小红书开源 dots.llm1 大模型,参数量 142B,激活 14B,MoE 架构,数据质量高,训练效率高,性能优异,开源力度大,值得关注。
原文标题:没想到,最Open的开源新模型,来自小红书
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章里提到dots.llm1 在数据清洗上非常较真,未使用合成语料。那大家觉得对于通用大模型来说,高质量数据和合成数据哪个更重要?未来大模型训练数据的趋势会是什么样的?
3、dots.llm1 使用了 MoE 架构,并着重优化了训练效率。大家觉得 MoE 架构是未来大模型发展的方向吗?在实际应用中,MoE 模型会带来哪些挑战?
原文内容
编辑:杨文
迄今为止行业最大的开源力度。
在大模型上向来低调的小红书,昨天开源了首个自研大模型。
该模型名为 dots.llm1,是小红书 hi lab(Humane Intelligence Lab,人文智能实验室)团队研发的文本大模型。
它的参数不算最大,总参数量 142B,激活参数 14B,是一款中等规模的 MoE(Mixture of Experts)模型,不过它仍在较小激活量下展现出了良好性能。

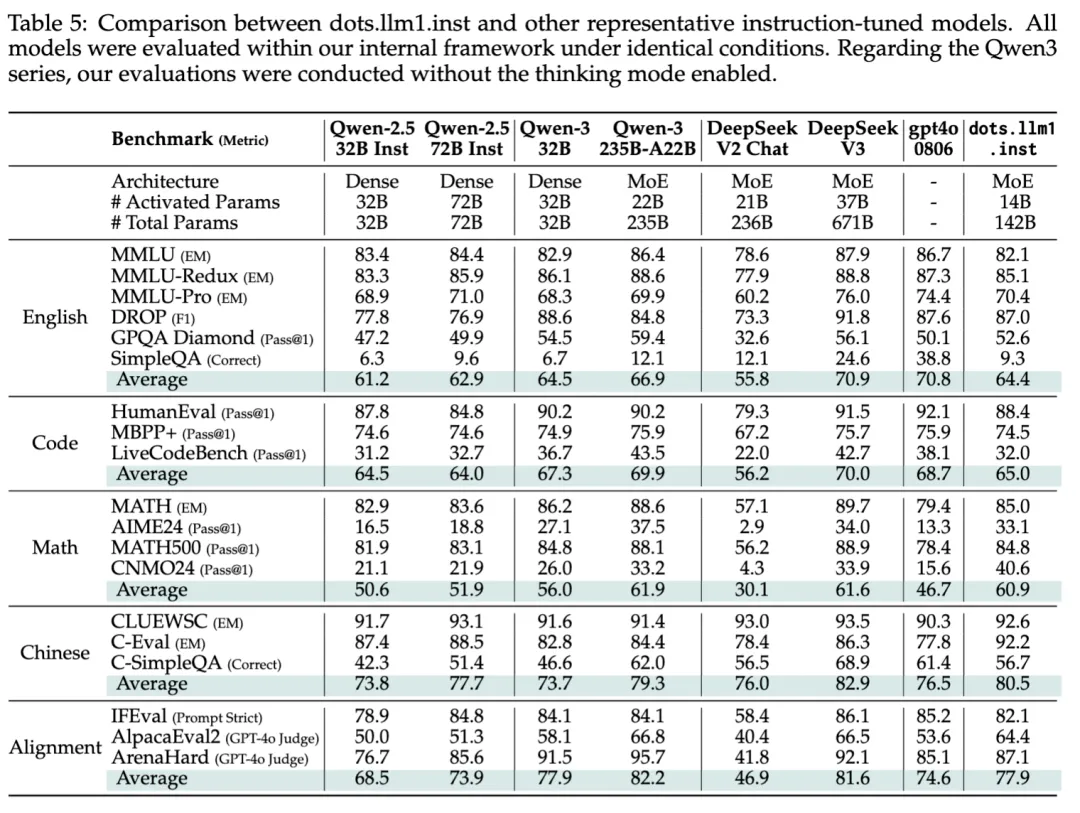
具体来说,在激活 14B 参数的情况下,dots.llm.inst 模型在中英文通用场景、数学、代码、对齐任务上的表现亮眼,与 Qwen2.5-32B-Instruct、Qwen2.5-72B-Instruct 相比具备较强的竞争力。同时与 Qwen3-32B 相比,在中英文、数学、对齐任务上表现接近。
此外,该模型的开源力度可以说是「卷」到了行业天花板。
不仅开源了 dots.llm1.inst 模型让开发者开箱即用,hi lab 团队还贴心地开源了一系列 pretrain base 模型,包括预训练第一阶段中每经过 1T tokens 后所保存的 checkpoint,以及退火阶段两次训练对应的模型 checkpoint、长文 base 模型。为了便于大家做 Continue Pretraining 和 Supervised Fine-tuning,hi lab 团队还详细介绍了 lr schedule 和 batch size 等信息。
真・从头开到尾,几乎每个细节都能拿来「二创」。
自 2023 年起,小红书就开始投入基础模型研发,本次开源正是其主动与技术社区展开对话的重要一步。
模型地址:
-
https://huggingface.co/rednote-hilab
-
https://github.com/rednote-hilab/dots.llm1
一手实测
模型好不好用,还得看多维度的任务实测表现。接下来,我们就把小红书的 dots 模型拉上「考场」,围绕问答、写作、编码等方面展开一场全方位的测评。
先来考考它的中文理解能力:大舅去二舅家找三舅说四舅被五舅骗去六舅家偷七舅放在八舅柜子里九舅借给十舅发给十一舅工资的 1000 元,请问谁才是小偷?
这道题目像绕口令一样七拐八绕,但 dots 并没有被迷惑,它通过逐步拆解、分析句子结构找出「偷」这个动作的执行者,最终给出正确答案。

