研究人员提出了DPSDP算法,利用多智能体反思强化学习提升大语言模型推理能力,实验证明其在多个基准测试中有效。
原文标题:【ICML2025】通过多智能体反思强化大语言模型推理
原文作者:数据派THU
冷月清谈:
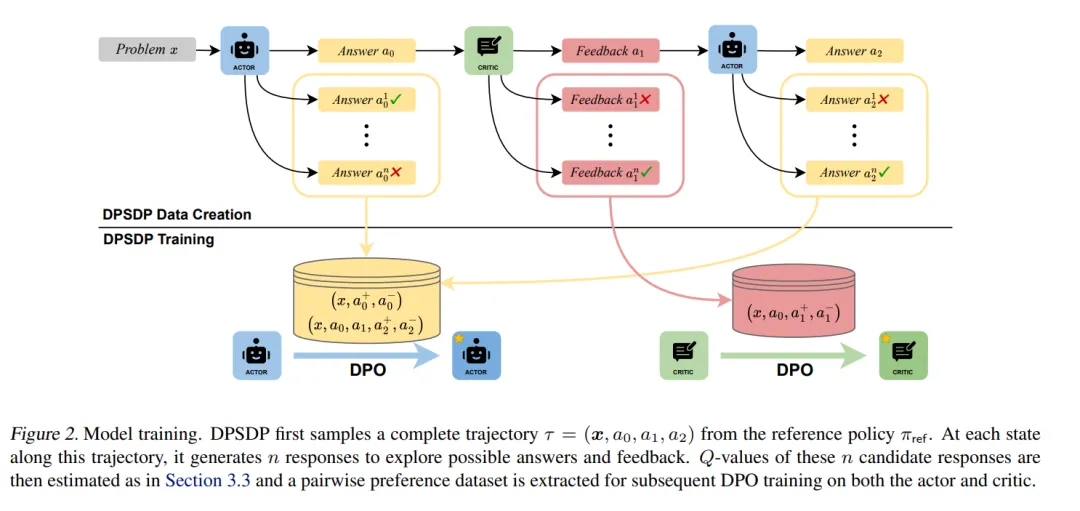
本文介绍了DPSDP(通过动态规划的直接策略搜索)算法,该算法通过将多回合推理过程建模为马尔可夫决策过程,并利用强化学习训练一个演员-评论员大语言模型系统,从而迭代改进答案。DPSDP通过在自生成数据上进行直接偏好学习,克服了传统方法中反馈空间受限和缺乏协调训练的问题。实验结果表明,DPSDP在多个基准测试中显著提升了大语言模型的推理性能,尤其是在内外分布的任务上。该研究还证实了多智能体协作在提高外部分布泛化能力方面的优势。
怜星夜思:
1、DPSDP算法中,将多回合的改进过程建模为马尔可夫决策过程(MDP)是出于什么考虑?相比于直接进行多轮对话有什么优势?
2、文章提到DPSDP通过直接偏好学习改进答案,那么“偏好”是如何定义的?这个偏好是人工标注的吗?
3、文章中提到在MATH 500基准测试中,使用基于Ministral的模型将首次准确率从58.2%提高到63.2%。这个提升幅度在实际应用中有多大意义?
2、文章提到DPSDP通过直接偏好学习改进答案,那么“偏好”是如何定义的?这个偏好是人工标注的吗?
3、文章中提到在MATH 500基准测试中,使用基于Ministral的模型将首次准确率从58.2%提高到63.2%。这个提升幅度在实际应用中有多大意义?
原文内容

来源:专知本文约1000字,建议阅读5分钟通过实证研究,我们使用不同的基础模型实例化DPSDP,并展示了在内外分布基准测试中的改进。

利用更多的测试时计算增强大语言模型推理能力
已证明,利用更多的测试时计算是一种有效的方法,可以提升大语言模型(LLMs)的推理能力。在多种方法中,验证与改进(verify-and-improve)范式尤为突出,因为它使得模型能够进行动态的解决方案探索并整合反馈。然而,现有的方法通常面临反馈空间受限和缺乏不同方协调训练的问题,导致性能不尽如人意。为了应对这一挑战,我们将这一多回合的改进过程建模为一个马尔可夫决策过程(MDP),并引入了DPSDP(通过动态规划的直接策略搜索),一种强化学习算法,它训练一个演员-评论员(actor-critic)大语言模型系统,通过在自生成数据上进行直接偏好学习,迭代地改进答案。
从理论上讲,DPSDP能够在训练分布内匹配任何策略的性能。通过实证研究,我们使用不同的基础模型实例化DPSDP,并展示了在内外分布基准测试中的改进。例如,在MATH 500基准测试中,通过五轮改进步骤进行多数投票,使用基于Ministral的模型将首次准确率从58.2%提高到63.2%。一项消融研究进一步确认了多智能体协作和外部分布泛化的优势。
主要贡献
-
方法创新:提出了DPSDP算法,将多回合的推理过程建模为马尔可夫决策过程,并通过直接偏好学习进行答案改进。
-
性能提升:在多个基准测试中,DPSDP方法显著提升了大语言模型的推理性能,尤其是在内外分布的任务上。
-
多智能体协作:通过多智能体协作,进一步验证了该方法在面对复杂推理任务时的优势,尤其是在提高外部分布的泛化能力上。