探讨了利用多模态大语言模型(MLLM)增强时间序列推理能力的方法,强调整合多种模态数据能为时间序列分析提供更强大的推理能力。
原文标题:依托多模态LLM,强化时间序列推理效能
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章里提到了多种时间序列推理的类型,例如演绎推理、归纳推理、病因推理等等。在实际应用中,你觉得哪种推理类型最实用,或者说最有价值?为什么?
3、文章提到了MLLM在时间序列问题回答方面的应用,你觉得这种技术会对传统的搜索引擎带来哪些冲击或者改变?
原文内容

来源:时序人本文约3700字,建议阅读10分钟
本文探讨了两个关键的替代观点,挑战了关于时间序列推理的一些常见假设。
理解时间序列数据对于许多现实世界的应用至关重要。尽管大型语言模型(LLM)在时间序列任务中展现出潜力,但当前的方法通常仅依赖数值数据,忽略了时间依赖信息的多模态特性,例如文本描述、视觉数据和音频信号。此外,这些方法未能充分利用 LLM 的推理能力,仅停留在表层解释,而非更深入的时间和多模态推理。
本文作者认为多模态大语言模型(MLLM)能够为时间序列分析提供更强大且灵活的推理能力,从而增强决策制定和现实世界的应用。进而呼吁研究人员和实践者通过开发优先考虑信任、可解释性和稳健推理的策略来利用这一潜力。最后,作者强调了关键的研究方向,包括新颖的推理范式、架构创新和特定领域的应用,以推动 MLLM 在时间序列推理中的发展。

【论文标题】
【论文地址】
https://arxiv.org/abs/2502.01477
论文背景
时间序列分析在金融、医疗保健和能源等领域具有重要应用。在时间序列分析中,更深入的推理和上下文理解对于识别模式、因果关系和微妙的上下文动态至关重要。这些微妙的上下文动态可能包括时间依赖关系的变化、潜在的外部影响或不断演变的结构模式,这些模式通过传统数值分析不容易被察觉。
然而,大多数当前的研究将时间序列视为纯粹的数值输入,忽略了现实世界和时间依赖上下文的固有多模态特性。实际上,时间序列通常伴随着补充数据流(例如文本和图像),这些数据流提供了额外的信息层。大多数现有系统未能充分利用这种多模态丰富性,在实现更复杂时间序列任务的稳健推理方面存在相当大的差距。
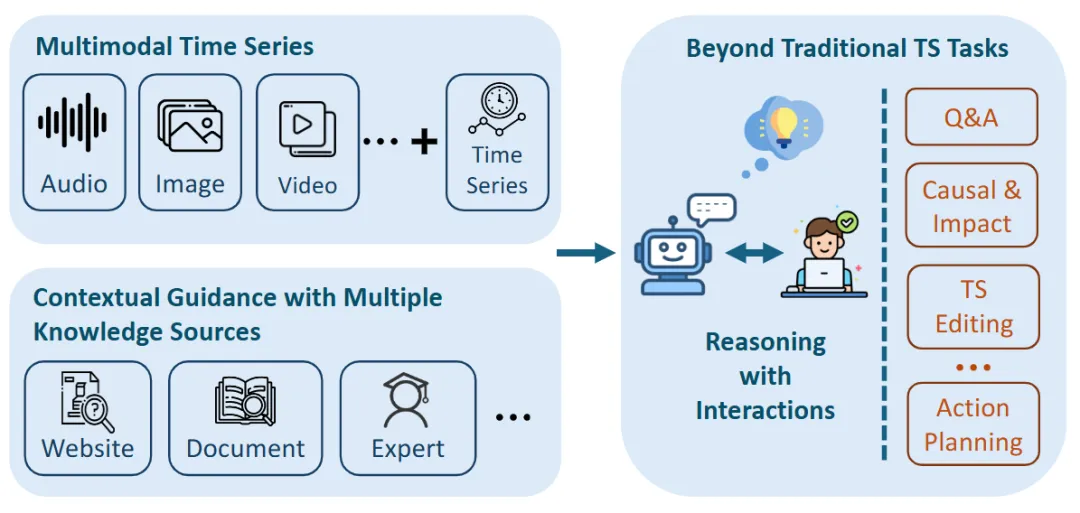
本工作的贡献:
-
对时间序列推理的新视角:超越了传统的时间序列分析任务,强调更深入的推断和理解;
-
多模态推理框架:提出了一个整合来自各种模态的时间依赖数据的范式,使 MLLM 能够推导出更丰富的见解和解释;
-
机遇、挑战和未来方向:探讨了关键的研究方向和技术挑战,提出了推进多模态推理架构的解决方案,并强调了设计新数据集和评估方法以严格评估多模态时间序列推理的重要性。
时间序列推理
01 时间序列推理是什么?
