本文介绍了KV缓存这一LLM推理加速的关键技术,并提供了从零实现KV缓存的代码示例,旨在帮助读者理解其原理和应用。
原文标题:一文搞懂LLM推理加速的关键,从零实现 KV 缓存!
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、文章中提到KV缓存只适用于推理阶段,那么训练阶段有什么类似的技术可以减少计算量吗?
3、文章中给出的代码示例主要是为了教学目的,牺牲了一定的性能。如果你要在实际项目中部署KV缓存,除了文章中提到的预分配内存和滑动窗口截断缓存之外,还有哪些其他的优化技巧可以使用?
原文内容
KV 缓存(KV cache)是让大模型在生产环境中实现高效推理的关键技术之一。本文将通过通俗易懂的方式,从概念到代码,手把手教你从零实现 KV 缓存。
什么是 KV 缓存?
想象一下,一个大模型(LLM)正在生成文本。比如说,模型接收到的提示词是 “Time”。你可能已经知道,LLM 是一次生成一个词(或 token)的,如下图所示,它可能经历如下两个生成步骤:

图示展示了 LLM 是如何逐步生成文本的,每次仅生成一个 token。从 “Time” 开始,生成 “flies”;接着模型会重新处理整个序列 “Time flies”,再生成 “fast”。
但你也许注意到了,模型每次都要重新处理完整的上下文信息(如 “Time flies”),这就带来了重复计算的问题。如下图所示:
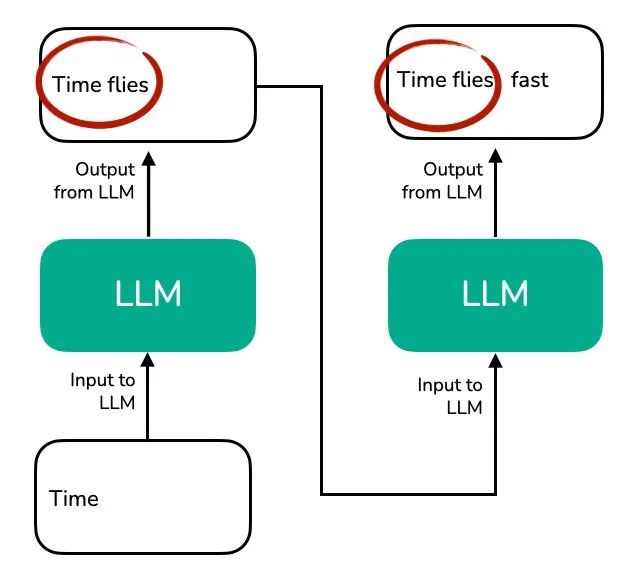
在这张图中可以看到,每次生成新 token(比如 “fast”)时,模型都重新对上下文 “Time flies” 进行编码。由于没有缓存中间的键和值向量的状态,模型每次都必须重新处理整个序列。
在我们实现文本生成函数时,我们通常只使用每个步骤中最后生成的 token。但上述可视化揭示了一个概念层面上的主要低效之处:重复计算。这个问题在深入关注注意力机制本身时会更明显。
如果你对注意力机制感兴趣,可以参考我写的《从零构建大模型》一书中的第三章。
接下来这张图展示了注意力机制中的一部分计算过程,这是大模型的核心之一。图中,输入的 token(比如 “Time” 和 “flies”)被编码为三维向量(真实情况中维度会更高,这里为了图示简洁而简化了)。矩阵 W 是注意力机制的权重矩阵,它们将这些输入转换为键、值和查询向量。
下图展示了带有突出显示的键和值向量的基本注意力分数计算的一个摘录:
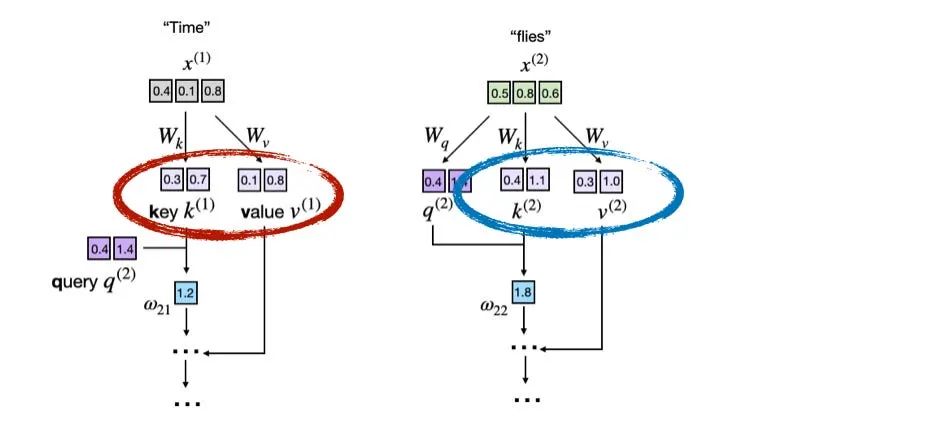
这张图展示了模型是如何通过学习到的 W_k 和 W_v 矩阵,将每个 token(例如 “Time” 和 “flies”)的嵌入映射为对应的键和值向量的。
