上海交大&阿里提出时序基模后训练新范式:先剪枝再微调,有效减少模型参数,提升预测精度。研究揭示模型稀疏性和冗余性,为时序基模应用提供新方向。
原文标题:时序大模型参数减少预测更好?上海交大、阿里推出时序基模后训练新范式
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到“时序基模出色的零样本性能得益于只选择一部分下游任务相关的参数参与计算”,那么这种选择参数的机制是如何实现的?能否进一步解释一下,这种机制对于提升零样本性能的具体作用?
3、文章提出的“先剪枝再微调”范式,在实际应用中可能面临哪些挑战?例如,如何选择合适的剪枝比例?剪枝过程是否会破坏模型的泛化能力?
原文内容

来源:时序人本文约3000字,建议阅读5分钟时序基模是否足够优越于传统基线?
大规模预训练是近期时序领域的研究热点,涌现了一批时序预测基础模型(简称:时序基模,Time Series Foundation Model)。这类预训练模型可以不经微调直接应用于下游数据集,取得不错的零样本(zero-shot)预测表现。不过,实际生产中时序数据会不断新增,不需人工标注即可为时序预测积累出充足训练样本。因此,有必要在全样本(full-shot)场景下审视:时序基模是否足够优越于传统基线?
最近,来自上海交大和阿里的研究者发现公平比较下,时序基模即便经过微调也依然难以在常用基准上显著优于基线 PatchTST,专业化时序基模成为关键难题。为此,研究者们提出了“先剪枝再微调”的后训练(post-training)范式,移除不重要的网络结构,让微调专注于与下游任务相关、更紧凑的参数子空间。实验中,研究者实现了“Less is More”的效果:7种时序基模裁减掉一半参数,只微调剩余参数,取得了比微调完整预训练模型更低的预测误差,在6项基准数据集上将时序基模对 PatchTST 的胜率提高到了 100%。

