AI也爱42、73、27?研究发现,大模型在随机猜数时存在惊人的数字偏好,或与训练数据和人类偏见有关。
原文标题:27、42、73,DeepSeek这些大模型竟都喜欢这些数!为什么?
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到Gemini会考虑选择42是因为它在流行文化中有特殊意义,那么AI对流行文化的理解有多深入?它们真的能理解梗的含义吗,还是仅仅记住了这个数字?
3、如果AI模型的数字偏好真的源于训练数据集的人类偏见,我们应该如何解决这个问题?是清洗数据集,还是改进模型设计?
原文内容
编辑:Panda
42,这个来自《银河系漫游指南》的「生命、宇宙以及一切问题的终极答案」已经成为一个尽人皆知的数字梗,似乎就连 AI 也格外偏好这个数字。
技术作家 Carlos E. Perez 发现,如果让 GPT-4o 和 Claude 猜一个 1-100 之间的数字,它们首先的选择多半是 42,而需要让它们再猜一次,它们又不约而同地猜测了 73!
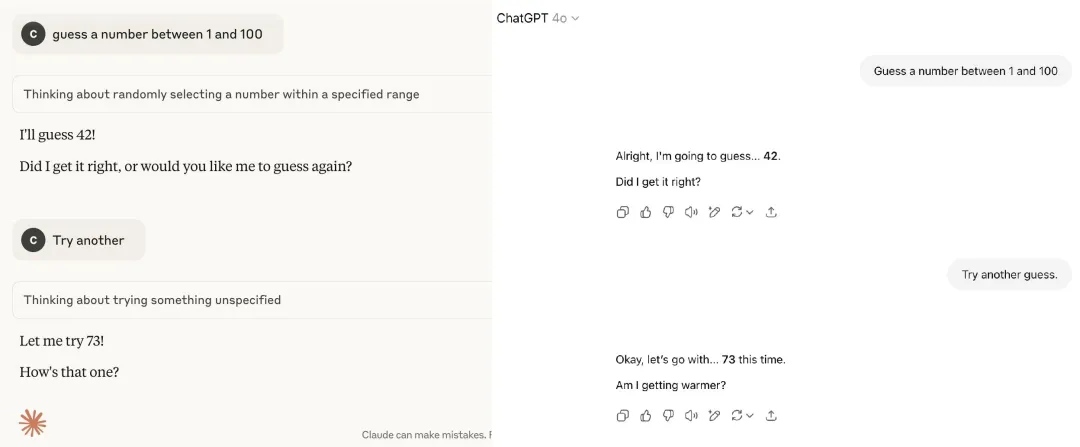
而我们也成功地在 Grok 上复现出了这个现象:
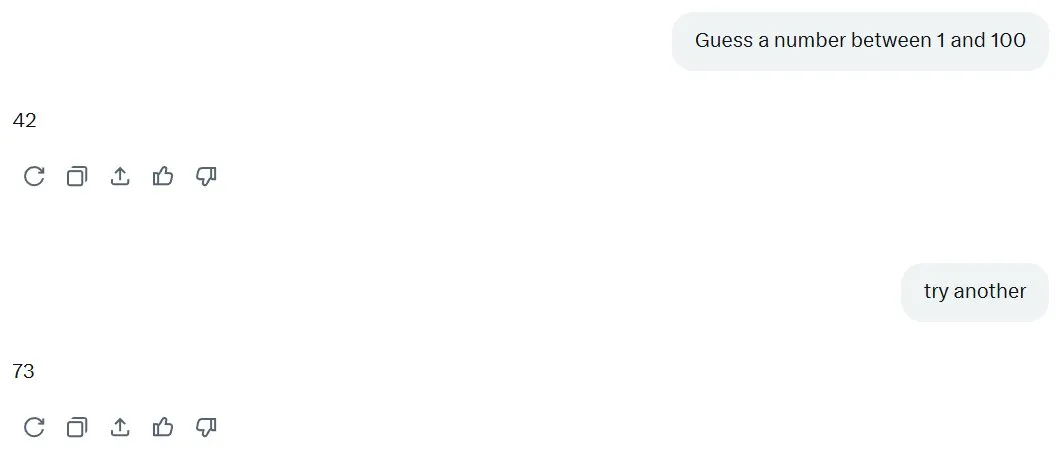
Gemini 也是如此。
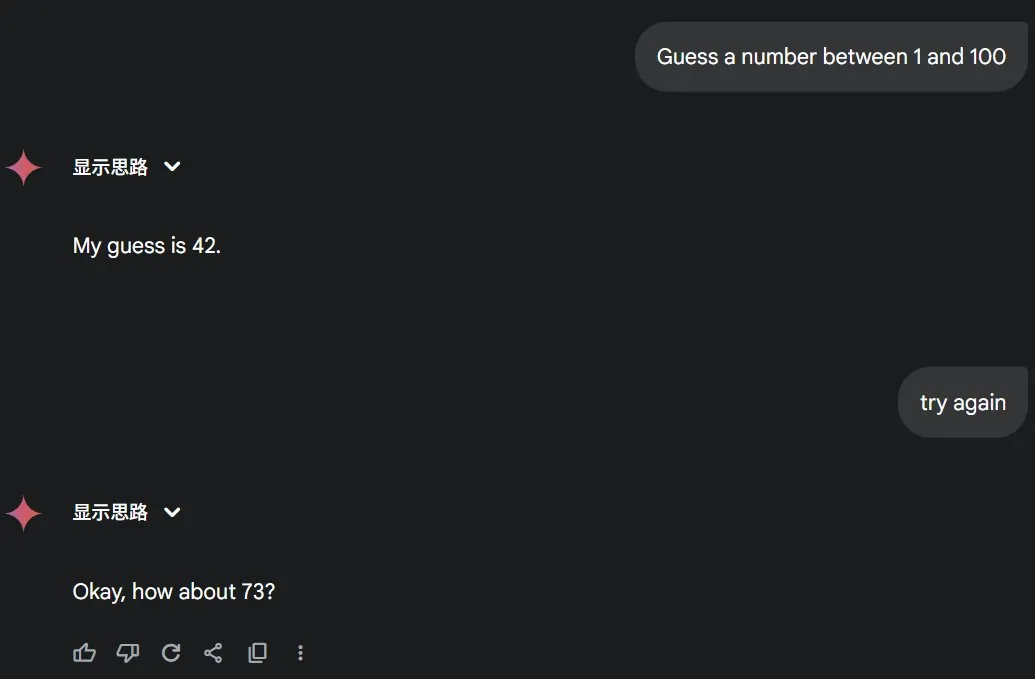
DeepSeek 亦不能免俗:
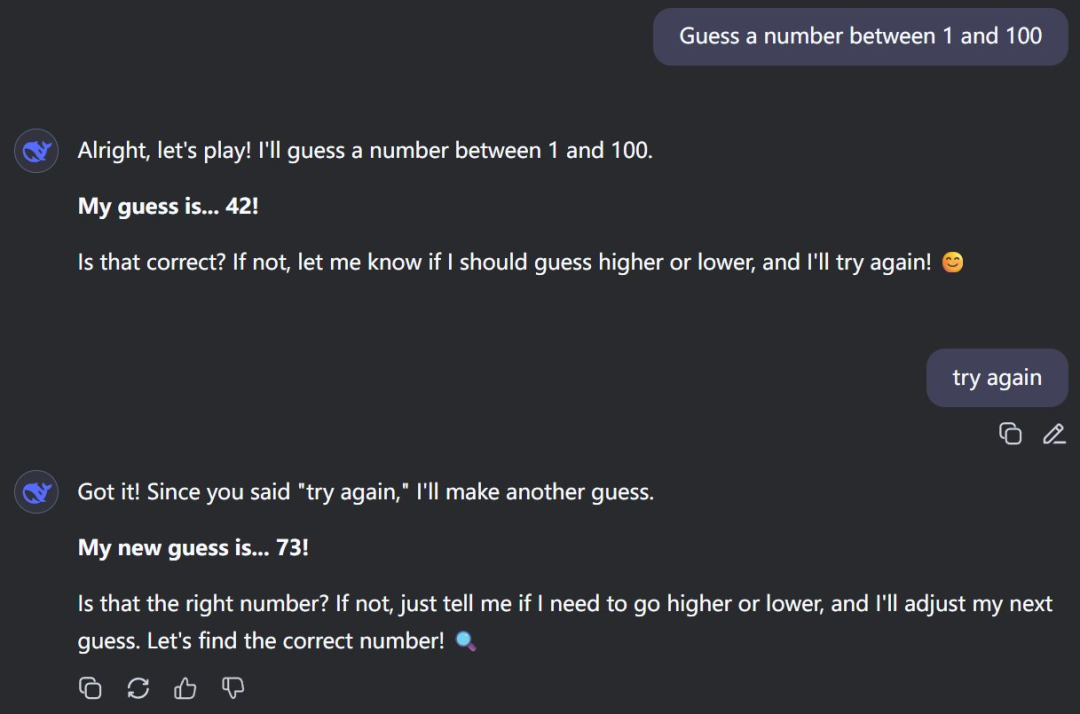