如前所述,LLM 每次生成一个 token。比如在生成了 “fast” 之后,下一个提示词就变成了 “Time flies fast”。如下图所示:
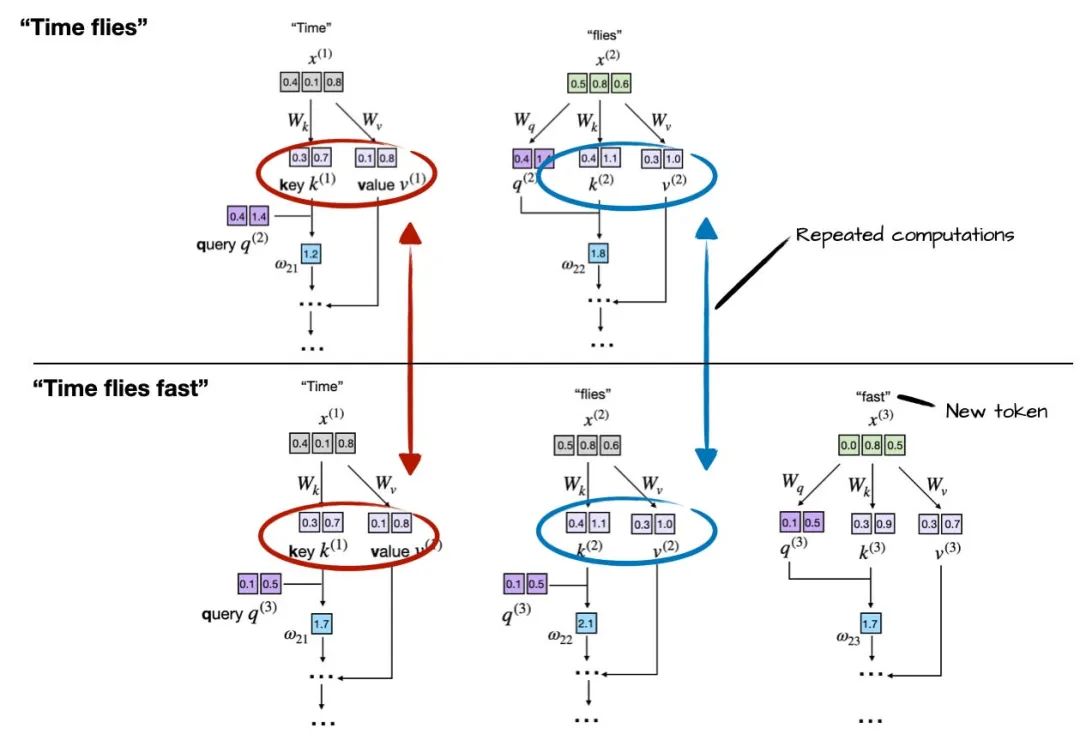
这张图展示了每次生成新 token(比如 “fast”)时,模型会重新计算先前 token(“Time” 和 “flies”)的键和值向量,而不是复用它们。这种重复计算清晰地揭示了在自回归解码过程中不使用 KV 缓存的低效。
通过比较前两张图可以发现,对于前两个 token,其键和值向量在每一轮生成中都是完全相同的。每次都重新计算这些内容显然是没有必要的,纯属浪费计算资源。
因此,KV 缓存的理念是实现一个缓存机制,把前面已经算好的键和值向量存储下来,供之后的生成步骤重复使用,从而避免这些无意义的重复计算。
LLM如何生成文本(有无 KV 缓存的区别)
在前一节介绍了 KV 缓存的基本概念后,我们来稍微深入一点,在讲具体代码实现前,先看看实际生成过程中出现的差异。
假设我们要生成 “Time flies fast” 这段文本,如果没有 KV 缓存,大致流程是这样的:
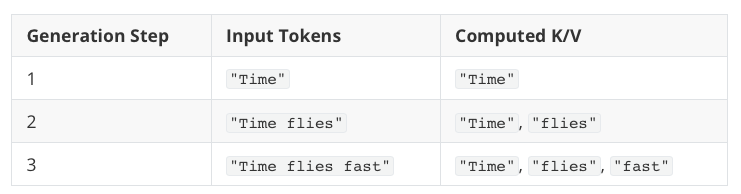
每生成一个新词,模型都会重新处理前面的所有词,比如每次都要重新计算 “Time” 和 “flies” 的信息。这就造成了明显的重复计算。
KV 缓存的作用就是解决这个问题——把之前已经计算过的键和值向量存下来,以后就不用再算了:
-
起初,模型会计算并缓存输入序列(比如 "Time" 和 "flies")的键和值向量;
-
接下来每个新生成的 token,模型只计算这个新词对应的键和值向量;
-
从缓存中检索之前计算的向量,以避免冗余计算。
下表总结了不同阶段的计算与缓存过程:

这里的好处是,“Time”只计算了一次,但复用了两次;“flies”也只计算了一次,复用了一次。(这个例子用的是很短的文本,为了方便说明。但直观来看,文本越长,能复用的键和值向量就越多,生成速度也会提升得越明显。)
下图展示了在第 3 步生成时,使用和不使用 KV 缓存两种情况下的对比效果。
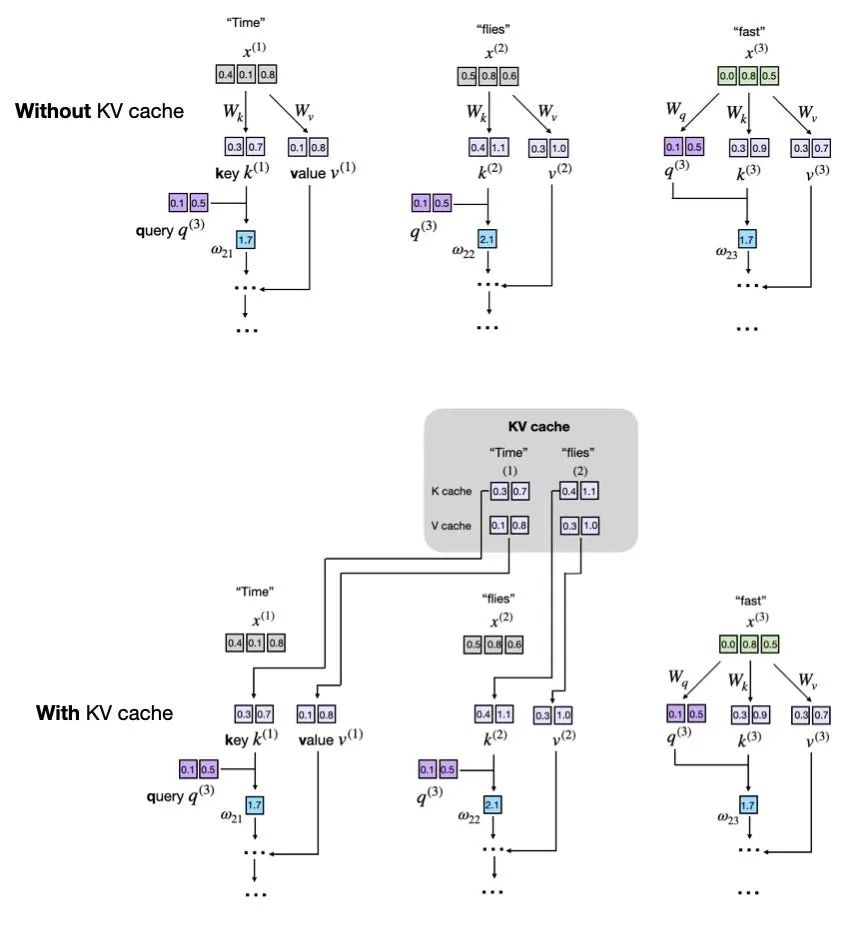
比较有和没有 KV 缓存的文本生成。在上图(没有缓存):每次生成都重新计算所有 token 的键和值向量,效率低;下图(有缓存):只计算当前新 token 的信息,其他的都直接从缓存中取出来,速度快了不少。
所以,如果你想在代码中实现 KV 缓存,核心思路其实很简单:正常计算值和 键向量后,把它们存储起来,下一次生成时直接拿来用就行。接下来的部分就会用代码例子具体演示这个过程。
