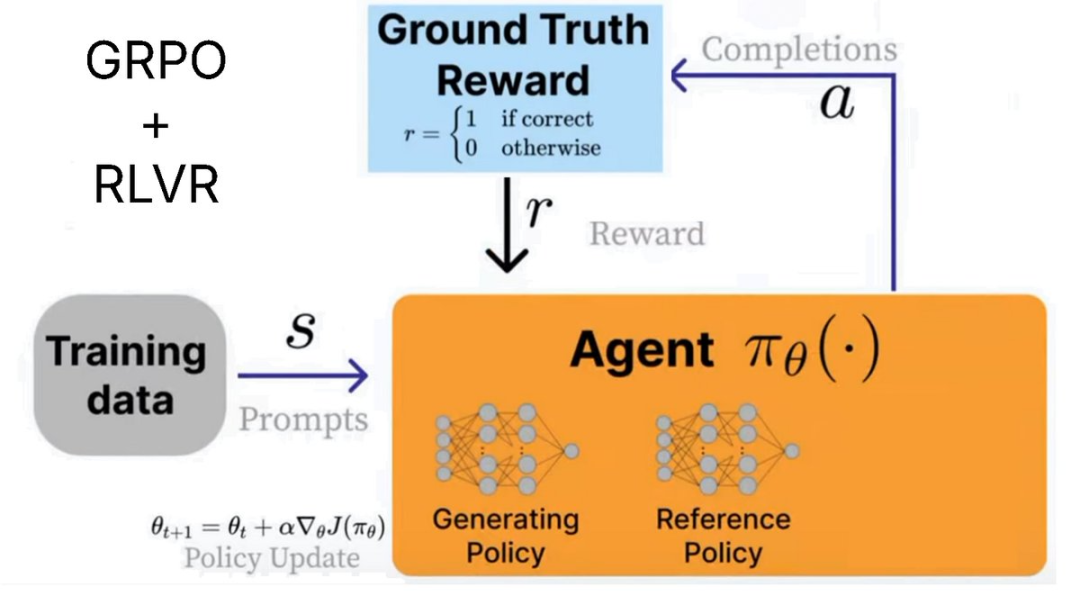
这意味着 GRPO 非常高效。以前 PPO 需要训练多个模型 —— 现在移除了奖励模型和价值模型,便可以节省内存并加快速度。
RLVR(可验证奖励的强化学习)允许我们根据易于验证解答的任务来奖励模型。例如:
-
数学等式可以轻松验证,如 2+2 = 4。
-
代码输出可以验证是否正确执行。
-
设计可验证的奖励函数可能很困难,因此大多数示例都与数学或代码相关。
-
GRPO 的用例不仅限于代码或数学 —— 它的推理过程可以增强电子邮件自动化、数据库检索、法律和医学等任务,并根据数据集和奖励函数显著提高准确性 —— 诀窍在于定义一个规则 —— 即一系列较小的可验证奖励,而不是最终的单一奖励。例如,OpenAI 也在其中用到了这一点。
为什么使用「组相对」?
GRPO 完全移除了价值模型,但我们仍然需要根据当前状态估算「平均奖励」。
诀窍在于对 LLM 进行采样!然后,我们通过统计多个不同问题的采样过程来计算平均奖励。
例如,对于「What is 2 + 2?」,我们采样 4 次。我们可能得到 4、3、D、C。然后,我们计算每个答案的奖励,计算平均奖励和标准差,最后用 Z 分数进行标准化!

这就产生了优势 A,我们将用它来替代价值模型。这可以节省大量内存!

