Meta发布V-JEPA 2世界模型,LeCun亲自介绍,提升AI环境理解与预测,实现零样本规划与机器人控制。
原文标题:刚刚,LeCun亲自出镜,Meta推出新世界模型!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Meta发布的三个基准测试,IntPhys 2、MVPBench 和 CausalVQA,分别侧重于物理世界的不同理解维度。你认为哪个基准测试对未来AI的发展更具挑战性?为什么?
3、V-JEPA 2目前主要关注视觉信息的处理,Meta未来计划探索多模态JEPA模型。你认为除了视觉之外,哪些感官信息(例如听觉、触觉)对提升世界模型的理解能力至关重要?如何有效地融合这些多模态信息?
原文内容
机器之心编辑部
最近,Meta 大动作不断。
前些天有外媒曝出马克・扎克伯格正在组建一个名为「超级智能团队」的专家团队,以实现通用人工智能。随后开出 9 位数的薪酬为该团队吸纳人才。
就在刚刚,Meta 又有新的动作,推出基于视频训练的世界模型 V-JEPA 2(全称 Video Joint Embedding Predictive Architecture 2)。其能够实现最先进的环境理解与预测能力,并在新环境中完成零样本规划与机器人控制。
Meta 表示,他们在追求高级机器智能(AMI)的目标过程中,关键在于开发出能像人类一样认知世界、规划陌生任务执行方案,并高效适应不断变化环境的 AI 系统。
这次,Meta 首席 AI 科学家 Yann LeCun 亲自出镜,介绍世界模型与其他 AI 模型的不同。
他说,世界模型是一种现实的抽象数字孪生,AI 可以参考它来理解世界并预测其行为的后果。与理解语言不同,世界模型使机器能够理解物理世界,并能够规划行动路线以完成任务,而无需进行数百万次的试验,因为世界模型提供了对世界运行方式的基本理解。能够使用世界模型进行推理和规划的 AI 将产生广泛影响。例如,它可以用于帮助视障人士的辅助技术、在混合现实中为复杂任务提供指导、使教育更加个性化,甚至可以理解代码对程序状态和外部世界的影响。
此外,世界模型对于自动驾驶汽车和机器人等自主系统至关重要,它将开启机器人技术的新纪元,使现实世界中的 AI 智能体能够在不需要大量机器人训练数据的情况下帮助完成家务和体力任务。
V-JEPA 2 拥有 12 亿参数,基于联合嵌入预测架构(JEPA)构建。在此之前,Meta 已经证明,JEPA 架构在处理图像和 3D 点云等模态方面出色的表现。
此次发布的 V-JEPA 2 是在去年首个基于视频训练模型 V-JEPA 的基础上,进一步提升了动作预测和世界建模能力,使机器人能够通过与陌生物体及环境交互来完成任务。
我们先看几个示例:
开启对世界的理解。V-JEPA 2 与语言建模相结合,可提供卓越的运动理解以及领先的视觉推理能力。当视频中的人跳向水面时,V-JEPA 2 给出了解读:向前,1.5 周空翻,无转体。

预测下一步会发生什么。V-JEPA 2 可以预测世界将如何发展。示例中,当人正在做当前事情时,V-JEPA 2 能够预测接下来会发生什么。