从零开始实现 KV 缓存
实现 KV 缓存的方法有很多,主要思想在文本生成的每一步中,我们只对新生成的 token 计算键和值,而不是把所有的 token 都重新计算一遍。
在这里,我选择了一种简单的方法,强调代码的可读性。我认为直接浏览代码更改以了解其实现方式是最简单的。
我在 GitHub 上分享了两个文件,它们都是独立的 Python 脚本,从零实现了一个 LLM 的简化版——一个带 KV 缓存,一个不带:
-
gpt_ch04.py:取自我写的书《从零构建大模型》中的第 3、4 章,实现了基础的模型结构和文本生成逻辑;
-
gpt_with_kv_cache.py:和上面一样的模型,但加上了实现 KV 缓存所需的修改。
如果你想查看跟 KV 缓存相关的代码修改,有两种方式你可以选择:
a. 打开 gpt_with_kv_cache.py 文件,查找标注为 # NEW 的部分,那里标记了新增或改动的代码段;
b. 你也可以用任意一款文件对比工具,对这两个代码文件进行差异比较,直观查看具体修改了哪些地方。
另外,下面几个小节会对实现细节做一个简要梳理和说明。
1. Registering the Cache Buffers
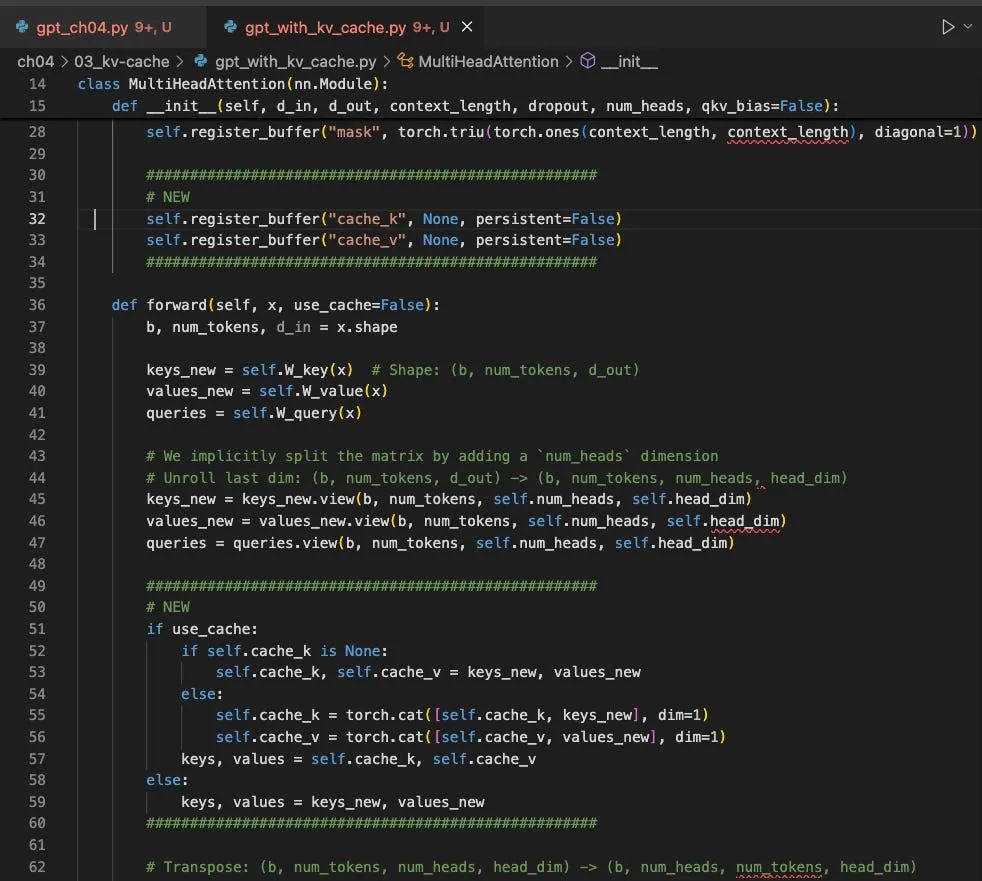
在 MultiHeadAttention 的构造函数中,我们添加了两个非持久性的缓存变量:cache_k 和 cache_v,用于在多步生成中保存连接起来的键和值。
self.register_buffer("cache_k", None, persistent=False)
self.register_buffer("cache_v", None, persistent=False)
2. 前向传递中使用 use_cache 标志
use_cache 的参数:
def forward(self, x, use_cache=False): b, num_tokens, d_in = x.shapekeys_new = self.W_key(x) # Shape: (b, num_tokens, d_out)
values_new = self.W_value(x)
queries = self.W_query(x)
#…
if use_cache:
if self.cache_k is None:
self.cache_k, self.cache_v = keys_new, values_new
else:
self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)