【论文标题】
Less is More: Unlocking Specialization of Time Series Foundation Models via Structured Pruning
【论文地址】
https://arxiv.org/pdf/2505.23195
实验发现
研究者以 Weather 和 ETTm1 数据集为例,对 TTM-A、Time-MoE、Moirai、Chronos-bolt-base、TimesFM 等最新的时序基模进行实验分析,得到了三点重要观察。
01 观察一:现有时序基模难以稳定优于传统基线
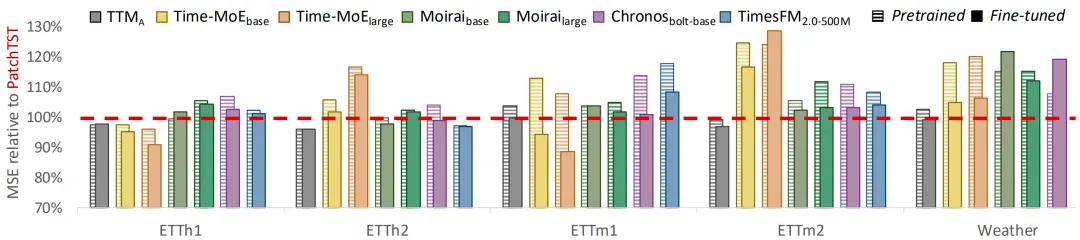
图1 与全样本训练的PatchTST(红线)相比,时序基模预测96、192、336、720步的平均相对Test MSE(%)
如图1所示,Chronos等流行的时序基模参数规模虽大,但零样本预测误差(Pretrained)经常高于从头训练的PatchTST,不能彻底克服预训练数据和下游数据之间的数据分布差异。即便经过微调提升表现,时序基模全样本性能(Fine-tuned)仍然无法取得显著优势。
这并不否认预训练的价值(毕竟零样本场景表现不错),只是说明缺少更好的手段有效利用预训练好的时序基模。为了有效适配下游任务,首先需要解答的是:预训练提供了什么值得保留的先验知识?为此,研究者在下文中进一步分析了时序基模的内在机制。
02 观察二:时序基模的计算存在稀疏性