下面是 V-JEPA 2 的一些性能指标:
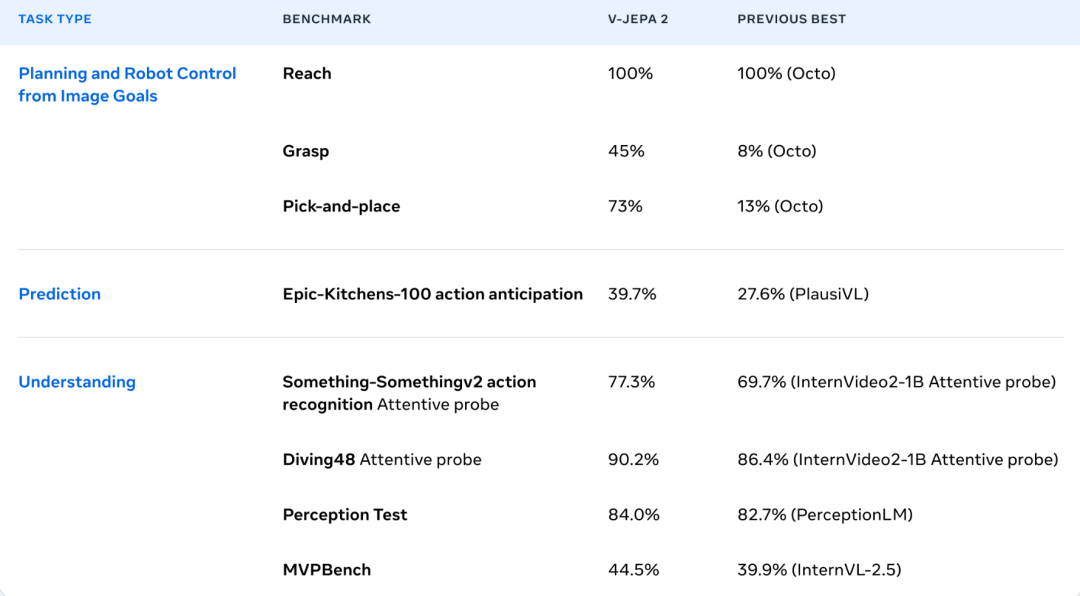
目前,V-JEPA 2 相关论文、下载链接等已经放出。

-
论文标题:V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
-
论文链接:https://ai.meta.com/research/publications/v-jepa-2-self-supervised-video-models-enable-understanding-prediction-and-planning/
-
项目链接:https://github.com/facebookresearch/vjepa2
-
HuggingFace 链接:https://huggingface.co/collections/facebook/v-jepa-2-6841bad8413014e185b497a6
-
项目网站:https://ai.meta.com/vjepa/
V-JEPA 2 有哪些创新?
V-JEPA 2 基于 JEPA 构建,包含两个主要组件:
-
编码器,用于接收原始视频并输出嵌入,这些嵌入能够捕捉世界状态的语义信息。
-
预测器,用于接收视频嵌入以及关于预测内容的附加上下文,并输出预测后的嵌入。
在训练过程中,Meta 使用基于视频的自监督学习来训练 V-JEPA 2,因而无需额外的人工注释即可在视频上进行训练。
V-JEPA 2 训练包含两个阶段:无动作预训练,以及后续的动作条件训练。
在第一阶段 —— 预训练阶段,Meta 使用了超过 100 万小时的视频和 100 万张图像。这些丰富的视觉数据有助于模型深入了解世界的运作方式,包括人与物体的交互方式、物体在物理世界中的移动方式以及物体与其他物体的互动方式。
仅仅经过预训练,Meta 就发现模型已经展现出与理解和预测相关的关键能力。例如,通过在冻结编码器和预测器特征的基础上训练注意力读出(read-out)模型,V-JEPA 2 在 Epic-Kitchens-100 动作预测任务中创造了新的最高纪录,该任务可以根据以自我为中心的视频预测未来 1 秒将执行的动作(由名词和动词组成)。最后,将 V-JEPA 2 与语言模型相结合,可以在视频问答基准(例如感知测试和 TempCompass)上实现最先进的性能。
在第一阶段之后,模型能够预测世界状态的可能演变。然而,这些预测并没有直接考虑智能体将采取的具体行动。
因而,在训练的第二阶段,Meta 专注于利用机器人数据(包括视觉观察(视频)和机器人正在执行的控制动作)来提升模型的规划能力。
Meta 通过向预测器提供动作信息,将这些数据整合到 JEPA 训练流程中。在使用这些额外数据进行训练后,预测器学会在进行预测时考虑具体动作,然后即可用于控制。
第二阶段的训练不需要大量的机器人数据 —— 仅使用 62 小时的机器人数据进行训练就能构建出一个可用于规划和控制的模型。