self.cache_v = torch.cat([self.cache_v, values_new], dim=1)
keys, values = self.cache_k, self.cache_v
else:
keys, values = keys_new, values_new
这段代码存储和检索键和值实现了 KV 缓存的核心思想。
存储
self.cache_k is None: ..., 初始化缓存之后,我们分别通过 self.cache_k = torch.cat(...) 和 self.cache_v = torch.cat(...) 将新生成的键和值添加到缓存中。
检索
当缓存中已经存好了前面几步的键和值,就可以直接通过 keys, values = self.cache_k, self.cache_v 取出使用。
这就是 KV 缓存最核心的存储和检索机制。接下来的第 3 和第 4 节会补充一些实现上的细节。
3. 清空缓存
在生成文本时,我们必须记得在两次独立的文本生成调用之间,重置键和值的缓存。否则,新输入的查询会关注到上一次序列遗留的过时缓存,导致模型依赖无关的上下文,输出混乱无意义的内容。为避免这种情况,我们在 MultiHeadAttention 类中添加了一个 reset_kv_cache 方法,以便在稍后的文本生成调用之间使用:
def reset_cache(self):
self.cache_k, self.cache_v = None, None
4. 在完整模型中传播 use_cache
在前面为 MultiHeadAttention 添加完缓存功能后,接下来我们要修改整个 GPTModel 类,确保缓存机制贯穿整个模型。
首先,我们在模型中添加一个用于记录标记索引位置的计数器:
self.current_pos = 0
这是一个简单的计数器,用来记录当前生成过程中,已经缓存了多少个 token。
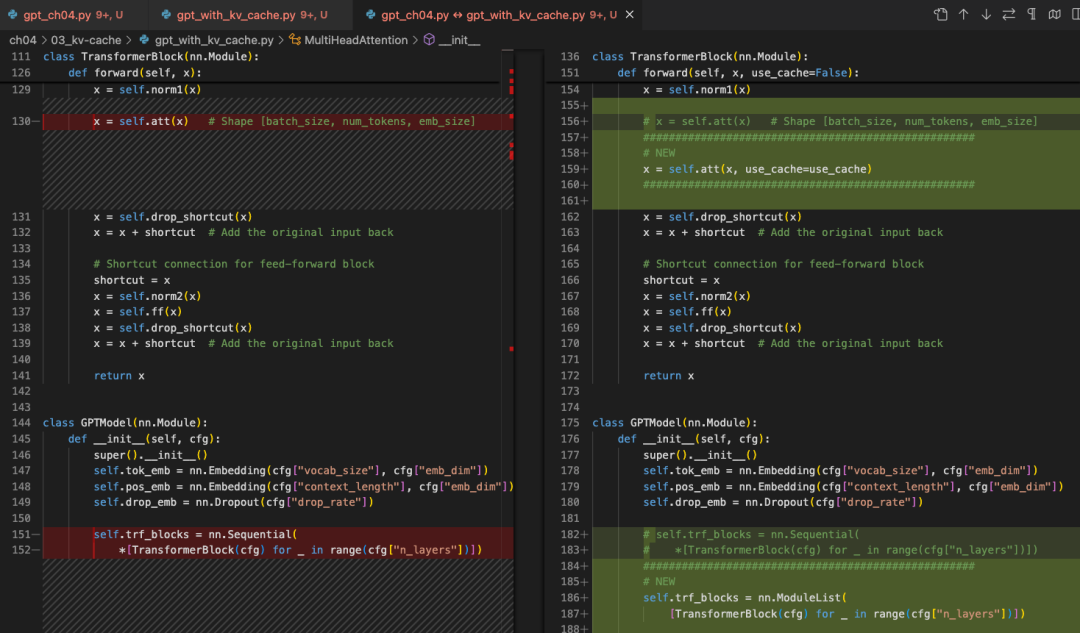
然后,我们将一行代码的块调用替换为一个显式的循环,并在每个 TransformerBlock 中传递 use_cache:
def forward(self, in_idx, use_cache=False): # ...if use_cache:
pos_ids = torch.arange(
self.current_pos, self.current_pos + seq_len,
device=in_idx.device, dtype=torch.long
)
self.current_pos += seq_len
else:
pos_ids = torch.arange(
