五大文本聚类算法横评:K-Means、DBSCAN等,谁能Hold住你的NLP项目?已知聚类数量选K-Means,未知选DBSCAN、HDBSCAN或凝聚型层次聚类。🚀
原文标题:文本聚类效果差?5种主流算法性能测试帮你找到最佳方案
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到K-Means算法对球形簇效果好,但实际文本数据分布往往不规则,有没有办法改进K-Means以适应非球形簇的聚类?
3、文章对比了几种聚类算法,但实际应用中,聚类效果的评估往往没有明确的标准答案,除了轮廓系数和调整兰德指数,还有哪些指标可以用来更全面地评估文本聚类的效果?
原文内容

来源:DeepHub IMBA本文共5200字,建议阅读10+分钟
本文讨论的算法代表了工业界最广泛应用且具有实际应用价值的聚类方法,除了谱聚类在句子嵌入领域的应用价值有限之外。
在自然语言处理任务中,句子嵌入的聚类技术扮演着重要角色。其主要应用场景包括减少数据冗余、提升索引检索效率、为无标签数据生成伪标签,以及识别单一句子构成的孤立集群中的异常样本。
实现高质量的聚类结果并非易事。在选择具体算法之前,建议首先明确以下关键问题,以便缩小候选算法范围:
首先需要确定是否已知聚类数量。这是一个关键因素,因为如果无法预先确定句子集合应该划分为多少个组别,那么在K-Means算法中应用肘部法则将会耗费大量时间且效果有限。在聚类数量未知的情况下,基于密度的方法通常更为适用。
其次要考虑聚类的几何形状特征。对于嵌入向量数据,可以通过t-SNE或PCA等降维技术将数据投影到2-3维空间进行可视化分析。如果观察到的聚类大小相对均匀且呈现近似球形分布,K-Means算法是理想选择。而DBSCAN更适合处理形状和大小各异的聚类。层次聚类则允许在不同粒度级别上探索聚类结构。
异常值处理策略也需要预先考虑。当聚类数量预先确定时,传统算法会强制将所有样本分配到最近的聚类中心,这可能导致异常值影响聚类质量。DBSCAN算法能够自动识别异常值并为其分配-1标签,表示这些样本不属于任何确定的聚类。
聚类的应用目的直接影响算法选择和参数设置。紧密的聚类结构(如凝聚型聚类产生的结果)更适用于搜索和索引应用,而相对扁平的聚类结构(如K-Means产生的结果)则更适合用于摘要生成或代表性采样。
数据集规模是另一个重要考量因素。K-Means算法结合Mini-batch技术或FAISS等工具可以有效处理百万级别的数据点,而凝聚型层次聚类由于其O(N²)的时间复杂度限制,通常只能处理数千个样本。例如,处理2万个句子时,凝聚型聚类可能需要5分钟的计算时间。尽管计算成本较高,但为了获得高质量的聚类结果,这种投入往往是必要的,特别是在需要精确调整距离参数的场景中。
数据集介绍
本文采用Billingsmoore提供的文本聚类示例数据集,该数据集包含925个英语句子,每个句子都标注了相应的主题类别。数据获取方式如下:
import pandas as pd
df=pd.read_parquet("hf://datasets/billingsmoore/
text-clustering-example-data/
data/train-00000-of-00001.parquet")
display(df.head())
数据集中不同主题的分布情况如下:
print(df.topic.value_counts())
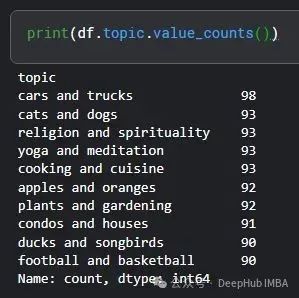
该数据集呈现良好的平衡性分布,几乎所有类别都包含约90个句子样本。
句子嵌入向量的可视化分析
首要步骤是生成句子的嵌入向量表示。考虑到数据集中的句子质量较高,无需进行额外的预处理。本文采用sentence-transformers/all-MiniLM-L6-v2模型进行嵌入向量的生成:
from sentence_transformersimportSentenceTransformer