时间序列推理指的是 MLLM 以类似人类逻辑的方式处理和解释时间序列的能力。它能够捕捉时间结构、趋势和模式,以生成各种时间序列任务的精确且可解释的结果,用清晰自然的语言提供见解。与专注于特定目标的传统时间序列方法不同,时间序列推理将这些任务整合到一个统一的框架中。它结合了上下文感知、时间序列特征和高级推理,以提供更深入的见解、增强的可解释性以及处理需要超出时间序列本身的外部信息的复杂任务的能力。
02 时间序列推理的类型
根据推理结构和任务目标,时间序列推理可以分为不同的类型。推理结构包括端到端推理、前向推理、后向推理和前向-后向推理。任务目标则涉及演绎推理、归纳推理、病因推理、因果推理等。
03 实现时序推理的关键组成部分
为了实现有效的时间序列推理,文章提出了四个关键组成部分:理解时间序列特征、上下文引导、推理过程和迭代反馈。这些组成部分共同作用,确保模型能够全面理解时间序列数据,并生成准确、可解释的推理结果。
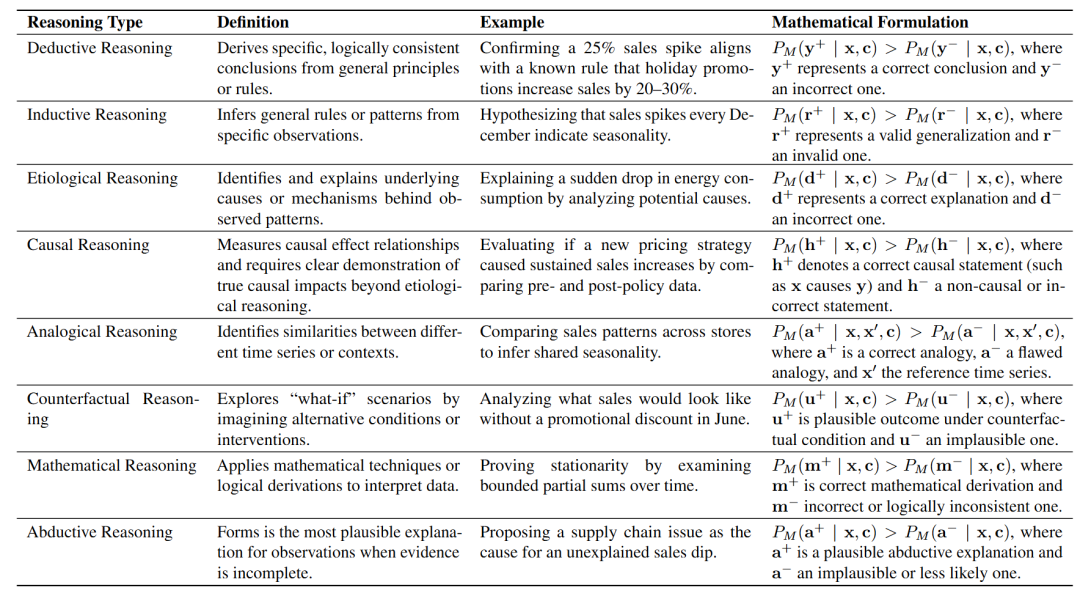
表1:针对任务目标的不同推理类型的比较,包含定义、示例及数学表述

图2:实现时间序列推理的关键组件(以金融时间序列为例进行说明)
04 有前景的模型设计
对于高级推理任务,通常有四种模型设计思路,这些思路要么利用 LLM/MLLM 固有的推理能力,要么设计一个时间序列 MLLM,又或者充分利用多模态输入和能力。作者将这些方法分为零样本推理、单阶段微调、双阶段微调和多模态时间序列方法(如图3所示)。
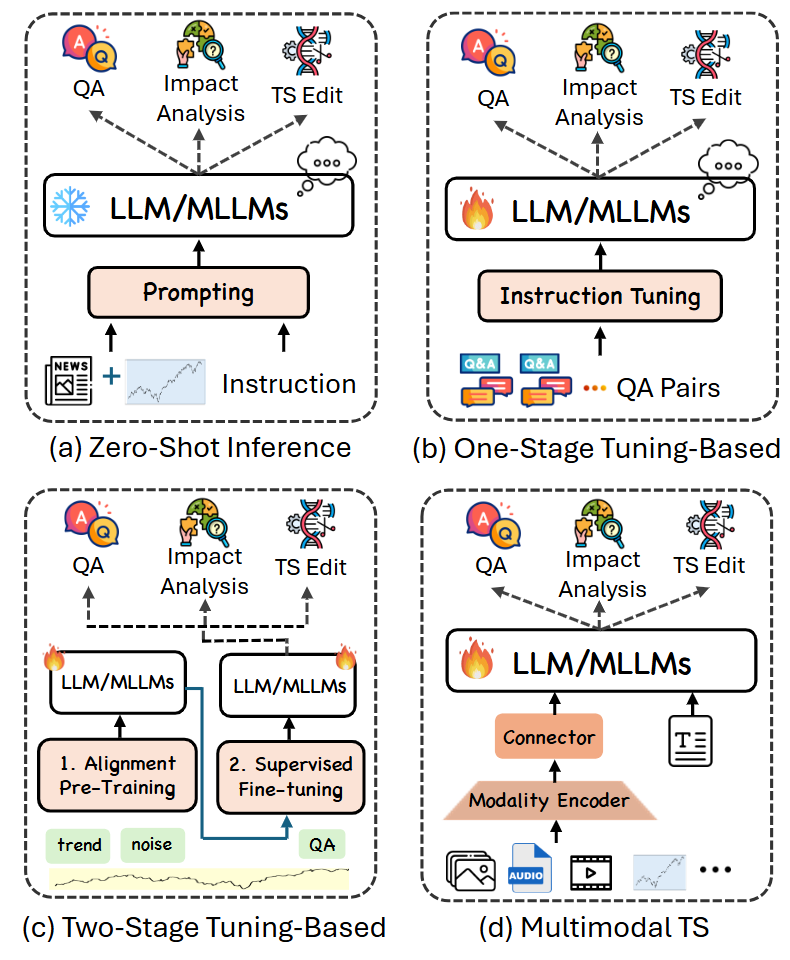