Meta 展示了 V-JEPA 2 如何用于在新环境中进行零样本机器人的规划,这些环境中涉及的物体在训练阶段从未见过。与其他机器人基础模型不同 —— 这些模型通常需要部分训练数据来自模型部署的具体机器人实例和环境 —— 他们使用开源的 DROID 数据集对模型进行训练,然后直接将其部署到 Meta 实验室的机器人上。他们证明了 V-JEPA 2 的预测器可以用于基础任务,例如够到物体、拿起物体,并将其放置到新位置。
对于短期任务,例如拿起或放置物体,Meta 以图像的形式指定目标。他们使用 V-JEPA 2 的编码器获取当前状态和目标状态的嵌入向量。从其观察到的当前状态出发,机器人通过预测器来想象采取一组候选动作的后果,并根据这些动作与期望目标的接近程度对候选动作进行评分。在每个时间步,机器人通过模型预测控制重新规划,并执行评分最高的下一个动作以接近目标。
对于长期任务,例如拿起物体并将其放置到正确的位置,他们指定了一系列视觉子目标,机器人会按顺序尝试实现这些子目标,类似于人类观察到的视觉模仿学习。通过这些视觉子目标,V-JEPA 2 在新环境和未见环境中放置新物体的成功率达到了 65% 到 80%。
对物理理解进行基准测试
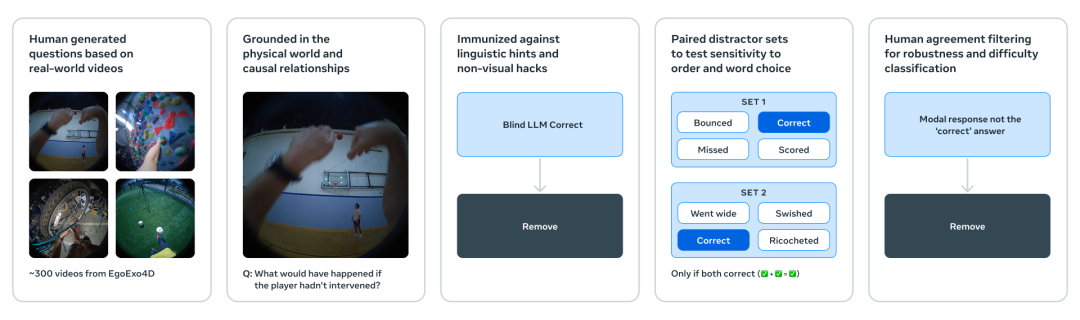
这次,Meta 还发布了三个新的基准测试,用于评估现有模型从视频中理解和推理物理世界的能力。尽管人类在这三个基准测试中的表现都非常出色(准确率在 85% 到 95% 之间),但包括 V-JEPA 2 在内的顶级模型与人类表现之间仍存在显著差距,这表明模型需要在这些方向上进一步改进。
第一个基准测试 ——IntPhys 2 专门设计用于衡量模型区分物理合理场景和不合理场景的能力,它是基于早期的 IntPhys 基准测试进行构建和扩展的。他们设计 IntPhys 2 的方式类似于发展认知科学家评估年幼人类何时获得直觉物理能力的方法,即通过「违背预期」范式。他们通过游戏引擎生成视频对来实现这一点,其中两个视频在某个时间点之前完全相同,然后其中一个视频中发生了违反物理规律的事件。模型必须识别出哪个视频中发生了违反物理规律的事件。尽管人类在各种场景和条件下几乎都能完美完成这项任务,但他们发现当前的视频模型表现仅接近随机水平。

-
IntPhys 2 项目链接:https://github.com/facebookresearch/IntPhys2
-
HuggingFace 链接:https://huggingface.co/datasets/facebook/IntPhys2
-
论文链接:https://ai.meta.com/research/publications/intphys-2-benchmarking-intuitive-physics-understanding-in-complex-synthetic-environments/