0, seq_len, device=in_idx.device, dtype=torch.long
)
pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)
x = tok_embeds + pos_embeds
# …
for blk in self.trf_blocks:
x = blk(x, use_cache=use_cache)
offset = block.att.cache_k.shape[1] 来跟踪。)
为了让 TransformerBlock 支持这个逻辑,我们还要对它稍作修改,以接收 use_cache 参数:
def forward(self, x, use_cache=False):
# ...
self.att(x, use_cache=use_cache)
最后,为了方便,我们还给 GPTModel 添加了一个模型级别的重置,以便一次性清除所有块缓存,方便我们使用:
def reset_kv_cache(self):
for blk in self.trf_blocks:
blk.att.reset_cache()
self.current_pos = 0
5. 在生成中使用 KV 缓存
在完成了对 GPTModel、TransformerBlock 和 MultiHeadAttention 的修改之后,下面是在文本生成函数中实际使用 KV 缓存的方法:
def generate_text_simple_cached( model, idx, max_new_tokens, use_cache=True ): model.eval()ctx_len = model.pos_emb.num_embeddings # max sup. len., e.g. 1024
if use_cache:
# Init cache with full prompt
model.reset_kv_cache()
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=True)for in range(max_new_tokens):
# a) pick the token with the highest log-probability
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
# b) append it to the running sequence
idx = torch.cat([idx, next_idx], dim=1)
# c) feed model only the new token
with torch.no_grad():