图3:不同类别的高级时间序列推理任务及其架构
超越经典时序任务
MLLM 与时间序列推理的结合,激发了超越传统时间序列任务的新任务。这些新任务侧重于推理和创造性地操纵时间序列,包括基于时间序列的问题回答、因果推断与影响分析,以及时间序列生成与编辑。这些任务通过整合多模态数据,为时间序列分析带来了新的视角和应用。
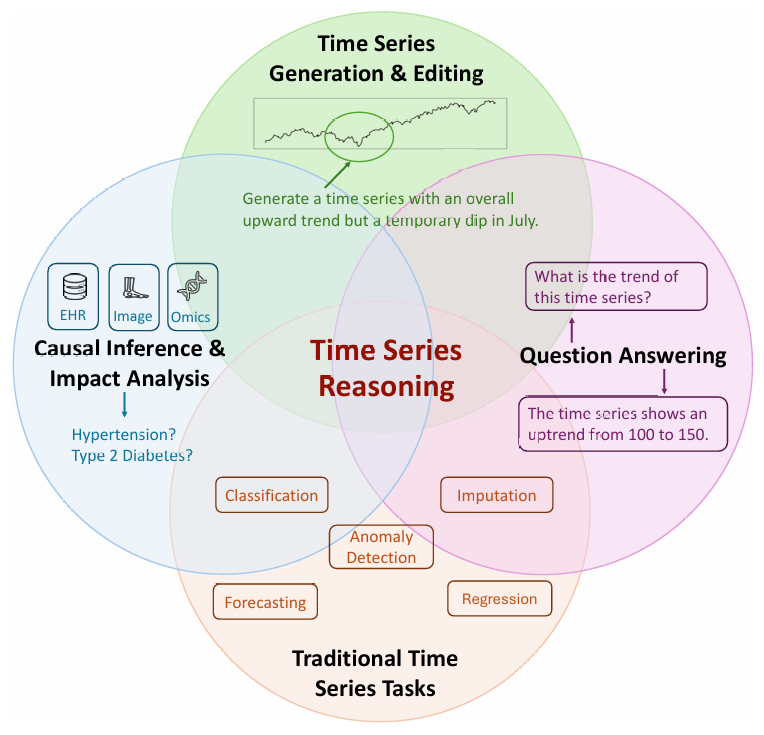
图4:时序推理时代中的时序数据系列任务


03 时间序列生成与编辑
合成或修改时间序列,可选择通过文本、图像或结构化数据进行对齐或补充信息。
-
天气预报:生成合成天气数据,模拟极端气候场景并探索极端天气背后的原因。
-
城市规划:编辑交通流量数据,评估基础设施变化的影响。
-
多模态输入:通过提供额外的上下文(如卫星图像、地图数据或人口统计数据),确保生成或编辑的数据既真实又具有可操作性。
-
改进插补:利用生成或编辑技术改进时间序列插补,实现更真实的生成和插补结果。
01 数据集和基准测试
目前,公开可用的多模态时间序列数据集和代码非常有限。现有的数据集大多通过 GPT 模型或 LLM 人工生成,缺乏真实世界数据的多样性和复杂性。
-
缺乏多模态表示:大多数数据集仅将数值时间序列与文本描述配对,缺乏图像、音频或其他模态的数据,限制了模型的多模态学习能力。
-
缺乏自然融合:能够将时间序列自然地融入文本信息的数据集较少,这限制了模型在处理复杂任务时的表现。
-
推理结构单一:现有数据集主要关注前向推理结构(如基于思维链的方法),缺乏多样化的推理过程。
02 评估指标