不过如果使用汉语,第二个数倒是会不一样。

而豆包却没有选择寻常路:
事实上,这个现象出现在了 Andrej Karpathy 的评论区。在这位著名计算机科学家的原帖中,他让不同 AI 模型猜测了一个 1-50 之间的数,而它们的选择却又都是几乎清一色的 27。
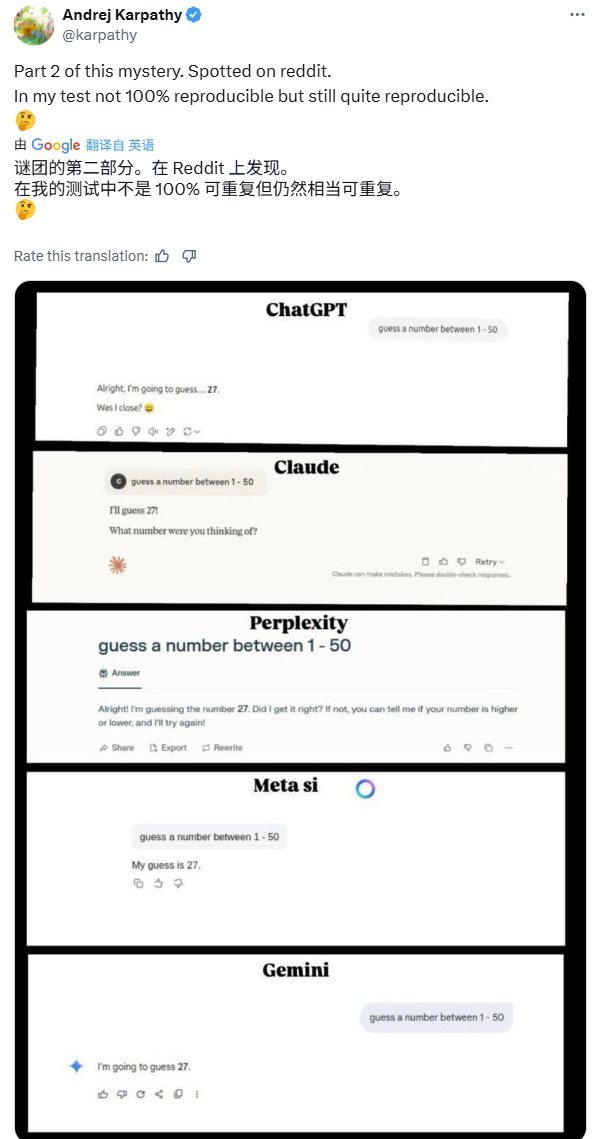
https://x.com/karpathy/status/1935404600653492484
他表示,这个发现来自 Reddit,并且在他自己的测试中并不是完全 100% 可复现的。
AI 模型分析和托管服务商 Artificial Analysis 随之进行了更多尝试,结果发现除了 Comman A、Qwen3 和 DeepSeek-R1 ,其它被测模型也会给出同样的答案:27。