弱智吧以幽默荒诞的段子而著称,自大模型爆火以来,「弱智吧」就成了检测大模型理解能力的标准之一。
比如这道经典问题:班房又叫牢房,为什么上班不叫坐牢?dots 先从语言的历史演变、二者的区别给出正儿八经的回答,然后玩起了梗,甚至还附上表情包。

不仅如此,dots 还很懂那些奇奇怪怪的谐音梗。

再来看看 dots 的文本写作能力。它以「老子今天要上班了」写了一首藏头诗,还挺有「活人味」,用一组清晨图景,把「打工人」的疲惫感刻画得相当接地气。

此外,它的编码能力也还不错,我们让它创建一个响应式的城市天气卡片组件,使用 HTML、CSS 和 JavaScript 实现。领到任务后,dots 二话不说就输出代码。
不得不说,它制作的动态卡片配色蛮舒服,并集齐了城市、日期、天气、温度、湿度以及风速等各种要素,点击右下角的按钮还能丝滑切换城市。

技术解读:高效 MoE 架构下的「以小搏大」
作为小红书 hi lab 首次开源的 MoE 模型,dots.llm1 并不一味追求「大力出奇迹」,而是在训练资源受限的前提下,通过更干净更优质的数据、更高效的训练方式来实现「以小搏大」的效果。

链接:https://github.com/rednote-hilab/dots.llm1/blob/main/dots1_tech_report.pdf
预训练数据:不靠合成也能「硬刚」
在大模型训练中,数据的质量是决定模型上限的关键因素之一。dots.llm1 使用了 11.2T 高质量 token 数据进行预训练,而这些数据主要来源于 Common Crawl 和自有 Spider 抓取到的 web 数据。与很多开源模型直接使用粗粒度数据不同,hi lab 团队在数据处理上非常「较真」,拒绝低质或虚构内容,通过三道「工序」把控数据质量:
首先是 web 文档准备,把 web HTML 数据用 URL 过滤方式删除黄赌毒等内容,再利用团队优化后的 trafilatura 软件包提取 HTML 正文内容,最后进行语种过滤和 MD5 去重得到 web document。
接着是规则处理,参考 RefinedWeb 和 Gopher 的方案进行数据清洗和过滤操作,引入 MinHash 和行级别去重策略,有效过滤广告、导航栏等噪声文本。
最后是模型处理,通过多个模型协同判断数据的网页类型、质量、语义重复性及结构均衡性,在确保文本安全、准确的同时提高知识类内容的占比。
经过上述处理流程,hi lab 团队得到一份高质量的预训练数据,并经过人工校验和实验验证该数据质量显著优于开源 TxT360 数据。

值得注意的是,dots.llm1 未使用合成语料,这也从侧面表明即便不依赖大规模数据合成,也可训练出足够强大的文本模型。但该团队也表示,数据合成作为提升数据多样性和模型能力的手段,仍是未来值得探索的重要方向。
训练效率:计算与通信高度并行
在 MoE 模型的训练过程中,EP rank 之间的 A2A 通信在端到端时间中占据了相当大比重,严重影响了训练效率,特别是对于 Fine-grained MoE Model,EP Size 会比较大,跨机通信基本无法避免。
为了解决这一挑战,hi lab 与 NVIDIA 中国团队合作,提出了一套颇具工程创新意义的解决方案:interleaved 1F1B with A2A overlap。该方案的核心就是让 EP A2A 通信尽可能和计算 overlap,用计算来掩盖通信的时间,进而提升训练效率。
具体来说,他们通过将稳态的 1F1B stage 中第一个 micro batch 的 fprop 提前到 warmup stage,即 warmup step + 1,就可以在 interleaved 1F1B 实现 1F1B 稳态阶段不同 micro batch 前反向之间的 EP A2A 与计算的 overlap。