GRPO 优势计算
🤞运气(耐心) Is All You Need
强化学习的诀窍在于你只需要两样东西:
-
一个问题或指令,例如「What is 2+2?」 「用 Python 创建一个 Flappy Bird 游戏」
-
一个奖励函数和一个验证器,用于验证输出是好是坏。
仅凭这两个,我们基本上可以无限次调用语言模型,直到得到一个好的答案。例如,对于「What is 2+2?」,一个未经训练的糟糕模型语言模型可能会输出:
0、cat、-10、1928、3、A、B、122、17、182、172、A、C、BAHS、%$、#、9、-192、12.31,然后突然变为 4。
奖励信号为 0、0、0、0、0、0、0、0、0、0、0、0、0、0、0,然后突然变为 1。

因此,RL 凭借运气和偶然性,在多次迭代中找到了正确答案。我们的目标是让好答案(4)出现的次数更多,其余(坏答案)出现的次数更少。
因此,RL 的目标是耐心 —— 在极限情况下,只要正确答案的概率至少有一点(不为零),那么就只是一场等待的游戏 —— 你一定会在极限情况下 100% 找到正确答案。
所以我喜欢称之为针对强化学习的「运气 Is All You Need」。
其实,更好的说法是针对强化学习的「耐心 is All You Need」。
本质上,强化学习提供了一种技巧 —— 与其简单地等待无限,不如在实实在在地收到「坏信号」(即坏答案)时去「引导」模型尝试不生成坏答案。这意味着,尽管你可能等待了很长时间才出现一个「好」答案,但模型其实已经在尽力调整,尽量不输出坏答案。
在「What is 2+2?」这个例子中,先出现了 0、cat、-10、1928、3、A、B、122、17、182、172、A、C、BAHS、%$、#、9、-192、12.31,然后突然出现了 4。
由于我们得到了坏答案,强化学习会影响模型,使其尝试不输出坏答案。这意味着随着时间的推移,我们会仔细地「修剪」或移动模型的输出分布,使其远离错误答案。这意味着强化学习并非低效,因为我们并非只是等待无限,而是积极地尝试「推动」模型尽可能地向「正确答案空间」靠拢。
注:如果概率始终为 0,那么强化学习就永远不会奏效。这也是为什么人们喜欢基于已经过指令微调的模型进行强化学习的原因,因为这样的模型已经可以相当好地部分执行指令 —— 这很可能将概率提升到 0 以上。
🦥Unsloth 能为强化学习提供什么?
-
Unsloth 配备 15GB 显存,支持将参数最多 17B 的任何模型(例如 Llama 3.1 (8B)、Phi-4 (14B)、Mistral (7B) 或 Qwen2.5 (7B))转换为推理模型。
-
最低要求:只需 5GB 显存即可在本地训练你自己的推理模型(适用于任何参数不超过 1.5B 的模型)。
这里给出了一个基于 Unsloth 使用 GRPO 训练自己的推理模型的详细教程,感兴趣的读者可以参考实验:
https://docs.unsloth.ai/basics/reinforcement-learning-guide/tutorial-train-your-own-reasoning-model-with-grpo
GRPO 是如何训练模型的?
-
对于每个问答对,模型会生成多种可能的答案(比如,8 种变体)。
-
使用奖励函数对每个答案进行评估。
-
训练步数:如果有 300 行数据,则需要 300 个训练步骤(如果训练 3 个 epoch,则需要 900 个训练步骤)。也可以增加每个问题生成的答案数量(例如,从 8 个增加到 16 个)。
-
该模型的学习方式是在每一步对权重进行更新。
这里有一些示例笔记本:
https://docs.unsloth.ai/get-started/unsloth-notebooks#grpo-reasoning-notebooks