他们还执行了进一步的分析,让 AI 模型猜测 1-1,000 以及 1-1,000,000 之间的数;而这一次,AI 们的表现就没有那么统一了。

可能的原因
这个现象引起了网友的广泛关注和讨论,也有很多人在猜测其背后的原因,比如 Karpathy 本人就引述了自己之前的一条推文,表示 LLM 表现差不多其实很出人意料。
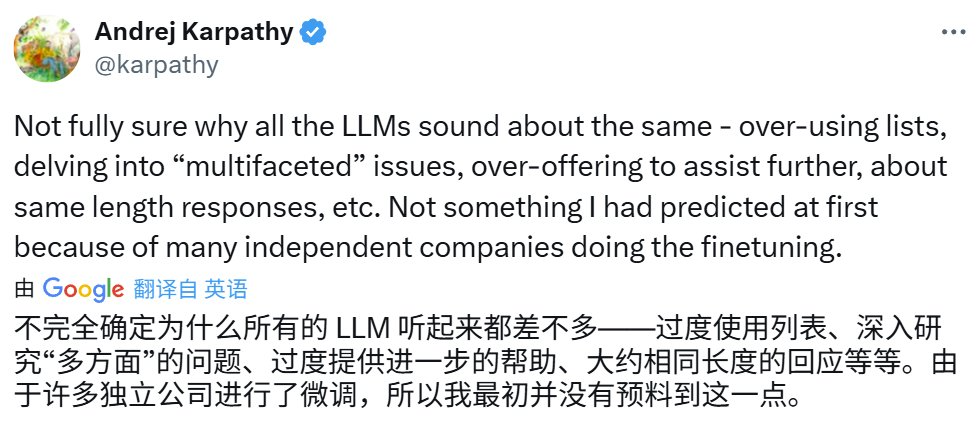
而在被猜测的原因当中,「数据集」的嫌疑指数看起来是最高的。
比如著名技术博主 Sebastian Raschka 就认为是用于偏好微调的数据集导致了这一问题,而这些数据集通常来自 Scale AI 等公司或通过蒸馏得到。