对于基于Transformer的时序基模,研究者统计了每个attention head在整个下游数据集上的平均相对输出模长,定义为 其中 表示第i个头的单个输出向量, 表示对应token所在注意力层的输入残差。
如图2所示,相比于PatchTST模型,Moirai、Time-MoE等基模有很多attention head对残差只做了微小的改动(例如相对模长<1%)。
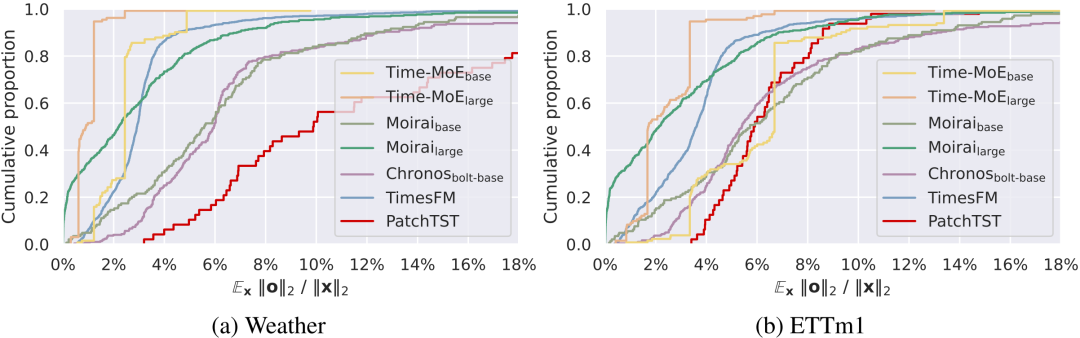
图2 不同平均相对输出模长下的注意力头累计占比
对于每个 FFN 层,研究者统计了每个中间通道在整个下游数据集上的激活概率,即激活值大于0所占的比例。
如图3所示,相比于PatchTST至少20%的FFN通道被激活,预训练的时序基模呈现稀疏激活的特性,例如Chronos和Time-MoE有20-60%的FFN通道从未在下游数据上被激活。如果将激活概率小于5%的中间通道定义为稀疏通道,如图4所示,许多时序基模的各层FFN存在数量相当可观的稀疏通道,特别是Chronos的数层FFN只有5%的通道经常被使用。值得注意的是,Chronos等模型没有实现Sparse MoE的模型结构设计,但模型通过预训练也能学会稀疏计算,因此继续开发其MoE版本或许没有太大价值。
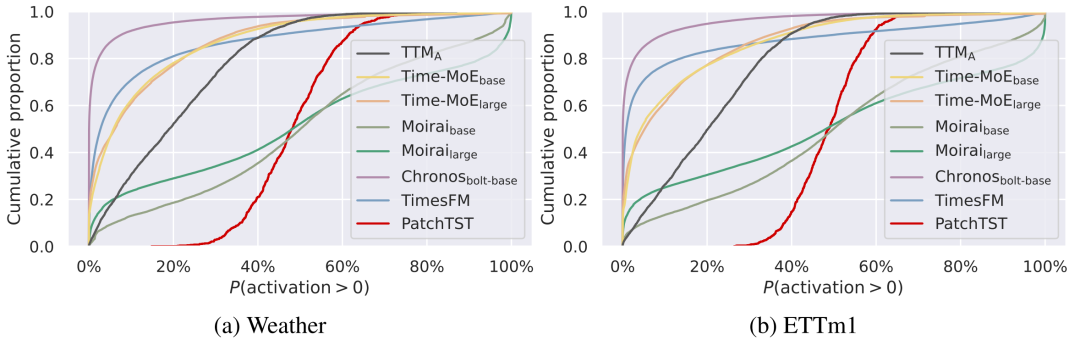
图3 不同激活概率的FFN中间通道累计占比
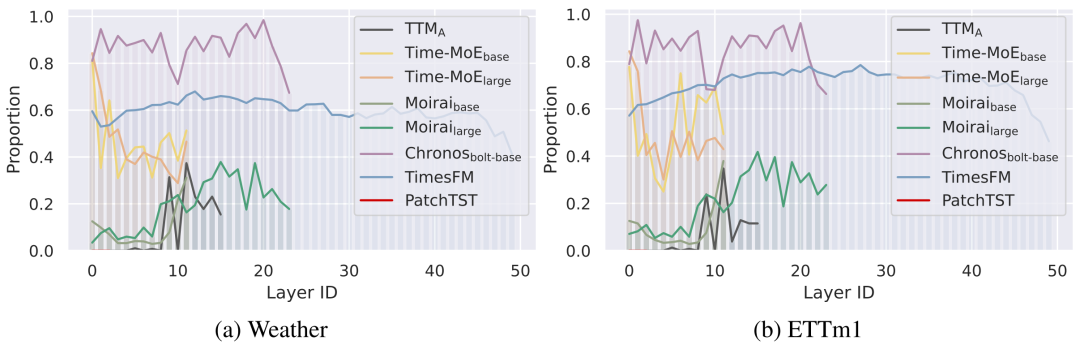
图4 不同FFN层的稀疏通道占比
总体来看,预训练模型越大,稀疏性越强;不同下游数据上有不同的稀疏分布,有不同的参数被激活。研究者认为,时序基模出色的零样本性能得益于只选择一部分下游任务相关的参数参与计算,这是预训练中获得的有效先验知识。