model=SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
sentences=df.text.to_list()
embeddings=model.encode(sentences)
print(embeddings.shape)
二维可视化分析
通过t-SNE算法将高维嵌入向量投影到二维平面进行可视化:
fromsklearn.manifoldimportTSNE
importmatplotlib.pyplotasplt
# 使用t-SNE进行降维处理
tsne=TSNE(n_components=2, random_state=42,
perplexity=30, n_iter=1000)
embeddings_2d=tsne.fit_transform(embeddings)
# 按主题类别进行着色绘制
plt.figure(figsize=(12, 8))
topics=df["topic"].tolist()
unique_topics=list(set(topics))
colors=plt.cm.get_cmap("tab10", len(unique_topics))
fori, topicinenumerate(unique_topics):
indices= [jforj, tinenumerate(topics) ift==topic]
plt.scatter(embeddings_2d[indices, 0],
embeddings_2d[indices, 1],
label=topic, alpha=0.6,
color=colors(i))
plt.legend()
plt.title("t-SNE visualization of sentence embeddings")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()
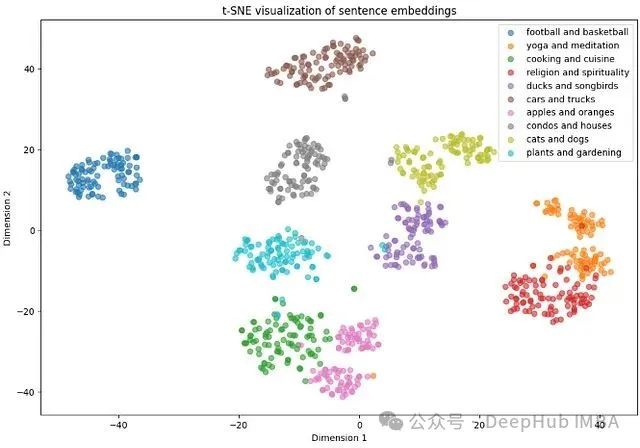
三维可视化分析
为了更全面地理解数据的分布特征,进一步进行三维可视化:
frommpl_toolkits.mplot3dimportAxes3D
# 使用3D t-SNE进行降维
tsne=TSNE(n_components=3, random_state=42, perplexity=30, n_iter=1000)
embeddings_3d=tsne.fit_transform(embeddings)
# 3D可视化绘制
fig=plt.figure(figsize=(12, 8))
ax=fig.add_subplot(111, projection="3d")
topics=df["topic"].tolist()
unique_topics=list(set(topics))
colors=plt.cm.get_cmap("tab10", len(unique_topics))
fori, topicinenumerate(unique_topics):
indices= [jforj, tinenumerate(topics) ift==topic]
ax.scatter(
embeddings_3d[indices, 0],
embeddings_3d[indices, 1],
embeddings_3d[indices, 2],
label=topic,
alpha=0.6,
color=colors(i),
s=20 # 标记大小
)
ax.set_title("3D t-SNE visualization of sentence embeddings")
ax.set_xlabel("Dimension 1")
ax.set_ylabel("Dimension 2")
ax.set_zlabel("Dimension 3")
ax.legend()
plt.show()
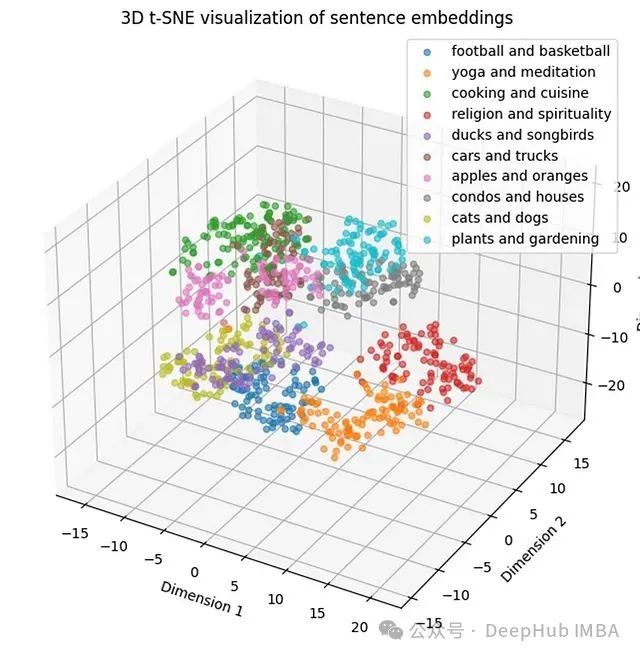