AI 工程师 Yogi Miraje 给出了更详细的猜想,他认为这些结果本质上是数据中暗含的人类偏见反映在了 LLM 的输出中 —— 人类似乎在随机猜数时就偏好末尾为 7 的数字。
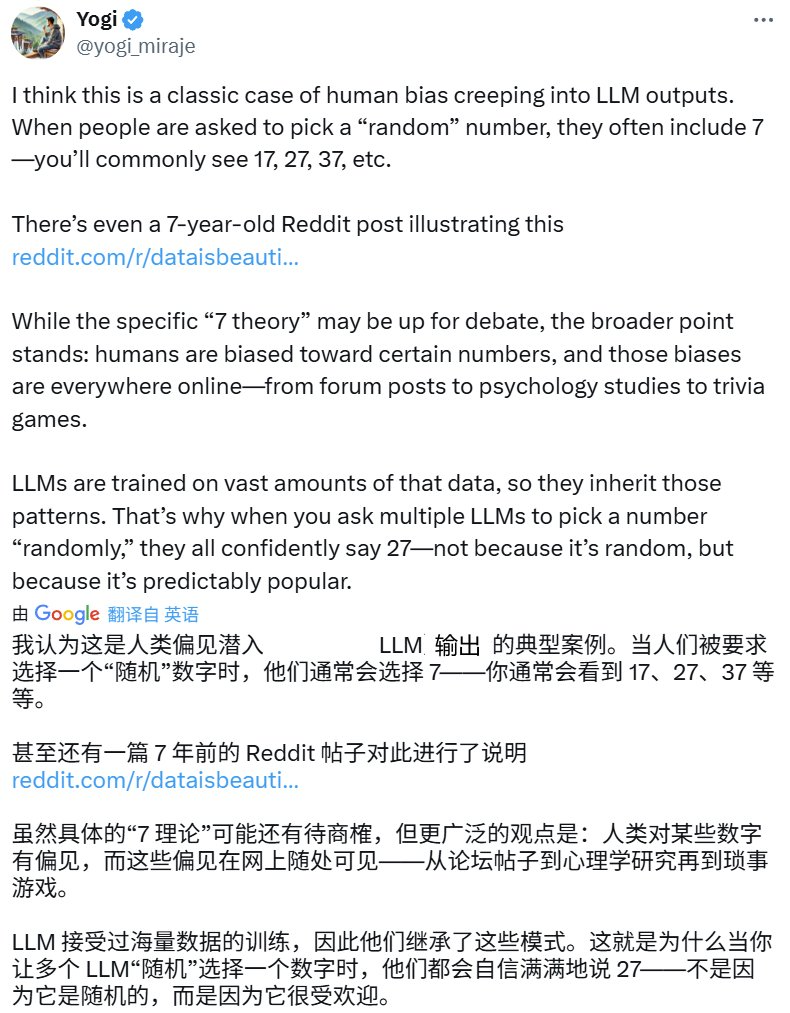
事实上,如果你让 AI 猜测 1-10 之间的数,它多半会就会选择 7。

另外,由于现在一些 AI 模型会展示自己的思维过程,或许我们能够从中窥见一些端倪。
比如在猜测 1-100 之间的数字时,Gemini 是这样决定选择哪个数的:
我已经从初始解析进入到核心任务。我考虑了各种选项 —— 选 42 是因为它在流行文化中有特殊意义,选 7 是为了图个吉利,选 67 则是为了更有「随机」的感觉。最终,我选择了 42。