同时,hi lab 团队还对 Grouped GEMM 进行了优化实现。他们将 M_i(专家 i 的 token 段)对齐到一个固定的块大小。这个固定块大小必须是异步 warpgroup 级别矩阵乘加(WGMMA,即 wgmma.mma async)指令中 tile 形状修饰符 mMnNkK 的 M 的整数倍。
通过这种设计,单个 threadblock 中的所有 warpgroups 都采用统一的 tiling,且由该 threadblock 处理的整个 token 段(Mi)必定属于同一位专家,这使得调度过程与普通 GEMM 操作非常相似。
经过实测验证,与 NVIDIA Transformer Engine 中的 Grouped GEMM API 相比,hi lab 实现的算子在前向计算中平均提升了 14.00%,在反向计算中平均提升了 6.68%,充分证明了这套解决方案的有效性和实用价值。

模型设计与训练:WSD 调度下的渐进式优化
在模型设计层面,dots.llm1 是一个基于 Decoder-only Transformer 的 MoE 模型,其整体架构设计主要借鉴了 DeepSeek 系列的思路与经验。

在训练策略方面,该模型采用了 WSD 学习率调度方式,整个训练过程主要分为稳定训练和退火优化两个阶段。
在稳定训练阶段,模型保持 3e-4 的学习率,使用 10T token 语料进行训练。为了提升训练效率,在这个阶段先后两次增加 batch size,从 64M 逐步增大至 128M,整个训练过程非常稳定,没有出现需要回滚的 loss spike。
随后进入学习率退火阶段,分两个 stage 训练 1.2T token 语料。其中 stage1 期间模型学习率由 3e-4 退火降至 3e-5,数据方面强化推理和知识类型语料,共训练 1T token;stage2 期间模型学习率由 3e-5 退火降至 1e-5,数据方面提升 math 和 code 语料占比,共训练 200B token。

Post-train:高质量、多场景、结构化调教策略
在完成高质量的预训练之后,dots.llm1 通过两阶段的监督微调进一步打磨模型的理解力与执行力。
hi lab 团队精心筛选了约 40 万条高质量指令数据,涵盖多轮对话、知识问答、复杂指令遵循、数学推理与代码生成等五大核心场景。
-
多轮对话方面:团队将社区开源的中英对话数据与内部标注的高质量中文指令融合,并借助教师模型优化低质量回答,从而提升整体对话的连贯性和准确性;
-
知识问答模块:引入了包含事实性知识与阅读理解的数据集,让模型能够更好地理解和回答各类知识性问题;
-
复杂指令遵循环节:团队特别设计了伴随条件约束的指令数据,并过滤不遵循约束的回复;
-
数学与代码领域:微调数据则经过验证器验证,确保获得最高质量的监督信号。
整个微调过程分为两个阶段:
-
第一阶段是对全量数据进行两轮基础训练,过程中引入了过采样、动态学习率调整、多轮对话拼接等技术,初步释放模型潜力;
-
第二阶段则专注于「重点突破」。在数学与代码等对推理能力要求更高的任务上,团队采用了拒绝采样微调(RFT)策略,结合验证器筛选高置信度重要样本,进一步提升模型的推理性能。
最终评测结果也令人眼前一亮:即便仅激活了 14B 参数,dots.llm1.inst 在中英文理解、数学、代码生成、对齐等任务中依然表现出色,具备与 Qwen2.5-32B-Instruct、甚至 Qwen2.5-72B-Instruct 一较高下的实力。在对比更先进的 Qwen3-32B 时,dots.llm1.inst 也在多个任务上展现出相似甚至更强的性能。
结语
在 HuggingFace 的热门开源模型榜单上,中国模型的身影已占据半壁江山,开源正逐渐成为中国大模型团队的集体共识。
此次 dots.llm1 的开源,不仅是小红书 hi lab 团队的一次技术成果展示,也是一种路线选择的「表态」—— 相比于闭门修炼,他们更愿意走入江湖与高手交流。在开发者眼中,这意味着又多了一个值得信赖的模型基座;而对 hi lab 而言,来自社区的微调成果也将反哺基模,为模型注入更多可能性。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com