logits = model(next_idx, use_cache=True)
else:
for in range(max_new_tokens):
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=False)
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
idx = torch.cat([idx, next_idx], dim=1)
return idx
需要特别注意的是:在带缓存的情况下,我们通过:logits = model(next_idx, use_cache=True) 将最新生成的 token 传入模型。
而如果没有缓存,就需要在每轮都重新输入整个序列 logits = model(idx[:, -ctx_len:], use_cache=False) 因为模型此时没有任何中间状态需要复用。这个区别正是 KV 缓存带来的核心性能优势。
简单的性能对比
在了解了 KV 缓存的原理后,接下来你自然要问:它在实际中到底有多大用?
为了验证,我们可以运行前面提到的两个 Python 脚本,分别测试不带缓存和带缓存的实现。这两个脚本会使用一个参数量为 124M 的小型 LLM 以生成 200 个新 token(给定一个 4 个 token 的提示 "Hello, I am" 以开始)。
运行步骤如下:
pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txtpython gpt_ch04.py
python gpt_with_kv_cache.py
在一台搭载 M4 芯片的 Mac Mini(CPU) 上,结果如下:
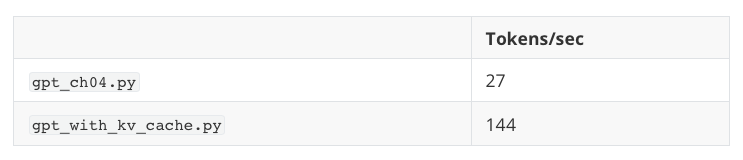
所以我们可以看到,即使是一个小型的 124 M 参数模型和一个简短的 200 token 序列长度,我们也已经获得了大约 5 倍的速度提升。(注意,这个实现优先考虑了代码的可读性,并没有针对 CUDA 或 MPS 等运行时速度环境进行优化——如果要进一步提速,需要预分配张量,而不是在每一步都重新创建和连接它们)
注意:无论是否使用缓存,模型目前生成的文本都是“胡言乱语”,输出文本示例:
Hello, I am Featureiman Byeswickattribute argue logger Normandy Compton analogous bore ITVEGIN ministriesysics Kle functional recountrictionchangingVirgin embarrassedgl ...