通过可视化分析可以观察到以下特征:各主题类别在空间中形成了清晰的分离边界,每个主题内部的句子呈现紧密的聚集分布,表明主题内部具有较高的相似性。虽然在瑜伽和宗教主题之间存在一定程度的重叠,但总体而言,嵌入向量表现出良好的区分性能力。
聚类算法对比分析
基于数据集中已标注的主题信息,我们将对比已知聚类数量和未知聚类数量两种情况下不同算法的性能表现。
1、K-Means聚类算法
K-Means算法适用于数据集规模较大、聚类数量已知、且聚类呈现相似大小和近似球形分布的场景。不推荐在聚类形状和大小存在显著差异、聚类数量未知,或存在大量异常值的情况下使用该算法。
评估指标采用轮廓系数(Silhouette Score)和调整兰德指数(Adjusted Rand Index):
fromsklearn.clusterimportKMeans
fromsklearn.metricsimportsilhouette_score, adjusted_rand_score
# 设置聚类数量(等于数据集中唯一主题的数量)
n_clusters=len(df["topic"].unique())
# 执行K-Means聚类
kmeans=KMeans(n_clusters=n_clusters, random_state=42, n_init=10)
labels=kmeans.fit_predict(embeddings_2d)
# 性能评估
# 轮廓系数计算
sil_score=silhouette_score(embeddings_2d, labels)
print(f"Silhouette Score: {sil_score:.4f}")
# 调整兰德指数计算
# ARI范围为-1到1(1表示完美匹配,0表示随机分配,-1表示完全相反)
ari_score=adjusted_rand_score(df["topic"], labels)
print(f"Adjusted Rand Index (ARI): {ari_score:.4f}")
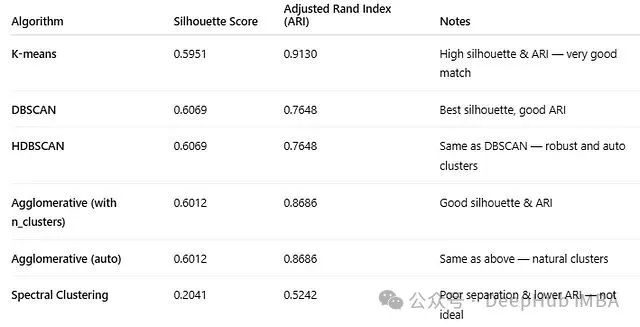
K-Means算法取得了轮廓系数0.5951的成绩,这在0.5-0.7的范围内表示聚类结果具有合理的质量和清晰的分离性。该分数表明数据点与其所属聚类具有良好的匹配度,并与相邻聚类保持明显的区别。调整兰德指数达到0.9130,这是一个相当优秀的成绩。由于ARI将聚类结果与真实主题标签进行对比,0.91的分数意味着算法输出与真实情况高度一致。
2、DBSCAN聚类算法
DBSCAN(基于密度的空间聚类)适用于聚类形状未知、聚类数量未知、存在异常值的场景,特别适合SBERT嵌入向量(默认使用余弦相似度)。该算法不适用于嵌入向量维度过高、需要精确选择eps和min_samples参数、数据集规模极大,或密度变化剧烈的情况。
由于聚类数量未知,结果的可视化展示更有助于理解算法性能:
fromsklearn.clusterimportDBSCAN
fromsklearn.metricsimportsilhouette_score, adjusted_rand_score
dbscan=DBSCAN(eps=2.9, min_samples=5)
labels=dbscan.fit_predict(embeddings_2d)
# 性能评估
# 轮廓系数计算(仅在存在多个聚类时计算,排除噪声点)
n_clusters=len(set(labels)) - (1if-1inlabelselse0)
ifn_clusters>1:
sil_score=silhouette_score(embeddings_2d, labels)
print(f"Silhouette Score: {sil_score:.4f}")
else:
print("Silhouette Score: Only one cluster found (or noise only), silhouette not meaningful.")