03 观察三:时序基模的参数存在冗余性
为了更全面地发现模型中任务无关的参数,研究者进一步着眼于任意线性变换层的输入和输出通道。如果移除某个通道(输出值始终mask为0)不会导致显著的预测误差变化,可以说明该通道在模型中是冗余的。因此,研究者将各通道的重要性分数定义为原模型预测误差和移除该通道后预测误差之间的变化绝对值,然后基于二阶泰勒展开进行高效估计。低重要性分数囊括了此前讨论的稀疏情况,因为如果某通道输出经常微乎其微,那么其重要性分数自然很小。
在图5的统计结果中,相比于PatchTST,所有时序基模只有极少数通道比较重要,其他大部分通道单独移除后不会引起明显的预测损失变化,对模型来说是冗余的。这符合时序预测的天然特性:由于概念漂移,大量时序模式会短暂出现并衰退,只有很少的潜在特征能够保持长期有效性,没有必要挖掘高度复杂的时序因子。
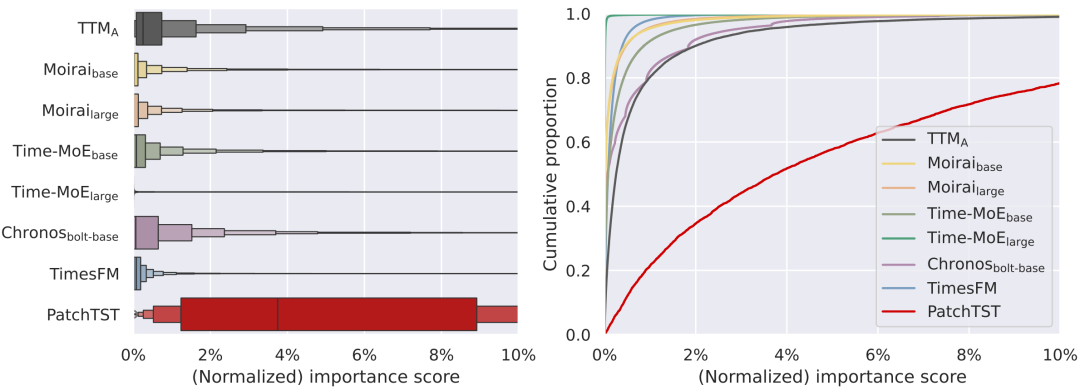
图5 通道重要性分数的(左)箱线图和(右)累计占比图
先剪枝再微调
研究者认为,时序基模的稀疏性和冗余性是预训练中习得的、关于时序预测的宝贵先验知识,不应该在微调中被干扰;否则,微调所有模型参数权重容易出现过拟合问题,过度挖掘了大量过时因子或噪声信号。
因此,研究者将时序基模专业化解耦为两个阶段:结构专业化和权重专业化。其中,结构专业化可以通过一套简单但有效的结构化剪枝方法来实现:从下游训练集采样数据并进行时序预测,评估各通道重要性分数,移除最不重要的少量通道,下一批次数据上重新评估未剪枝通道的重要性分数,结合上一次的分数进行指数滑动平均(EMA),继续进行剪枝......直至一个epoch结束或者剪枝模型在验证集上性能下降。剩下未被剪枝的模型参数放到训练集上进行参数权重微调。