这段输出是模型生成的“胡言乱语”(gibberish),也就是说,看起来像英文,但并没有真实的语义或逻辑。
这是因为我们还没有对模型进行训练。下一章会讲训练模型,训练好后你可以在推理阶段使用 KV 缓存来生成连贯的文本(不过 KV 缓存只适合用于推理阶段)。这里我们用的是未经训练的模型,目的是让代码更简单。
更重要的是,gpt_ch04.py 和 gpt_with_kv_cache.py 的实现产生了完全相同的文本。这说明 KV 缓存的实现是正确的 —— 要做到这一点并不容易,因为索引处理稍有差错,就会导致生成结果出现偏差。
KV 缓存的优缺点
随着序列长度的增加,KV 缓存的优势和劣势也会变得更加明显:
优势:计算效率大幅提升。如果没有缓存,步骤 t 中的注意力必须将新查询与 t 个之前的键进行比较,因此累积工作量呈二次方增长,O(n²)。有了缓存,每个键和值只计算一次,然后重复使用,将每步的总复杂度降低到线性,O(n)。
劣势:内存使用呈线性增长。每个新标记都会附加到 KV 缓存中。对于长序列和更大的 LLM,累积的 KV 缓存会变得更大,这可能会消耗大量的(GPU)内存,甚至达到不可接受的程度。作为一种解决方法,我们可以截断 KV 缓存,但这会增加更多的复杂性(但 again, it may well be worth it when deploying LLMs.)
一种常见的做法是截断缓存,丢弃最早的部分,但这又会增加额外的实现复杂度。(不过在生产环境中,这种取舍通常是值得的。)
优化 KV 缓存的实现
上文中介绍的 KV 缓存实现方式,主要侧重概念清晰和代码可读性,非常适合教学用途。
但如果你想在实际项目中部署(尤其是模型更大、文本更长的情况下),就需要针对运行效率、显存使用等方面进行更加细致的优化。
-
内存碎片化和重复分配:像前面那样不断用 torch.cat 连接张量,会频繁触发内存的分配与重新分配,导致性能瓶颈。
-
内存使用呈线性增长:如果不加限制,KV 缓存的大小会随着生成的 token 数线性增长,对于超长序列来说,很快就会不堪重负。
# Example pre-allocation for keys and values
max_seq_len = 1024 # maximum expected sequence length
cache_k = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)
cache_v = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)
# Sliding window cache implementation
window_size = 512
cache_k = cache_k[:, :, -window_size:, :]
cache_v = cache_v[:, :, -window_size:, :]
实际优化效果,可以在 GitHub 中 gpt_with_kv_cache_optimized.py 文件中看到。
在配备 M4 芯片(CPU)的 Mac Mini 上,对于 200 个 token 的生成和等于 LLM 上下文长度的窗口大小(以保证相同的结果,从而进行公平比较),代码运行时间如下:

尽管缓存引入了额外的复杂性和内存考虑因素,但在生产环境中,效率的显著提升通常值得这些权衡。
需要注意的是,本文的重点在于讲清楚原理,因此优先考虑了代码的清晰度和可读性,而非运行效率。而在真实项目中,为了更高效地利用资源,往往还需要进行一些实用的优化,比如预分配内存、应用滑动窗口缓存来有效控制内存增长等。
希望这篇文章对你有所启发。
欢迎动手实践这些技巧,祝你写代码愉快!
Sebastian Raschka图书推荐

覃立波,冯骁骋,刘乾 | 译
在本书中,读者将学习如何规划和编写大模型的各个组成部分、为大模型训练准备适当的数据集、进行通用语料库的预训练,以及定制特定任务的微调。此外,本书还将探讨如何利用人工反馈确保大模型遵循指令,以及如何将预训练权重加载到大模型中。还有惊喜彩蛋 DeepSeek,作者深入解析构建与优化推理模型的方法和策略。

叶文滔 | 译