基础知识/技巧
Unsloth 还分享了一些他们积累的心得:
-
等待至少 300 步,奖励才会真正增加。为了获得不错的结果,你可能需要至少等待 12 小时(这是 GRPO 的工作原理),但请记住,这不是强制性的,你可以随时停止。
-
为获得最佳效果,至少需要 500 行数据。你甚至可以尝试 10 行数据,但使用更多数据会更好。
-
每次训练运行都会有所不同,具体取决于你的模型、数据、奖励函数 / 验证器等。因此,虽然前面说最低训练步数是 300 步,但有时可能需要 1000 步或更多。所以,这取决于各种因素。
-
如果你在本地使用 GRPO 和 Unsloth,如果出现错误,可以「pip install diffusers」。请使用最新版本的 vLLM。
-
建议将 GRPO 应用于参数至少为 1.5B 的模型,以便正确生成思考 token,因为较小的模型可能无法做到。
-
对于 QLoRA 4-bit 的 GRPO GPU VRAM 要求,一般规则是模型参数 = 你需要的 VRAM 数量(你可以使用更少的 VRAM,但还是这样更好)。你设置的上下文长度越长,VRAM 就越多。LoRA 16-bit 至少会使用 4 倍以上的 VRAM。
-
可以持续微调,并且你可以让 GRPO 在后台运行。
-
示例笔记本使用的数据集是 GSM8K,这是目前 R1 风格训练最流行的选择。
-
如果你使用的是基础模型,请确保你拥有聊天模板。
-
使用 GRPO 训练的次数越多越好。GRPO 最大的优点是你甚至不需要那么多数据。你只需要一个优秀的奖励函数 / 验证器,并且训练时间越长,你的模型就会越好。随着时间的推移,你的奖励与步长的比率预计会像这样增加:
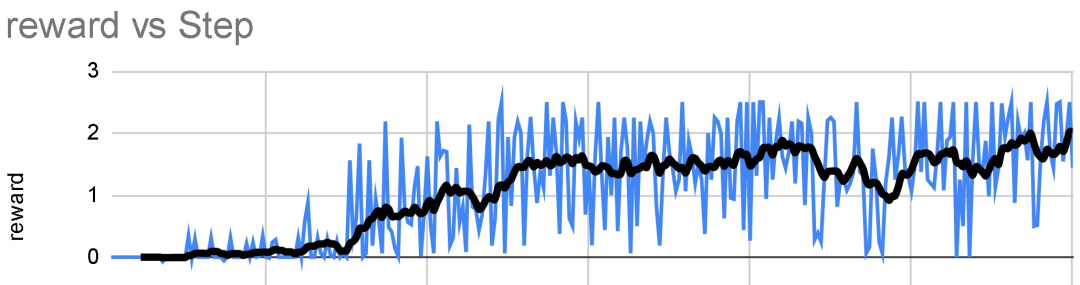
-
Unsloth 现已内置了 GRPO 的训练损失跟踪,无需使用 wandb 等外部工具。它现在包含所有奖励函数的完整日志详细信息,包括总聚合奖励函数本身。
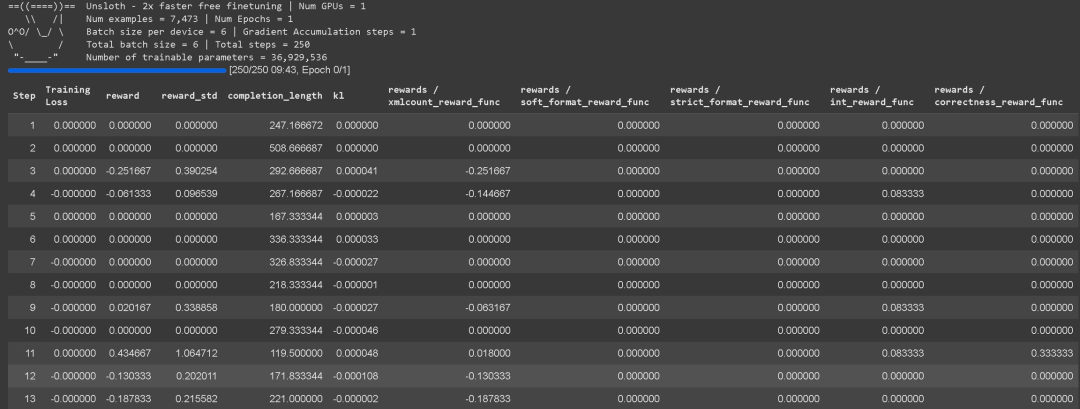
📋奖励函数 / 验证器
在强化学习中,奖励函数和验证器在评估模型输出方面发挥着不同的作用。一般来说,你可以将它们理解为同一件事,但从技术上讲,它们并非一回事,但这无关紧要,因为它们通常是配合使用的。
验证器(Verifier):
-
确定生成的响应是否正确。
-
它不会分配数值分数 —— 只是验证正确性。
-
例如:如果对于「2 + 2」,模型生成为「5」,则验证器会检查并将其标记为「错误」(因为正确答案是 4)。
-
验证器还可以执行代码(例如,使用 Python)来验证逻辑、语法和正确性,而无需手动评估。
奖励函数(Reward Function):
-
将验证结果(或其他标准)转换为数值分数。
-
例如:如果答案错误,它可能会分配罚分(-1、-2 等),而正确答案可能会获得正得分(+1、+2)。
-
它还可以根据正确性以外的标准进行惩罚,例如长度过长或可读性差。
主要区别:
-
验证器检查正确性,但不进行评分。
-
奖励函数会分配分数,但不一定验证正确性。
-
奖励函数可以使用验证器,但从技术上讲,它们并不相同。
理解奖励函数
GRPO 的主要目标是最大化奖励并学习答案的得出方式,而不是简单地记忆并根据训练数据复现答案。
-
在每个训练步骤中,GRPO 都会调整模型权重以最大化奖励。此过程会逐步微调模型。
-
常规微调(不使用 GRPO)仅最大化下一词的预测概率,而不会针对奖励进行优化。GRPO 针对奖励函数进行优化,而不仅仅是预测下一词。
-
你可以在多个 epoch 中重复使用数据。
-
你可以预定义默认奖励函数,以用于各种用例,或者你可以让 ChatGPT / 本地模型为你生成它们。
-
