提出CATS,一种新颖的上下文感知知识图谱补全方法,通过潜在类型约束与子图推理,提升LLM在结构化数据上知识密集型推理任务的表现。
原文标题:AAAI 25 | CATS:基于潜在类型约束与子图推理的上下文感知归纳知识图谱补全
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、子图推理(SR)模块中使用基于度数的过滤机制来筛选推理路径,这种方法有什么优缺点?有没有其他更有效的路径筛选方法?
3、文章提到CATS在少样本场景下表现依然出色,那么这种方法在实际应用中,对于冷启动的知识图谱补全有什么帮助?
原文内容

来源:MIND at NJUPT本文约5000字,建议阅读10分钟本文提出"CATS"——基于潜在类型约束和子图推理的上下文感知归纳式KGC新方法。

Year: 2025
Conference: AAAI 2025
Address: https://arxiv.org/abs/2410.16803
引言
知识图谱(Knowledge Graphs,KGs)是以(头实体,关系,尾实体)三元组形式表示事实的图结构知识库。知识图谱已成为问答系统、事实核查和推荐系统等下游应用的关键基础设施。实践中,大多数现实世界知识图谱都存在不完整性问题,这凸显了知识图谱补全(Knowledge Graph Completion,KGC)任务的重要性,该任务旨在从查询三元组中预测缺失的头实体或尾实体。
现有KGC方法通常在“直推式”设定下表现良好,即训练三元组中可观察到缺失实体。相比之下,“归纳式”KGC任务要求模型处理新出现的实体,这更符合现实场景,因为知识图谱是持续演化的。归纳式设定强调了知识图谱中固有的三个关键上下文:实体类型、推理路径和邻域事实。
首先,知识图谱中的关系会对连接的头尾实体施加潜在类型约束,这对推断可能缺失的三元组至关重要。例如,works_in关系通常连接人物(头实体)和地点(尾实体)。尽管训练阶段未见过新出现的实体,但只要头尾实体符合关系要求的隐含类型,该三元组仍可被视为合理。
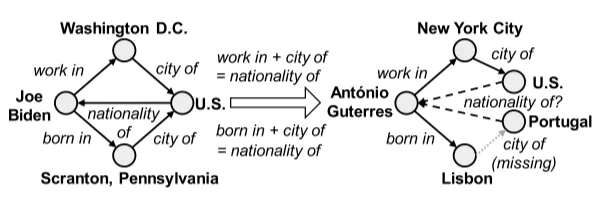
其次,推理路径为缺失三元组的存在提供直接线索。但这些路径在某些上下文中可能不可靠。如图所示,若训练集中包含大量类似(Joe Biden, works_in, Washington, D.C.)、(Washington,D.C., city_of, U.S.)和(Joe Biden, has_nationality,U.S.)的三元组,模型可能推导出(works_in + city_of = has_nationality)的隐含规则。但需注意此类隐含规则并非普遍适用,Antonio Guterres作为联合国秘书长在纽约工作就是典型反例。
