浙大提出CoT-Bridge,解决大模型推理中思维链“跳帧”问题,显著提升数学推理性能,并可作为插件嵌入知识蒸馏和强化学习流程。
原文标题:思维链也会「跳帧」?浙大团队提出CoT-Bridge,显著提升数学推理性能
原文作者:机器之心
冷月清谈:
怜星夜思:
2、CoT-Bridge方法在提升数学推理性能上表现出色,那么这种方法是否可以推广到其他类型的推理任务中?例如,常识推理、医学诊断等领域,CoT-Bridge可能会遇到哪些挑战?
3、文章提到CoT-Bridge可以嵌入到知识蒸馏和强化学习流程中,那么在实际操作中,如何选择合适的蒸馏模型或强化学习算法,才能最大化CoT-Bridge的效果?有没有一些经验性的建议?
原文内容

本文的共同第一作者是徐皓雷和颜聿辰。徐皓雷是浙江大学的一年级硕士生,主要研究兴趣集中在大模型推理和可解释性研究;颜聿辰是浙江大学博士三年级研究生,主要研究兴趣集中在大模型推理和智能体。本文通讯作者是浙江大学鲁伟明教授和沈永亮研究员。
在大语言模型(LLM)飞速发展的今天,Chain-of-Thought(CoT)技术逐渐成为提升复杂推理能力的关键范式,尤其是在数学、逻辑等结构化任务中表现亮眼。
但你是否注意到:即使是精心构建的 CoT 数据,也可能存在 “跳跃式” 推理,缺失关键中间步骤。对人类专家来说这些步骤或许 “理所当然”,但对模型而言,却可能是无法逾越的鸿沟。
为了解决这一问题,浙江大学联合微软亚洲研究院、香港中文大学提出了 Thought Leap Bridge 任务,并开发了思维链修复方法:CoT-Bridge。实验显示,该方法显著提升了多个数学与逻辑任务中的推理准确率,并能作为 “即插即用” 的模块嵌入到知识蒸馏、强化学习等流程中。

-
论文链接:https://arxiv.org/abs/2505.14684
-
项目主页:https://zju-real.github.io/CoT-Bridge/
-
代码仓库:https://github.com/ZJU-REAL/Mind-the-Gap
CoT 不等于 Coherent-of-Thought
思维跳跃是如何破坏推理链的?
CoT 的设计初衷是让大模型像人一样 “按步骤思考”,然而研究团队发现,许多公开 CoT 数据中存在一种被严重低估的问题:Thought Leap。
Thought Leap 指的是 CoT 推理链中,前后步骤之间存在中间推理内容的省略,导致逻辑跳跃,破坏推理的连贯性。
这种现象往往源于专家在书写推理过程时的 “经验性省略”—— 由于熟练掌握相关问题,他们倾向于跳过自认为显而易见的步骤。然而,模型并不具备这种人类专家式的 “思维粒度”:它需要更细致、逐步的推理过程来建立完整的逻辑链条。
论文中给出了一个典型例子:
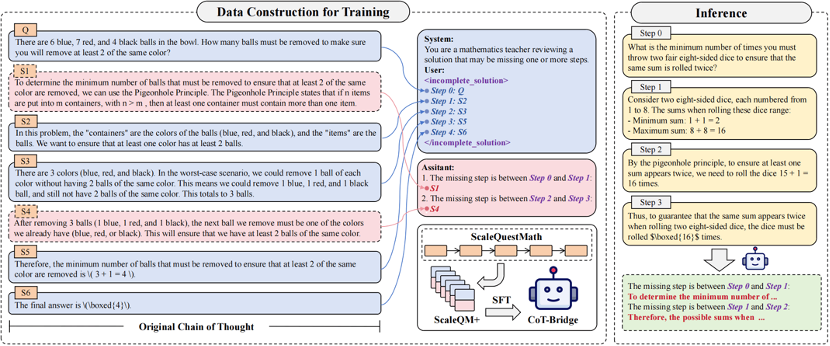
对于问题 “两颗八面骰子最少要投多少次,才能确保出现重复的和?”
原始 CoT 中跳过了两个关键推理环节:15 种是怎么来的?为什么要使用鸽巢原理?
这种 “缺口” 虽然对人类来说轻松跨越,对模型而言却是理解失败的高风险点。
团队通过实验证明,这种结构性不完整对模型训练带来显著负面影响:
-
训练效果降低:严重的思维跳跃可造成 27.83% 的性能损失
-
学习效率变低:模型在训练过程中的收敛速度显著变慢