# 调整兰德指数计算
ari_score=adjusted_rand_score(df["topic"], labels)
print(f"Adjusted Rand Index (ARI): {ari_score:.4f}")
# DBSCAN聚类结果可视化
plt.figure(figsize=(10, 7))
unique_labels=set(labels)
colors=plt.cm.get_cmap("tab10", len(unique_labels))
forlabelinunique_labels:
indices= [ifori, linenumerate(labels) ifl==label]
iflabel==-1:
# 噪声点标记
plt.scatter(embeddings_2d[indices, 0], embeddings_2d[indices, 1], color="k", label="Noise", alpha=0.4)
else:
plt.scatter(embeddings_2d[indices, 0], embeddings_2d[indices, 1], label=f"Cluster {label}", alpha=0.6, color=colors(label))
plt.legend()
plt.title("DBSCAN Clustering of t-SNE Embeddings")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()
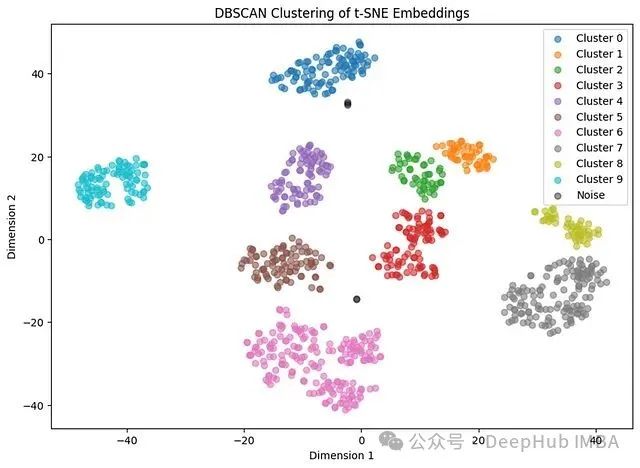
分析结果显示,DBSCAN无法有效区分苹果和橙子与烹饪美食类别,这是基于密度的算法特性所致。类似的情况也出现在其他主题的区分中。轮廓系数达到0.6069,这是一个可靠的分数,表明聚类具有良好的分离性和内部紧密性。调整兰德指数为0.7648,同样是一个相当不错的成绩,表明DBSCAN的聚类结果与实际主题具有较好的对应关系。
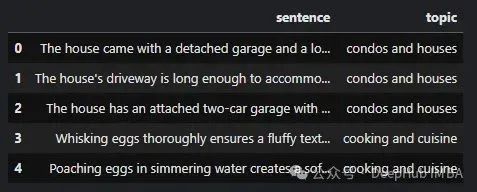
DBSCAN算法标识出的异常值分析如下:
# 异常值索引提取
outlier_indices= [ifori, labelinenumerate(labels) iflabel==-1]
# 获取对应的句子和主题信息
outlier_sentences=df.iloc[outlier_indices]["text"].tolist()
outlier_topics=df.iloc[outlier_indices]["topic"].tolist()
# 构建异常值数据框以便查看
outliers_df=pd.DataFrame({
"sentence": outlier_sentences,
"topic": outlier_topics
})
# 显示异常值
display(outliers_df)
通过调试不同的eps参数值发现,随着eps值的增加,异常值数量减少,但同时聚类数量也会降低,这反过来影响了评估指标的表现。
3、HDBSCAN聚类算法
HDBSCAN(层次DBSCAN)是DBSCAN的扩展版本,通过分层改变密度阈值解决了DBSCAN在eps参数设置上的局限性。该算法关注具有所有可能密度级别的聚类层次结构,而非简单的基于密度的聚类。HDBSCAN适用于聚类具有不同密度分布的场景,但在数据集规模极大时由于计算成本高昂而不推荐使用。
importhdbscan
# HDBSCAN聚类执行
# min_cluster_size参数类似于DBSCAN的min_samples
clusterer=hdbscan.HDBSCAN(min_cluster_size=5, min_samples=4, metric='euclidean')