最后,头尾实体的邻域事实也为三元组补全提供重要线索。如图所示,仅凭现有推理路径难以预测"António Guterres"具有葡萄牙国籍,但(António Guterres, born_in, Lisbon)等特定邻域事实可帮助从干扰项中识别正确答案。
尽管已有大量研究,现有方法仍无法充分利用这些上下文。具体而言:
-
基于嵌入的方法需要昂贵重训练来嵌入未见实体;
-
基于GNN的方法在现有实体与新实体间连接稀少时鲁棒性不足;
-
基于路径的方法严重依赖特定实体间推理路径的存在与可靠性;
-
基于文本增强的方法忽略了知识图谱中的实体类型属性。
整合大语言模型(LLMs)是有效利用这三类上下文的直接方案。一方面,LLMs通过海量语料训练已掌握知识图谱实体的基本类型认知;另一方面,强大的语义理解与推理能力使其能从三元组和路径中捕捉关键信息。然而现有基于LLM的KGC方法仅能对先前KGC方法提供的候选答案进行重排序,不可避免地受限于前置模型的缺陷。此外,这些方法依赖验证集额外三元组进行上下文演示或有监督微调,应用于归纳场景时会导致严重信息泄露。
本文提出"CATS"——基于潜在类型约束和子图推理的上下文感知归纳式KGC新方法。考虑到自然语言句子与结构化知识图谱三元组间的语义鸿沟,CATS通过微调并引导LLMs从两个维度评估潜在缺失三元组的存在性:类型感知推理(TAR)模块评估候选实体是否符合关系约束的隐含类型;子图推理(SR)模块采用基于度数的过滤机制选择有意义路径,并考虑头尾实体的相关邻域事实。LLMs卓越的长上下文理解能力使SR模块能全面评估不同路径和邻域事实对特定三元组存在的支持程度。最终通过集成两个模块的评分结果获得推理结论。
相关工作
基于嵌入的方法构成了知识图谱补全的主流技术,包括TransE、RotatE和GIE等方法。这些方法通过特定几何假设为知识图谱中的每个实体和关系学习一组低维嵌入表示,本质上属于直推式方法。然而,它们需要昂贵的重训练过程来处理未见实体,限制了在归纳式场景中的适应性。
基于图神经网络(GNN)的方法在自然语言处理中广泛用于建模实体间关系,例如CompGCN、RGCN和WGCN等方法通过迭代聚合局部邻域特征来嵌入知识图谱中的实体。然而,当新出现的实体与现有实体之间连接稀少时,这些方法难以生成有意义的嵌入表示,且无法适用于全新的图谱结构。为了适应归纳式设定,GraIL和TACT等方法利用查询三元组头尾实体的相对距离来嵌入局部子图中的实体,但这种嵌入方式无法区分共享相同相对位置的不同实体,当查询三元组的子图规模较大时表现欠佳。RED-GNN和Adaprop通过渐进式和自适应传播机制增强消息传递,但仍未能解决GNN在稀疏图结构上的次优性能问题。