第二个基准测试 ——MVPBench 通过多项选择题来衡量视频语言模型的物理理解能力。与文献中的其他视频问答基准测试不同,MVPBench 旨在减少视频语言模型中常见的捷径解决方案,例如依赖于表面的视觉或文本线索和偏见。MVPBench 中的每个示例都有一个最小变化对:一个视觉上相似的视频,以及相同的问题,但答案相反。为了正确回答一个问题,模型还必须正确回答其对应的最小变化对。

-
MVPBench 项目链接:https://github.com/facebookresearch/minimal_video_pairs
-
HuggingFace 链接:https://huggingface.co/datasets/facebook/minimal_video_pairs
-
论文链接:https://ai.meta.com/research/publications/a-shortcut-aware-video-qa-benchmark-for-physical-understanding-via-minimal-video-pairs/
第三个基准测试 ——CausalVQA 旨在关注模型对物理世界视频中因果关系的理解,包括反事实(如果…… 会发生什么)、预期(接下来可能会发生什么)和计划(为了实现目标应该采取什么行动)。
Meta 发现,虽然大型多模态模型越来越能够回答视频中发生了什么的问题,但它们仍然难以回答可能发生什么和接下来可能会发生什么的问题,这表明在预测物理世界在给定动作和事件空间的情况下可能如何演变方面,它们的表现与人类存在巨大差距。
-
CausalVQA 项目链接:https://github.com/facebookresearch/CausalVQA
-
论文链接:https://ai.meta.com/research/publications/causalvqa-a-physically-grounded-causal-reasoning-benchmark-for-video-models/
V-JEPA 2 在 Hugging Face 关于物理推理榜单上排名第一,超越 GPT-4o 等。
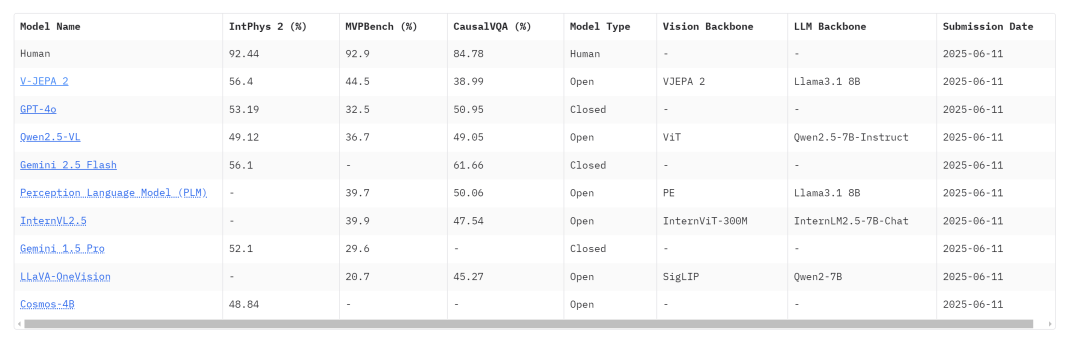
地址:https://huggingface.co/spaces/facebook/physical_reasoning_leaderboard
Meta 下一步会做什么
Meta 计划在多个领域进一步探索世界模型。目前,V-JEPA 2 能够在单一时间尺度上进行学习和预测。然而,许多任务需要跨多个时间尺度进行规划。想象一下,将一个高级任务分解成更小的步骤,例如装载洗碗机或烘烤蛋糕。Meta 希望专注于训练能够跨多个时间和空间尺度进行学习、推理和规划的分层 JEPA 模型。另一个重要方向是多模态 JEPA 模型,这些模型能够利用多种感官进行预测,包括视觉、听觉和触觉。
期待 Meta 接下来的更多研究。
参考链接:
https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com