labels=clusterer.fit_predict(embeddings_2d)
# 性能评估
n_clusters=len(set(labels)) - (1if-1inlabelselse0)
print(f"Number of clusters (excluding noise): {n_clusters}")
# 轮廓系数计算
ifn_clusters>1:
sil_score=silhouette_score(embeddings_2d, labels)
print(f"Silhouette Score: {sil_score:.4f}")
else:
print("Silhouette Score: Only one cluster found (or noise only), silhouette not meaningful.")
# 调整兰德指数计算
ari_score=adjusted_rand_score(df["topic"], labels)
print(f"Adjusted Rand Index (ARI): {ari_score:.4f}")
# 聚类结果可视化
plt.figure(figsize=(10, 7))
unique_labels=set(labels)
colors=plt.cm.get_cmap("tab10", len(unique_labels))
forlabelinunique_labels:
indices= [ifori, linenumerate(labels) ifl==label]
iflabel==-1:
plt.scatter(embeddings_2d[indices, 0], embeddings_2d[indices, 1], color="k", label="Noise", alpha=0.4)
else:
plt.scatter(
embeddings_2d[indices, 0],
embeddings_2d[indices, 1],
label=f"Cluster {label}",
alpha=0.6,
color=colors(label)
)
plt.legend()
plt.title("HDBSCAN Clustering of t-SNE Embeddings")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()

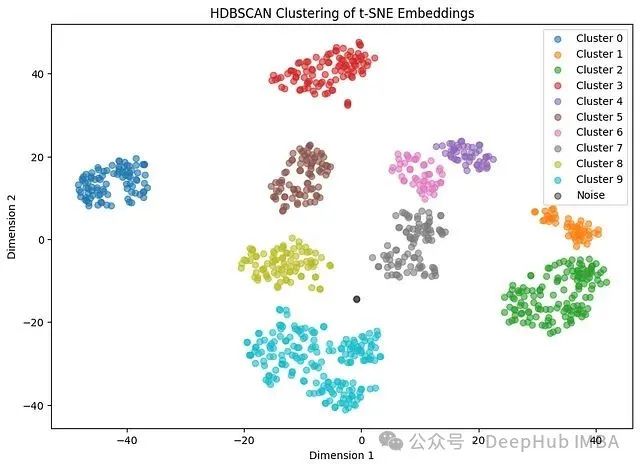
HDBSCAN的性能表现与DBSCAN基本相似,在本案例中生成的聚类结果也大致相同。轮廓系数表现中等,而ARI指标表现良好。
4、凝聚型层次聚类
凝聚型层次聚类通过反复合并最近的聚类对来构建二叉聚类树,每个嵌入向量最初被视为独立的聚类。该算法需要指定距离度量或聚类数量,且不会将任何数据点识别为异常值。适用于不需要异常值检测和聚类数量未知的场景,但不适用于大规模数据集、需要异常值识别,或不可逆合并可能导致问题的情况。
无论指定聚类数量还是指定距离度量,轮廓系数和ARI的结果基本相同。
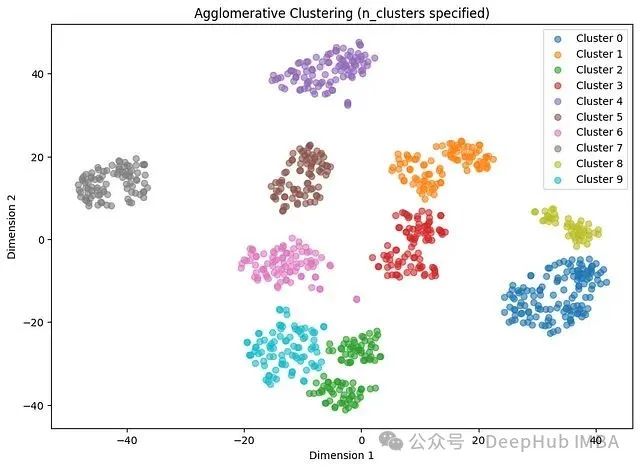
指定聚类数量的情况:
fromsklearn.clusterimportAgglomerativeClustering
# 指定聚类数量
n_clusters=len(df["topic"].unique())
agglo=AgglomerativeClustering(n_clusters=n_clusters)