基于路径的方法旨在挖掘连接头尾实体的推理路径与三元组关系之间的共现规则。具体而言,DeepPath和MINERVA采用强化学习驱动的随机游走生成推理路径,而BERTRL和KRST则利用广度优先搜索。然而,未见实体之间推理路径的存在性和质量无法保证,这不可避免地限制了这些方法的泛化能力。
除图结构外,知识图谱提供的文本信息也蕴含宝贵的语义知识。近年来,KG-BERT、BERTRL和KRST等方法利用预训练语言模型对带有文本标签和描述的实体、关系及推理路径进行嵌入表示。APST进一步为未连接任何推理路径的未见实体引入不完整锚路径,实现了最先进的性能。尽管研究表明组合多条推理路径能促进知识交互,但其基于BERT的骨干模型仅能独立编码每条路径,存在显著改进空间。
预备知识
定义1(归纳式KGC):给定训练图 ,测试图 。归纳式KGC任务旨在从查询三元组集合 中补全缺失的头实体或尾实体,其中, , , 。
归纳式KGC任务的设定确保训练图和测试图中的实体构成两个不相交的集合。模型训练仅能使用训练图中的三元组,而测试图中的三元组仅作为查询三元组补全的证据。处理未见实体要求模型具备归纳推理能力。
实体类型属性。除三元组外,知识图谱中的实体通常按照本体分类法标注类型。例如在Freebase中,实体"Albert Einstein"属于"/scientist/physicist"类型。一般而言,实体类型概括了实例实体的关键属性,对判断特定实体是否可能作为某关系的头或尾实体至关重要。然而,非百科全书类知识图谱(如WordNet)中的实体通常缺乏显式类型标注。
推理路径。由于测试图中的实体在训练阶段未曾出现,近期最先进方法利用推理路径进行预测。
定义2(推理路径):给定查询三元组 ,推理路径是连接头实体 和尾实体 的三元组序列,形式化表示为:
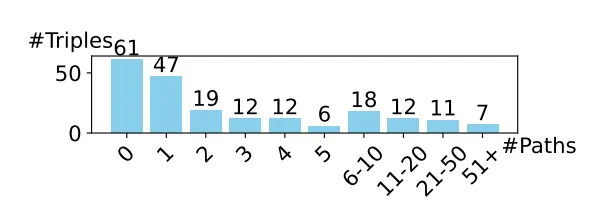
其中 并且 , 在训练阶段表示 ,在评估阶段表示 。然而,推理路径的存在性和质量无法保证,尤其在少样本场景中。例如,统计显示在FB15k-237(归纳式)数据集的测试集中,205个查询三元组中有61个缺乏可用推理路径。
方法
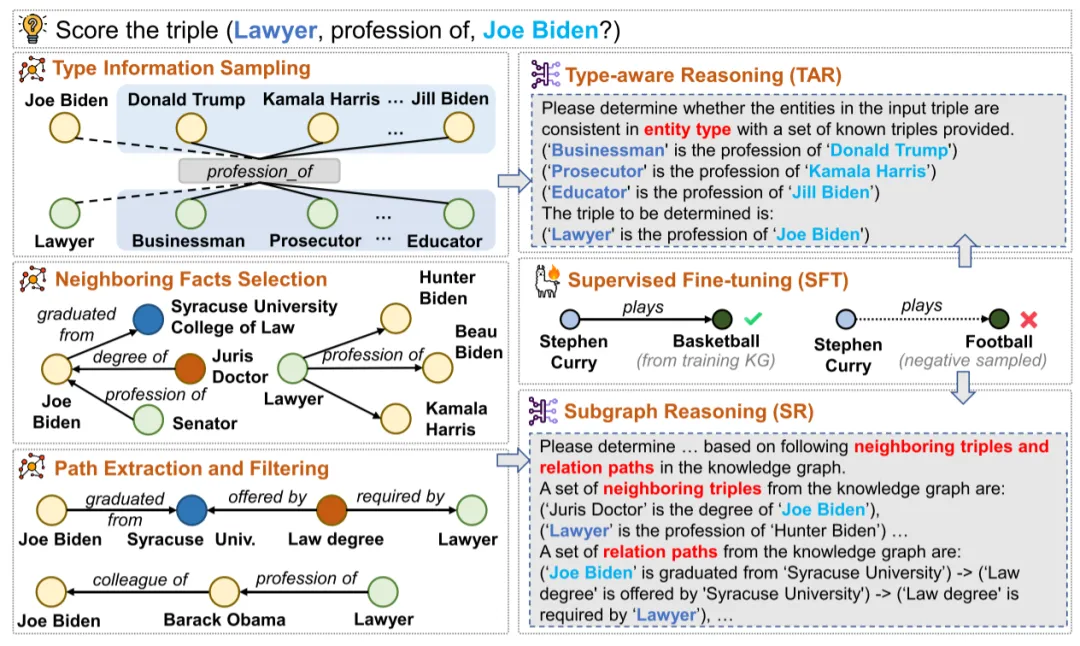
