MMUnlearner提出细粒度的多模态大模型遗忘方案,通过解耦视觉-文本知识,在遗忘特定视觉信息的同时,保留通用视觉感知和文本知识。
原文标题:ACL 2025 | MMUnlearner解耦视觉-文本知识,多模态大模型遗忘进入细粒度时代
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到未来可以构建更强 benchmark,大家觉得高质量、真实场景的大规模多模态遗忘 Benchmark 应该包含哪些要素?
3、除了文章中提到的视觉、文本、音频、视频,未来 MLLM Unlearning 还可能应用在哪些模态上?又会面临哪些新的挑战?
原文内容

1、LLM Unlearning“阴影”下的多模态Unlearning
多模态大模型(MLLM)的兴起极大拓展了AI系统在视觉语言理解、生成等领域的能力。然而,这些模型训练过程中往往利用了大规模未经筛选的多模态数据,潜藏着严重的的隐私与版权风险。由于重新训练 MLLM 成本高昂且不可行,机器遗忘(Machine Unlearning, MU)成为解决该问题的有效方案。
MU 的目标是:在不重训的前提下,使模型有效忘记某些特定数据的影响,同时保留其余知识的完整性。尽管面向文本大模型的 MU 已有诸多进展,但直接套用其策略到 MLLM,无法充分考虑视觉模态的特殊性,因此成效有限。
同时,将纯文本的遗忘 loss 直接迁移到 VQA 数据,也使得 MLLM Unlearning 任务始终处于 LLM 遗忘算法的“阴影”下,不利于发展针对多模态模型的遗忘算法。
2、MLLM Unlearning:重新定义针对MLLM的多模态遗忘任务

论文标题:
MMUnlearner: Reformulating Multimodal Machine Unlearning in the Era of Multimodal Large Language Models
论文链接:
https://arxiv.org/abs/2502.11051
代码地址:
https://github.com/Z1zs/MMUnlearner
作者单位:
港科大(广州)、港科大、同济大学

传统的 MLLM Unlearning 方案通常仅针对 VQA 格式的数据采用 LLM 原有的遗忘损失函数,忽略了视觉模态中文本概念-图像特征关联这一关键点——即 MLLM 本质上是在视觉模式(如特朗普面部特征)与 LLM 原有文本知识(如特朗普百科知识)之间建立了关联。
为此,MMUnlearner 提出一种细粒度的针对 MLLM 的遗忘任务定义:
-
视觉遗忘:去除与特定实体相关的视觉图样(Visual Pattern);
-
通用感知:保留通用及无关视觉概念的感知能力。
-
文本知识:保留 LLM 模块本身的文本知识,这部分知识并非从 Visual Instruction Tuning 中获得。

上述任务可以形式化定义为:
I. 视觉模态中的目标遗忘(Forgetting )
模型应无法识别图像中与概念 相关的内容,即:

其中 是图像中关于 的提问, 为其正确答案。
II. 通用视觉感知能力的保留
模型应保留其关于 的文本知识,即:

其中 是关于 的文本问题, 为其正确答案。
III. 模型内部 LLM 知识的保留
模型应保留其关于 的文本知识,即:

其中 是关于 的文本问题, 为其正确答案。
3、MMUnlearner:基于重要性约束的选择性梯度上升方案
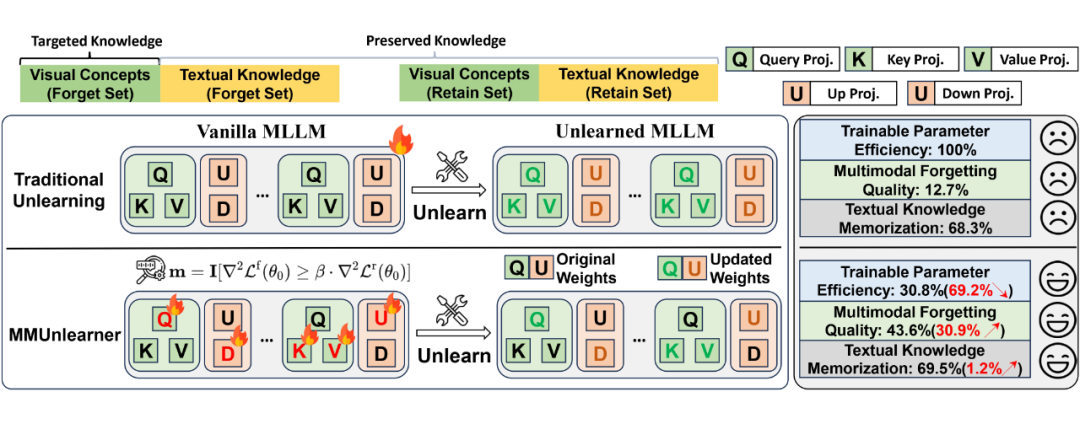
MMUnlearner 的核心是基于重要性约束下的选择性梯度上升(Geometry-Constrained Gradient Ascent)策略,其核心思想如下:
1. 选择性更新目标函数:

其中 是一个基于参数重要性的掩码, 表示逐元素乘法。
2. 重要性评估 - 基于梯度的重要性矩阵:

通过梯度的平方衡量每个参数在不同数据集(遗忘集 与保留集 )中的重要性。
3. 目标与保留数据集定义:
为实现精细的选择性更新,我们首先定义目标概念的遗忘数据集 以及需被保留的参考数据集 如下:
目标数据集(Forget Set):

表示包含概念 的图像、与其相关的视觉提问 及其答案 的组合。
保留数据集(Preserve Set):

包括三部分:
1. 关于 的文本问答对,用于保留 LLM 中的文本知识;
2. 无关概念 的视觉问答对,用于保留非目标视觉感知;
3. 的文本问答对,用于保留其他文本知识。
4. 掩码生成:

表示当某参数对目标知识(遗忘集)更为敏感时才更新,从而最大程度保护非目标参数。
此策略确保仅更新与目标视觉概念强关联的参数,避免破坏模型对保留内容的记忆。
4、实验结果:传统方法的困境与MMUnlearner的优势

在 MLLMU-Bench 和 CLEAR 两个多模态遗忘基准上,MMUnlearner 在两类主流 MLLM(LLaVA-1.5-7B 与 Qwen2-VL-7B)上表现显著优越:
-
Forget VQA Accuracy 降低最多:遗忘视觉概念最彻底;
-
Retain QA / VQA 保留性强:较小的精度下降,证明其保留能力;
-
Forget QA 准确度保持高水平:有效保留了 LLM 模块中的文本知识;
-
事实上,将针对 LLM 的遗忘算法迁移到 VQA 数据上往往只能有效消除文本知识,对视觉模式的遗忘则效果平平。

示例对比:对于一张“建筑师”的照片,传统方法仍回答 “architect”,而 MMUnlearner 成功“遗忘”为 “marine biologist”。

更多案例:相比于基于 LLM 的遗忘算法,MMUnlearner 在遗忘目标视觉知识的同时,也保留了通用的视觉感知和流畅的文本生成能力。

在不同遗忘比例(5%、10%、15%)下,MMUnlearner 在多个维度展现出优越的遗忘-保留权衡能力:
-
随 Forget Ratio 增加,遗忘能力依旧保持:在不同遗忘率下都能保持较好的遗忘效果;
-
Forget QA 成绩反而提升:高遗忘比下仍能保留甚至增强对文本知识的表达;
-
Retain QA 表现领先:在多项任务中文本保留效果优于所有基线;
-
Real-world QA 波动最小:遗忘过程中对通用文本理解影响极小,泛化能力强。
5、任重道远:MLLM Unlearning的未来道路
MMUnlearner 仅仅迈出了探索 MLLM 遗忘问题的一小步,未来还可以从以下几个方面拓展:
-
更强 benchmark 构建:高质量、真实场景的大规模多模态遗忘 Benchmark(这同时也是几位审稿人最关心,社区最急需的问题);
-
更精准的遗忘度量指标:单独评估视觉与文本模态的遗忘程度;
-
跨模态知识定位与剪辑机制:探索如何更细粒度地控制不同模态间的知识存储与传播;
-
适配更多模态:音频、视频等形式的多模态遗忘任务仍属空白。