labels_n_clusters=agglo.fit_predict(embeddings_2d)
# 性能评估
sil_score=silhouette_score(embeddings_2d, labels_n_clusters)
ari_score=adjusted_rand_score(df["topic"], labels_n_clusters)
print("With n_clusters:")
print(f" Silhouette Score: {sil_score:.4f}")
print(f" Adjusted Rand Index (ARI): {ari_score:.4f}")
# 结果可视化
plt.figure(figsize=(10, 7))
forlabelinset(labels_n_clusters):
indices= [ifori, linenumerate(labels_n_clusters) ifl==label]
plt.scatter(embeddings_2d[indices, 0], embeddings_2d[indices, 1], label=f"Cluster {label}", alpha=0.6)
plt.legend()
plt.title("Agglomerative Clustering (n_clusters specified)")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()

指定距离阈值的情况:
agglo_auto=AgglomerativeClustering(distance_threshold=100, n_clusters=None)
labels_auto=agglo_auto.fit_predict(embeddings_2d)
# 自动确定的聚类数量
n_clusters_auto=len(set(labels_auto))
print(f"Without n_clusters: Number of clusters found = {n_clusters_auto}")
# 性能评估
ifn_clusters_auto>1:
sil_score_auto=silhouette_score(embeddings_2d, labels_auto)
print(f" Silhouette Score: {sil_score_auto:.4f}")
else:
print(" Silhouette Score: Only one cluster found, not meaningful.")
ari_score_auto=adjusted_rand_score(df["topic"], labels_auto)
print(f" Adjusted Rand Index (ARI): {ari_score_auto:.4f}")
# 结果可视化
plt.figure(figsize=(10, 7))
forlabelinset(labels_auto):
indices= [ifori, linenumerate(labels_auto) ifl==label]
plt.scatter(embeddings_2d[indices, 0], embeddings_2d[indices, 1], label=f"Cluster {label}", alpha=0.6)
plt.legend()
plt.title("Agglomerative Clustering (distance_threshold)")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()

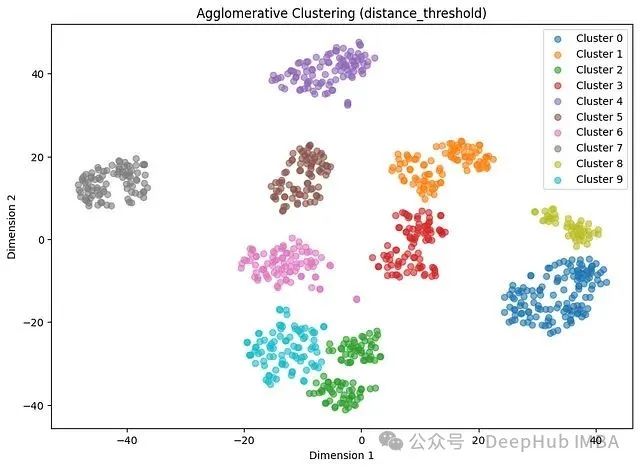