实验效果
01 全样本预测性能对比
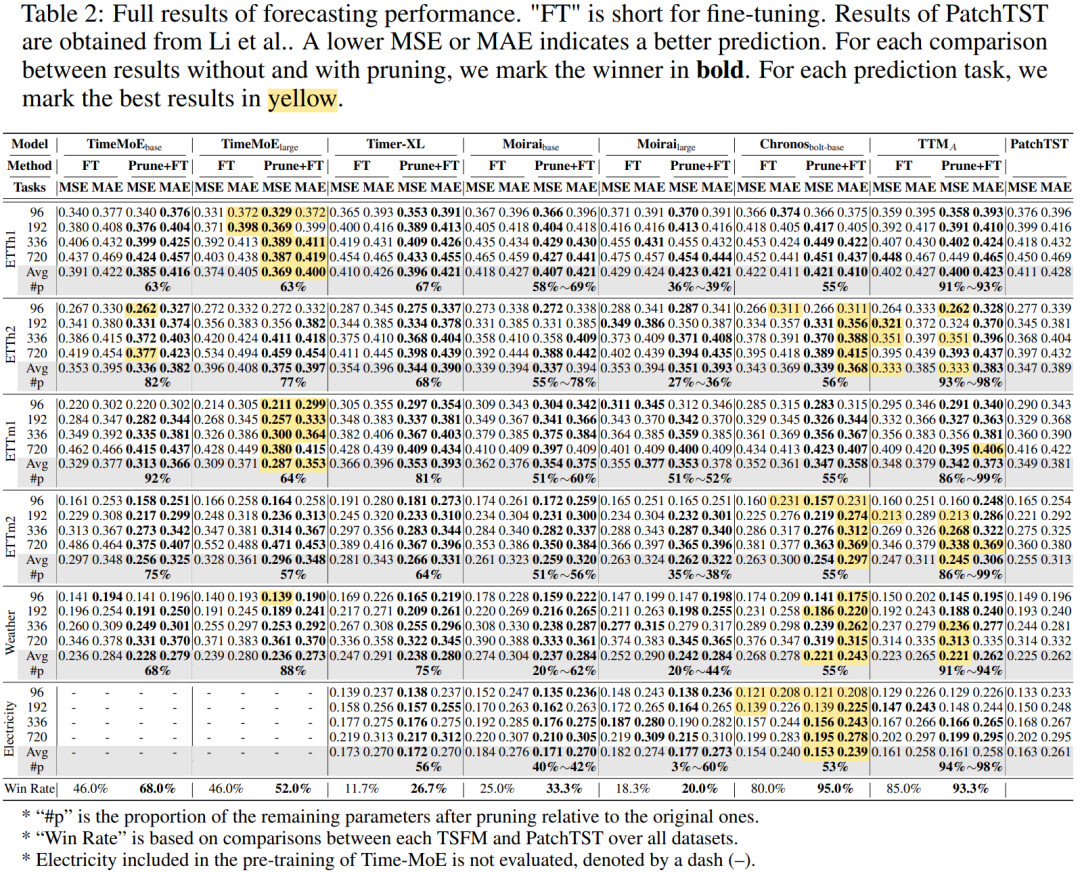
研究者在 ETT、Weather、Electricity 等常用基准数据集上执行了长期预测的实验。如 Table 1 所示,先剪枝再微调在大部分任务上相比传统微调取得更低的预测误差,最高可以相对降低 22% 的 MSE。新的后训练范式下,各基准上最优时序基模相比 PatchTST 的胜率从90%提高到了100%,验证了所提方法的优越性。在剪枝结果上,大部分模型被裁减了 40-60% 的参数数量;作为特例,Moirai-large 甚至在 Electricity 上被裁剪了 97% 的参数,但依然能够取得更好的预测性能;相比之下,TTM 只有 5M 参数,因此无法大量剪枝。
02 可迁移性
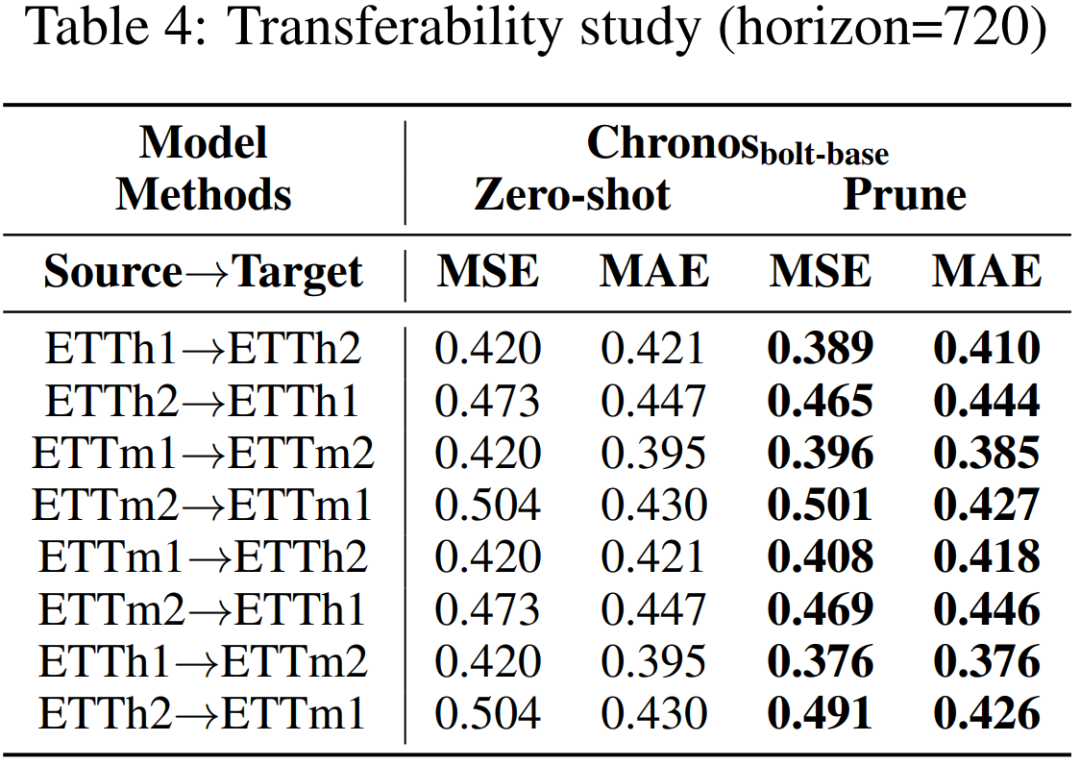
Table 4 展示了使用 Source 数据集剪枝后模型在另一 Target 数据集上的迁移效果。当使用同一领域的时序数据,即便时序频率不同,剪枝后的模型在 Target 数据上显著优于零样本预测水平,验证了所提模型结构专业化的有效性。在数据稀缺等冷启动场景下,或许可以借用其他相似数据进行时序基模后训练。
总结
这篇工作揭示了预训练时序基模在下游数据上的适应难题,强调了时序基模后训练阶段的必要性。通过观察时序基模内在的稀疏性和冗余性,研究者认为激活任务相关的子网络是时序大规模预训练提供的先验知识,可以作为微调的良好起点。研究者率先探索了时序基模的剪枝方法,所提出的“先剪枝再微调”范式有效激发了时序基模的专业化潜力,提供了应用时序基模的新手段和新研究方向。
编辑:文婧