CoT-Bridge:为模型补上思维跳跃的 “桥梁”
为解决数学推理任务中推理链不连贯的问题,研究团队提出了 Thought Leap Bridge Task,目标是自动检测推理链中的结构性缺失,并补全相应的中间推理步骤,以恢复其逻辑完整性。
该任务包含两个关键子问题:
1. Leap 检测:识别推理链中相邻步骤之间是否存在逻辑跳跃,即是否缺失必要的过渡性推理。
2. 步骤补全:对于检测到的跳跃位置,生成满足推理连贯性的中间步骤。
团队将 ScaleQuestMath 作为 “理想” CoT 数据集,并基于其构建了专用训练数据集 ScaleQM+。研究团队通过有控制地删除原始推理链中的若干中间步骤,构造出含有 Thought Leap 的 “不完整推理链”,并与被删除的步骤配对,作为训练样本。这一设计使得模型能够学习到如何识别不连贯结构,并生成适当的推理补全内容。
随后,团队基于 Qwen2.5-Math-7B 对模型进行指令微调,训练出 CoT-Bridge 模型。该模型能够作为独立组件,接收可能存在缺口的推理链输入,自动输出所需的中间步骤补全,从而生成结构完整的推理过程。
实验结果
补全后的数据集显著提升 SFT 效果
研究团队在两个数学推理数据集 MetaMathQA 和 NuminaMath 上,分别使用补全前后的数据进行监督微调(SFT)对比实验。结果显示,使用 CoT-Bridge 补全 Thought Leap 后的数据在多个数学基准任务上均带来了显著的性能提升,其带来的最大增益达到 + 5.87%。这表明:思维链的连贯性,正是限制模型进一步提升的瓶颈之一,修复这些 “跳跃”,能够让模型真正学会 “怎么思考”。

即插即用,增强蒸馏与强化学习流程中的训练效果
在主实验基础上,研究进一步评估了 CoT-Bridge 在更广泛训练流程中的适配性,包括知识蒸馏与强化学习两个典型场景。
蒸馏数据增强:使用大模型生成数学题解是当前训练数据的来源之一。团队将 CoT-Bridge 应用于使用 Qwen2.5-Instruct-72B 蒸馏得到的数据。实验结果表明,补全后的蒸馏数据带来 + 3.02% 的准确率提升。该结果说明,即便原始生成内容已具备较高质量,推理过程的结构优化仍能带来额外增益。
强化学习冷启动优化:在强化学习范式中,初始监督微调模型对最终性能具有重要影响。研究团队将使用 CoT-Bridge 生成的数据用于 SFT,并在此基础上继续训练。对比实验显示,该方案可作为更优的 “冷启动模型”,在训练初期即具备更高起点,并最终获得更好的收敛性能。在 NuminaMath 数据集上,基于补全后数据训练的模型在 RL 阶段最终准确率较原始方案提升约 +3.1%。

泛化能力提升,改善 OOD 推理表现
为了验证 CoT-Bridge 是否具备跨任务迁移能力,研究将逻辑推理类任务作为模型在 OOD 场景下的评估基准,包括 FOLIO、LogicQA、ProofWriter、ReClor 和 RuleTaker 等。
实验结果表明,使用补全数据训练的模型在大多数逻辑任务中准确率有不同程度提升,Meta-Llama3.1-8B 平均提升为 +2.99%,Qwen2.5-Math-1.5B 提升约 +0.99%。此外,模型生成无效输出的比例有所下降,说明其在结构控制和推理一致性方面表现更为稳健。这意味着,补全思维链条不仅提升了数学能力,也让模型更擅长 “解释自己是怎么推理出来的”,从而在广义逻辑任务中具备更强鲁棒性。


© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com