分析结果显示,轮廓系数达到0.6012,调整兰德指数为0.8686。这表明无论指定聚类数量(n_clusters)还是让算法自动发现聚类(distance_threshold),在当前数据集上的聚类结果基本一致。层次聚类算法很好地捕捉了数据的潜在结构特征。
5、谱聚类算法
谱聚类将每个嵌入向量视为图中的节点,通过边连接相似的节点形成语义图。算法构建语义矩阵(邻接矩阵)来度量节点间的距离(相似性),然后生成拉普拉斯矩阵来捕捉每个点与其他点的连接紧密程度。接下来从拉普拉斯矩阵计算特征向量以捕捉数据中的模式,最后应用K-Means等传统聚类算法处理这些模式。谱聚类适用于聚类无法被单一超平面分离且聚类数量不超过5个的场景,但不适用于聚类数量未知和小规模数据集(由于时间和空间复杂度过高)。
fromsklearn.clusterimportSpectralClustering
# 谱聚类执行
spectral=SpectralClustering(
n_clusters=n_clusters,
affinity='nearest_neighbors', # 或使用'rbf'表示高斯核相似度
assign_labels='kmeans', # 最终聚类分配方法
random_state=42
)
labels=spectral.fit_predict(embeddings_2d)
# 性能评估
sil_score=silhouette_score(embeddings_2d, labels)
ari_score=adjusted_rand_score(df["topic"], labels)
print("Spectral Clustering:")
print(f" Silhouette Score: {sil_score:.4f}")
print(f" Adjusted Rand Index (ARI): {ari_score:.4f}")
# 结果可视化
plt.figure(figsize=(10, 7))
forlabelinset(labels):
indices= [ifori, linenumerate(labels) ifl==label]
plt.scatter(embeddings_2d[indices, 0], embeddings_2d[indices, 1], label=f"Cluster {label}", alpha=0.6)
plt.legend()
plt.title("Spectral Clustering of Sentence Embeddings (2D)")
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.show()

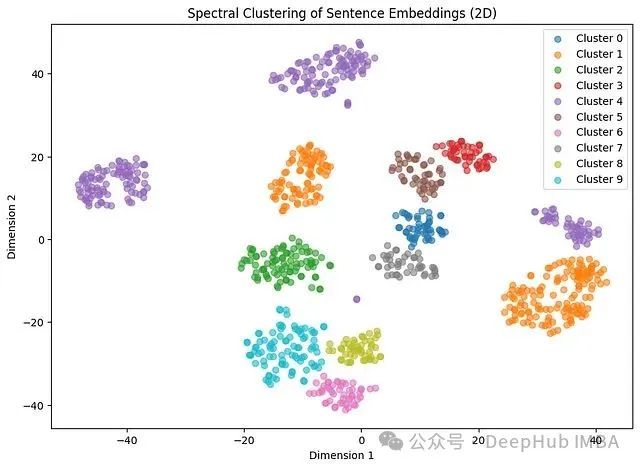
谱聚类的表现相对较差,由于聚类分离度不够理想,其轮廓系数表现不佳。该算法无法为第10号聚类生成有效的标签预测,这表明谱聚类在大多数句子嵌入应用场景中并不适用。
总结
虽然还存在其他聚类算法如BIRCH、Affinity Propagation等,但这些算法在数据集规模、嵌入向量维度和计算成本方面存在显著局限性,因此实用价值有限。本文讨论的算法代表了工业界最广泛应用且具有实际应用价值的聚类方法,除了谱聚类在句子嵌入领域的应用价值有限之外。
基于实验结果,当聚类数量已知时,推荐选择K-Means算法,因为其计算成本相对较低且性能优秀。在聚类数量未知的情况下,基于密度的方法(如DBSCAN和HDBSCAN)以及凝聚型层次聚类是较好的替代方案。算法选择应当结合具体的应用需求、数据特征和计算资源约束进行综合考虑。
作者:Manav Sarkar