图中展示了CATS框架的端到端架构。为摆脱对显式类型标注的依赖,本文在类型感知推理(TAR)模块中设计了一种更通用的方法来挖掘关系相关的潜在类型约束。此外,在子图推理(SR)模块中整合了相关邻域事实和推理路径来支持三元组评估。下文将详细讨论LLM监督微调(SFT)策略,以及如何聚合对查询三元组的最终预测。
类型感知推理(TAR)模块
知识图谱中通常有这样的特征,由相同关系连接的实体往往具有相似属性和特征,因而属于相同实体类型。在判断未知实体是否可能成为三元组的头或尾实体时,需确认该实体符合关系所要求的类型。实践中,并非所有实体的类型属性都显式可用。直接解决方案是使用LLM为每个候选实体标注类型信息,并总结特定关系所连接实体的共同类型。然而,一个实体可能在不同领域中属于不同粒度的多种类型。例如在Freebase中,实体"Nick Mason"对应person、film_actor和book_author等类型。缺乏显式类型标注的明确引导时,LLM输出的类型结果将不稳定。
本文转而引导LLM通过隐式考虑候选头/尾实体与相同关系连接的其他头/尾实体间的类型相关性来评估三元组的合理性。如图所示,对每个查询三元组 ,首先从知识图谱中采样k个具有相同关系 的三元组 作为示例。随后将这些结构化三元组与实体和关系的文本标签线性化,使LLM能够总结出头尾实体集合间的潜在类型模式(例如art_work与award通过nominated_for关系连接的模式)。最后提供线性化的查询三元组,要求LLM在实体类型符合该模式时输出"Y",否则输出"N"。
采用对比学习策略对LLM进行微调。对训练图Gtrain中的每个正例三元组 ,通过随机替换头或尾实体构造负样本,并使用公式所示的损失函数进行监督微调。该损失函数最大化正例三元组被LLM判断为"Y"的概率,同时最小化负例三元组被误判为"Y"的概率。
子图推理(SR)模块
知识图谱中实体知识体现在其局部子图。仅考虑实体类型不足以断言候选实体应通过特定关系与某些实体相连。近期研究表明推理路径为两实体间特定关系的存在提供直接证据。但受限于BERT类预训练语言模型的能力,现有方法需独立编码每条推理路径进行考虑,可能导致不可靠的关系预测结果。受LLM强大推理能力启发,SR模块可建模多条推理路径与查询三元组两实体邻域事实间的交互作用。
路径提取与过滤
沿用广度优先搜索(BFS)提取连接查询三元组两实体的推理路径,仅保留长度不超过n的路径。同时观察到高频关系(如has_gender)对评估其他关系存在性意义有限,而低频细粒度关系(如appear_in_film)通常提供更精确证据。因此设计基于度数的过滤机制:给定推理路径 ,统计路径中各关系在训练集中的出现次数 ,计算路径度数 作为各关系出现次数的总和。最终为每个查询三元组选择β条度数最低的推理路径进行评估。