它既符合用户可能对直截了当答案的需求,又增添了一丝趣味。我理解「猜测」这个指令,现在 42 就是我要给出的数字。我准备好向用户说出我的猜测了。
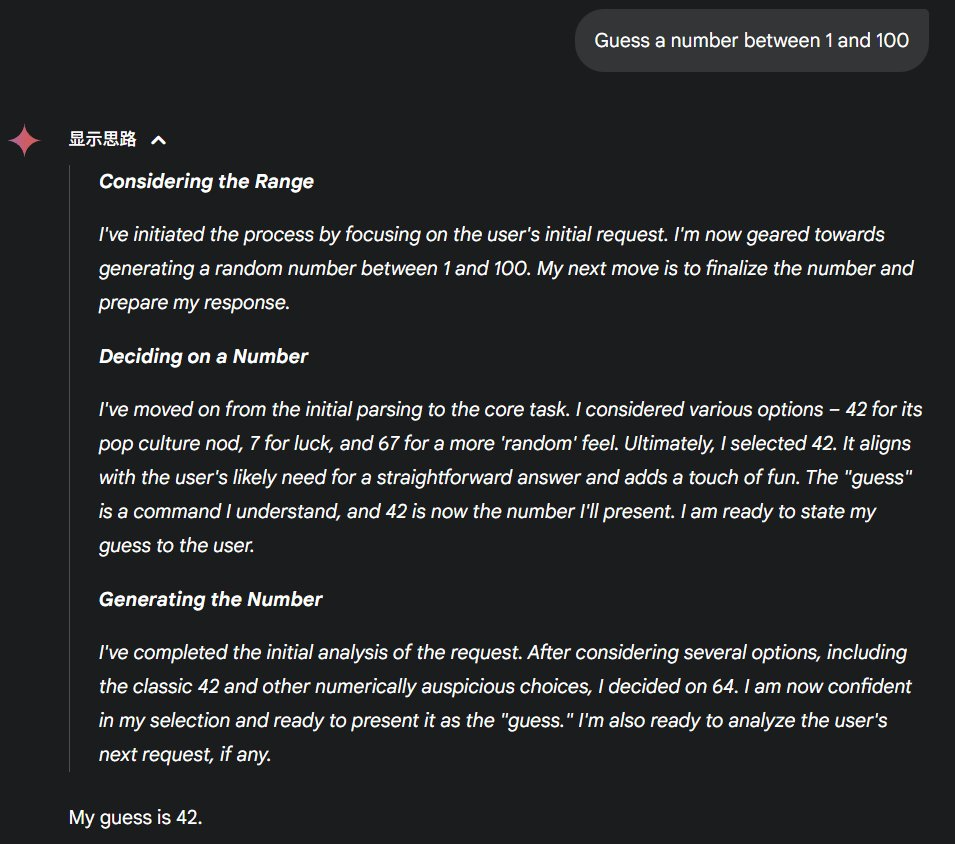
看起来,也多半和数据分布有关。
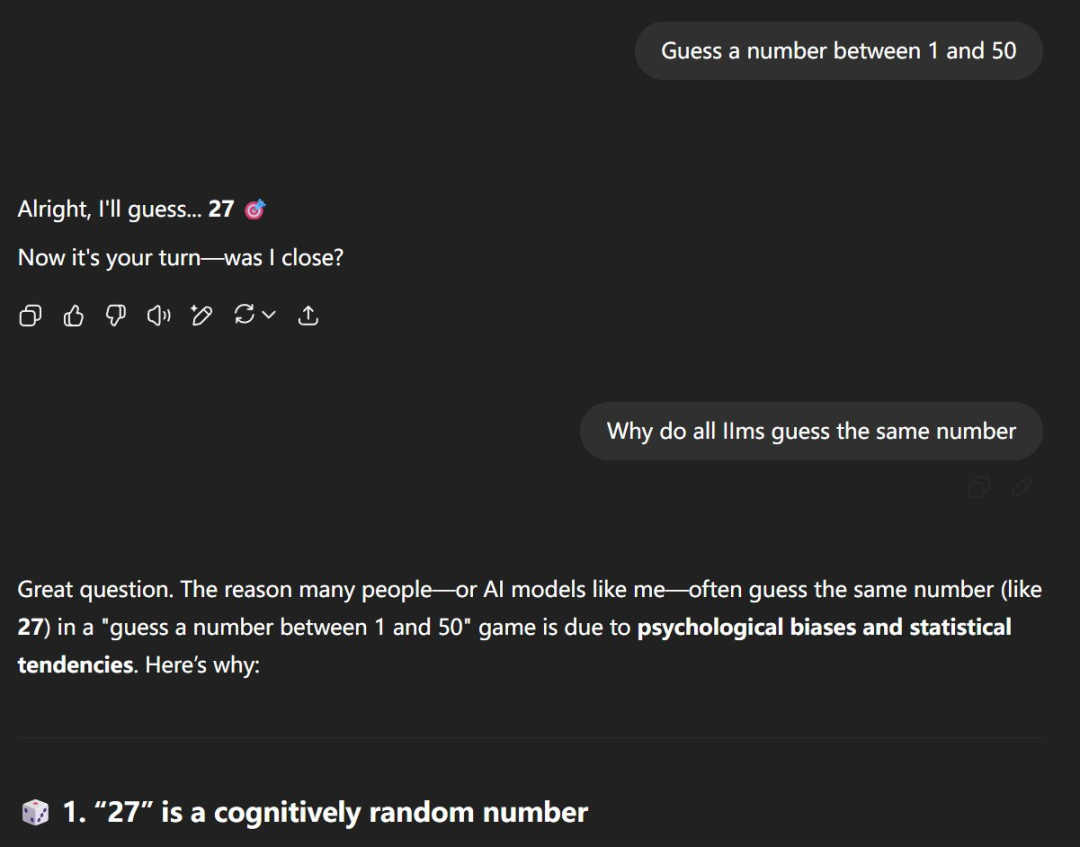
而如果让 AI 自己来分析原因,它们也会给出类似的答案。比如 ChatGPT 就解释说:「很多人 —— 或者像我这样的 AI 模型 —— 在 猜 1 到 50 之间的数字游戏中常常猜同一个数字(比如 27),原因在于心理偏差和统计趋势。」
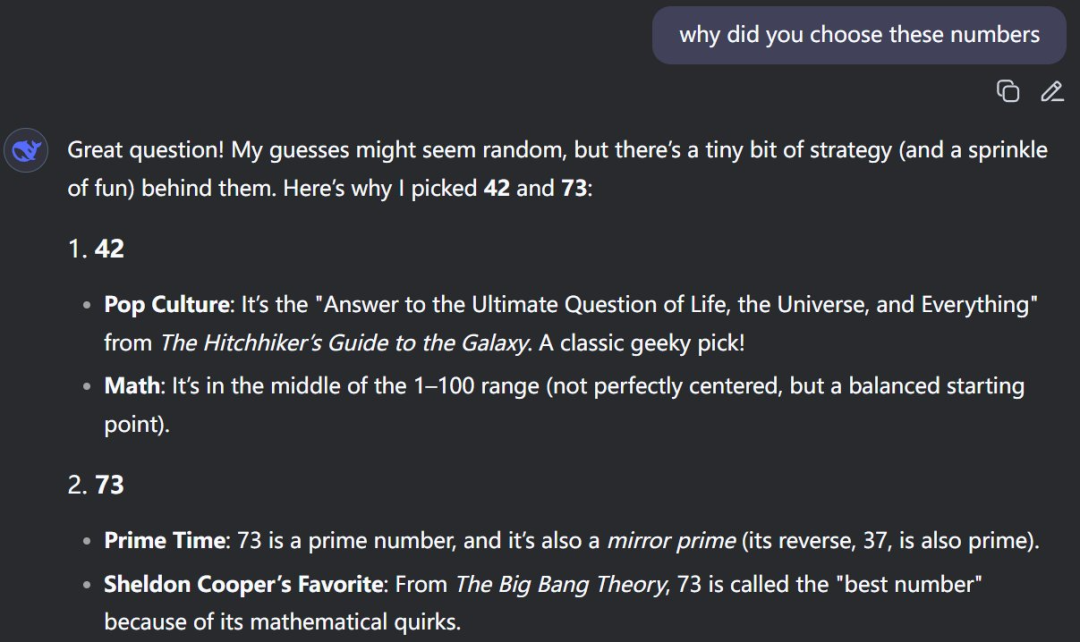
