CVPR 2025 Highlight 论文 AdaCM2 提出了一种新的跨模态自适应记忆压缩框架,用于解决超长视频理解中的内存和信息冗余问题。
原文标题:CVPR 2025 Highlight|AdaCM2:首个面向超长视频理解的跨模态自适应记忆压缩框架
原文作者:机器之心
冷月清谈:
怜星夜思:
2、AdaCM2 通过跨模态注意力来压缩视频信息,只保留对文本提示最有意义的视觉 Token。那么,如果文本提示本身存在歧义或噪声,会不会导致模型提取错误的信息?有什么方法可以缓解这个问题?
3、AdaCM2 在实验中展现了强大的性能,但在实际应用中,超长视频往往包含更复杂的内容和更高的噪声。你认为 AdaCM2 在实际应用中可能面临哪些挑战?
原文内容

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。
近年来,大语言模型(LLM)持续刷新着多模态理解的边界。当语言模型具备了「看视频」的能力,视频问答、视频摘要和字幕生成等任务正逐步迈入真正的智能阶段。但一个现实难题亟待解决——如何高效理解超长视频?
为此,来自得克萨斯大学阿灵顿分校(UTA)计算机系研究团队提出了 AdaCM2:首个支持超长视频理解的跨模态记忆压缩框架。该研究已被 CVPR 2025 正式接收,并荣获 Highlight 论文(接收率为 3%),展示出其在技术创新与实际价值上的双重突破。

-
论文标题:AdaCM2: On Understanding Extremely Long-Term Video with Adaptive Cross-Modality Memory Reduction
-
论文地址:https://arxiv.org/pdf/2411.12593
背景:LLM 强大,长视频理解却步
多模态视频理解模型如 VideoLLaMA、VideoChat 等已经在短视频(5–15 秒)场景中表现优异,能够回答关于视频内容的自然语言问题。但当视频长度扩展至分钟级甚至小时级,模型的显存瓶颈和冗余信息干扰问题暴露无遗:
-
内存消耗呈指数级上升,难以部署;
-
视觉 Token 冗余严重,导致关键信息被淹没;
-
文本与视频之间缺乏精准对齐机制。
AdaCM2 正是为解决这些核心问题而生。

提出动机:两大关键观察揭示「压缩冗余」的机会
AdaCM2 的提出建立在对视频与文本交互过程中的两个核心观察基础上,揭示了现有模型在超长视频场景下的内在局限:

观察一:帧内注意力稀疏性(Intra-Frame Sparsity)
在长视频的任意一帧中,只有极少数视觉 Token 对当前文本提示具有强相关性。绝大多数视觉信息对于回答文本问题(如「她在和谁说话?」)是无关的。实验发现,这些注意力得分呈现出尾部偏置分布,意味着高价值信息集中在少数 Token 中。
启发: 可以有选择性地仅保留「重要的」视觉 Token,而无需一视同仁处理全部帧内容。
观察二:层间语义冗余性(Layer-Wise Redundancy)
研究还发现,在深层网络中,临近帧之间的跨模态注意力相似度非常高,甚至在间隔较远的帧之间也存在冗余。这种高相似性意味着:多个 Token 在不同时间或不同层次上表达了重复的语义信息。
启发: 应该在不同层次上使用差异化的压缩策略,从而动态平衡信息保留与内存占用。
这两大观察构成了 AdaCM2 设计的基础,驱动出一整套可调、可解释、可扩展的「视频记忆管理机制」。
创新:AdaCM2 提出跨模态动态压缩机制
为应对长视频带来的内存挑战,AdaCM2 首次引入了跨模态注意力驱动的层级记忆压缩策略。其核心思想是:「仅保留那些对文本提示最有意义的视觉信息」,并通过跨层级的策略自适应完成压缩,确保模型不丢关键信息。

关键技术点:
-
逐帧回归式建模:AdaCM2 不再一次性输入全部帧,而是逐帧处理并动态更新记忆缓存,实现轻量但语义连续的建模。
-
跨模态注意力打分:通过 Q-Former 模块,模型在每一层中计算视觉 Token 与文本提示之间的注意力权重,只保留注意力得分高的「关键信息 Token」。
-
分层压缩机制:针对不同 Transformer 层中 Token 的冗余程度,设置可调的压缩参数(α 和 β),实现更精细的内存控制。

-
与 LLM 无缝对接:AdaCM2 支持与各种主流 LLM 对接,如 Vicuna-7B、FlanT5 等,仅需轻量微调 Q-Former 模块即可完成端到端训练。
实验结果:性能超越 SOTA + 显存下降 65%

AdaCM2 在多个长视频标准数据集上进行了验证,包括:
-
LVU 分类任务:平均 Top-1 准确率提升 4.5%,在「导演」「场景」等任务上领先所有方法;
-
COIN / Breakfast 行为理解任务:超过 MA-LMM,展示更强泛化能力;
-
MSVD 视频字幕生成:达到 189.4 CIDEr,领先现有 SOTA;
-
内存效率:显存使用下降 65%,在极端情况下依旧维持稳定推理,支持处理超 2 小时长视频。
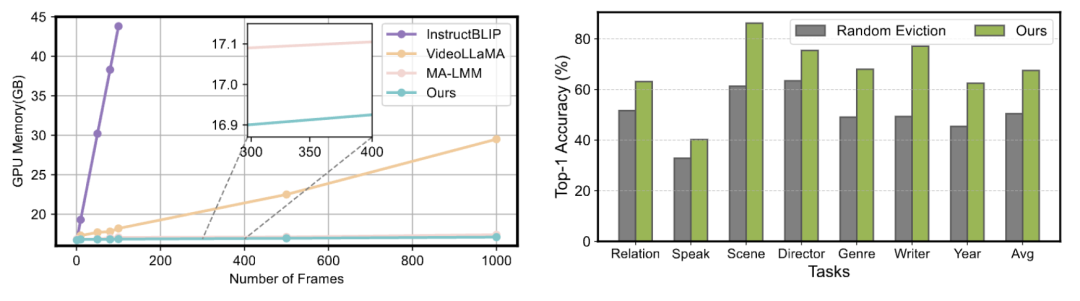
消融研究也显示,若移除跨模态压缩模块或将其替换为随机丢弃,模型性能将显著下降,证明观察驱动设计的有效性。
应用前景:多模态大模型的「长时记忆」引擎
AdaCM2 的提出,为多模态模型赋予了「可控的长时记忆能力」。这一能力不仅适用于传统的视频理解任务,还对以下未来应用场景具有重要意义:
-
智能交通监控:支持对全天候视频的智能分析与摘要生成;
-
医疗手术记录分析:自动分析长时间术中操作行为;
-
教育与会议记录理解:提取关键片段并生成总结;
-
机器人感知:支持具备持续视觉记忆的具身智能体。
总结
AdaCM2 作为首个专注于极长视频理解的跨模态记忆压缩框架,在大语言模型和视觉编码器之间架起了一座高效的信息筛选桥梁。它不仅优化了计算资源利用率,还拓展了多模态 AI 在实际应用中的边界。随着多模态大模型逐步走向落地,AdaCM2 的提出无疑将成为推动长视频智能理解发展的关键技术。
该论文已被 CVPR 2025 接收并评为 Highlight 论文,充分体现其在长视频多模态建模领域的前瞻性与影响力。更多相关研究成果也即将在未来发布,敬请关注!

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com