推理的评估相对困难,因为推理过程往往是无形的且高度主观的。大多数现有研究通过比较不同 LLM 的结果准确性来进行评估,这种方法通常应用于多项选择题或判断题。
-
缺乏标准评估指标:目前在时间序列推理领域尚未有统一的评估指标,不同的任务和数据集需要不同的评估方法。
-
评估方法有限:例如,归纳推理的评估通常采用基于关键词匹配的方法(如 RAGAS),而预测准确性评估则采用 ROI CRPS(RCRPS)等指标。
03 训练策略
目前的模型设计主要集中在零样本推理、单阶段微调和双阶段微调等方法上。这些方法在一定程度上提高了模型的性能,但仍有改进空间。
-
推理机制未完全嵌入:大多数方法仅在问题-答案对中包含推理结构,而没有将推理机制完全嵌入到训练过程中。
-
训练过程缺乏多样性:现有的训练策略主要关注结果的准确性,缺乏对推理过程的显式建模。
-
开发更多现实且多模态的基准数据集,以支持多样化的推理结构。
-
设计针对具体任务的评估指标,不仅评估答案的准确性,还评估底层的推理过程。
-
将显式的推理过程整合到训练阶段,通过更详细、更高质量的推理来提高模型的性能和决策能力。
替代观点
作者探讨了两个关键的替代观点,挑战了关于时间序列推理的一些常见假设。
首先,质疑单模态数据是否足以支持现实世界应用中的复杂时间序列推理任务。
其次,探讨了 LLM 和 MLLM 在时间序列推理中的有效性,强调了这些模型的潜力和局限性。
作者指出,尽管 LLM 在某些情况下可能足够,但在复杂现实世界应用中,多模态方法和 LLM 的广泛推理能力是实现更丰富、更准确分析的关键。此外,文中还讨论了 LLM 在预训练数据中的潜在重叠问题,并强调了建立严格评估框架的重要性。