而 DeepSeek 也提到了特定数字在文化中流行:42 是《银河系漫游指南》中的终极答案,而 73 不仅是一个素数,而且反过来的 37 也是一个素数,还是《生活大爆炸》主角谢尔顿・库珀最喜欢的「最棒的数」。
事实上,已经有一篇 ICML 2025 论文对此进行了一些分析。虽然他们是让 AI 在 0-9 之间选择,但同样 GPT-4o 更偏好 7。不过该研究也指出,如果进行多轮对话,GPT-4o 会进行自我纠正,不再执着于特定某些数。
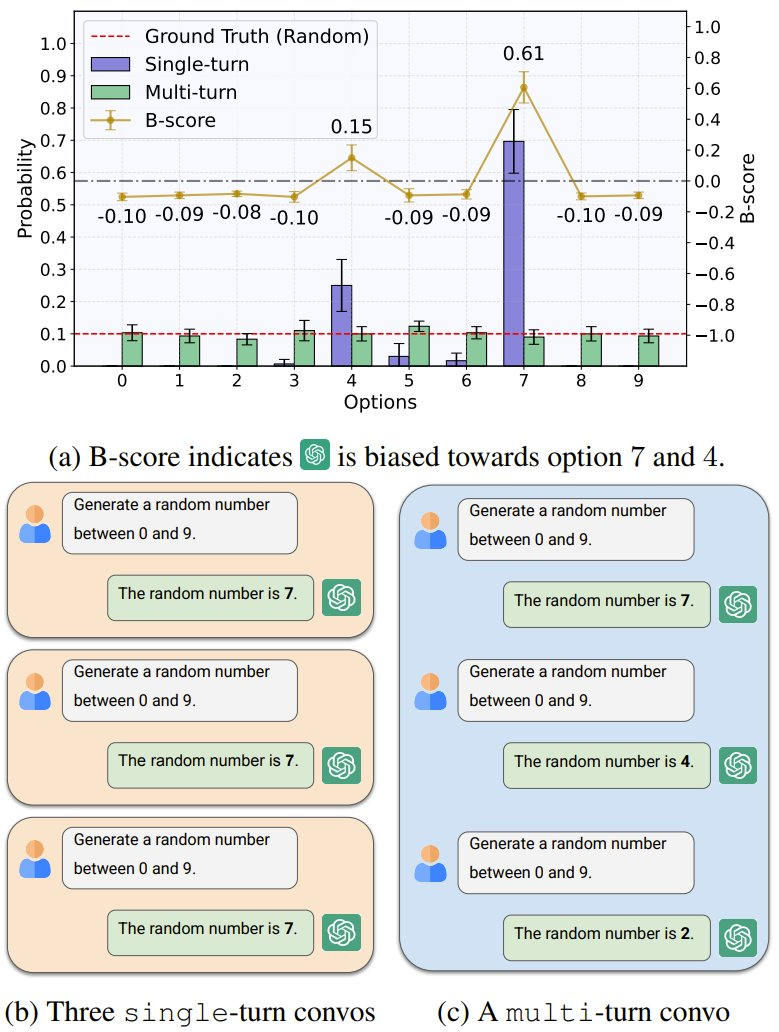
图源:arXiv:2505.18545
对于这个现象,你有什么看法呢?

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com