设计奖励函数或验证器没有唯一正确的方法 —— 这方面可能性无穷无尽。然而,它们必须设计精良且有意义,因为设计不当的奖励可能会无意中降低模型性能。
🪙奖励函数示例
参考以下示例。可以将你的生成结果输入到 ChatGPT 4o 或 Llama 3.1 (8B) 等 LLM 中,并设计一个奖励函数和验证器来评估它。例如,将你的生成结果输入到你选择的 LLM 中,并设置一条规则:「如果答案听起来太机械化,则扣 3 分。」这有助于根据质量标准优化输出。
示例 1:简单算术任务
-
问题:2 + 2
-
答案:4
-
奖励函数 1:如果检测到数字 → +1;如果未检测到数字 → -1
-
奖励函数 2:如果数字与正确答案匹配 → +3;如果不正确 → -3
-
总奖励:所有奖励函数的总和
示例 2:电子邮件自动化任务
-
问题:接收电子邮件
-
答案:发送电子邮件
-
奖励函数:
-
如果答案包含必需关键词 → +1
-
如果答案与理想答案完全匹配 → +1
-
如果答案过长 → -1
-
如果包含收件人姓名 → +1
-
如果存在签名块(电话、电子邮件、地址)→ +1
Unsloth 基于邻近度的奖励函数
在前面的 GRPO Colab 笔记本,可以看到其中创建了一个完全从零开始构建的自定义基于邻近度的奖励函数,旨在奖励那些更接近正确答案的答案。这个灵活的函数可以应用于各种任务。
-
在其中的示例中,是在 Qwen3 (Base) 上启用了推理功能,并将其引导至特定任务
-
应用预微调策略,以避免 GRPO 默认只学习格式
-
使用基于正则表达式的匹配提升评估准确度
-
创建自定义 GRPO 模板,超越诸如「think」之类的一般提示词,例如 <start_working_out></end_working_out>
-
应用基于邻近度的评分 —— 模型会因更接近的答案获得更多奖励(例如,预测 9 比预测 10 更好),而异常值则会受到惩罚
GSM8K 奖励函数
在其他示例中,Unsloth 使用了 @willccbb 提供的现有 GSM8K 奖励函数,该函数广受欢迎且已被证明非常有效:
-
Correctness_reward_func – 奖励完全匹配的标签。
-
Int_reward_func – 鼓励仅使用整数的答案。
-
Soft_format_reward_func – 检查结构,但允许少量换行符不匹配。
-
strict_format_reward_func – 确保响应结构与提示符匹配,包括换行符。
-
xmlcount_reward_func – 确保响应中每个 XML 标签恰好对应一个。
🎓扩展阅读
-
Nathan Lambert 的 RLHF 书: https://rlhfbook.com/c/11-policy-gradients.html
-
Yannic Kilcher 的 GRPO Youtube 视频: https://www.youtube.com/watch?v=bAWV_yrqx4w
-
Unsloth 在 2025 年 AI 工程师世界博览会上举办了一场 3 小时的研讨会,幻灯片等资料请访问:https://docs.unsloth.ai/ai-engineers-2025
-
通过 Unsloth 构建的高级 GRPO 笔记本。https://docs.unsloth.ai/basics/reinforcement-learning-guide/tutorial-train-your-own-reasoning-model-with-grpo
-
基于基础模型进行 GRPO 的笔记本:https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen3_(4B)-GRPO.ipynb
-
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com