邻域事实选择
邻域事实选择进一步采用头尾实体的邻域事实作为补充上下文。从训练图中收集包含头实体 或尾实体 的支持三元组,使用"bge-small-en v1.5"句子转换器计算查询三元组与各支持三元组的嵌入相似度。
为屏蔽无关邻域信息干扰,选择 个与查询三元组余弦相似度最高的支持三元组。通过专门设计的提示模板,指导LLM根据推理路径和邻域事实判断查询三元组是否成立,并采用损失函数进行微调。
三元组评估
推理阶段的三元组评分通过集成两类提示下LLM输出"Y"的概率实现。最终评分 取TAR模块基于关系模式判断的概率与SR模块基于子图上下文判断的概率的平均值。这种集成方式充分利用了类型属性与结构上下文的互补关系。
实验
数据集与评估指标
在三个广泛使用的基准知识图谱WN18RR、FB15k-237和NELL-995上评估所提方法,分别测试其直推式和归纳式子集。遵循先前研究的设定,每个查询三元组使用1个正确答案和49个负样本候选实体进行评估。为确保公平比较,采用相同的数据划分和负样本构造方式。通过计算候选实体的合理性得分并降序排序,采用平均倒数排名(MRR)和Hits@1作为评估指标。
基线方法与实验设置
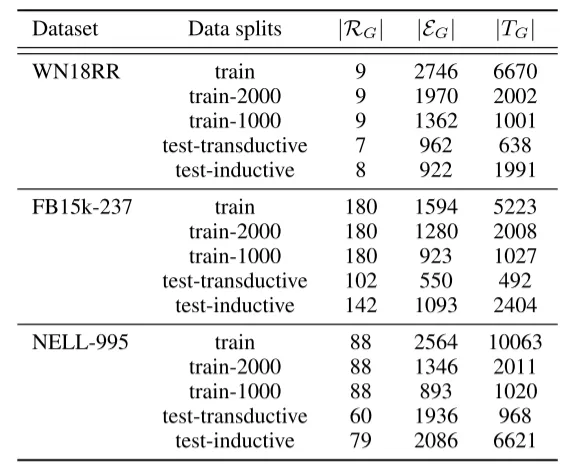
将CATS与基于嵌入的方法(RuleN、TuckER)、基于GNN的方法(GraIL、Red-GNN、Adaprop)、基于文本的方法(KG-BERT)以及基于路径的方法(MINERVA、BERTRL、KRST和当前最优方法APST)进行对比。选择Qwen2-7B-Instruct作为主干大语言模型,并在消融实验中测试Llama-3-8B和Qwen2-1.5B的性能。采用LoRA进行参数高效微调,设置秩为16、α值为32,使用AdamW优化器以1e-4学习率、单设备批次大小2和梯度累积步数4训练1个epoch。对于每个查询三元组,采样3个同关系支持三元组、6条推理路径和6个邻域事实,并为每个正样本构造12个负样本指令。所有实验在配备2颗Intel Xeon Platinum 8358处理器和8张NVIDIA A100 40G GPU的服务器上完成。平均耗时方面,CATS微调需2.4小时,单个测试样本的评估与排序耗时1.43秒。
主要结果
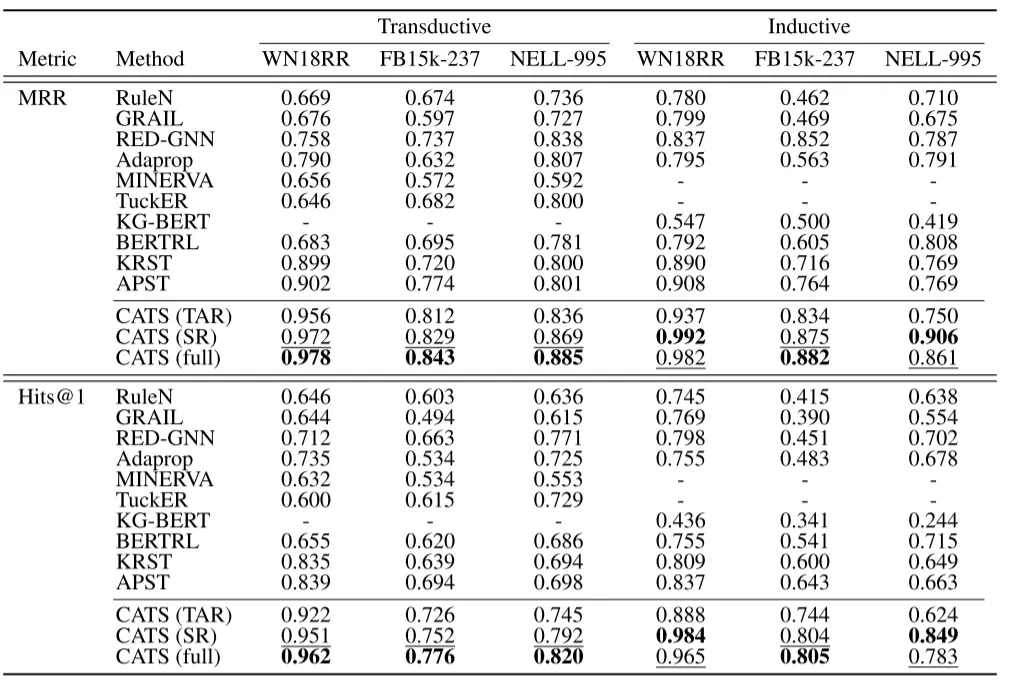
在直推式和归纳式设定下的实验表明,CATS(完整版)显著且稳定地超越所有基线方法。尤其在归纳设定中,WN18RR、FB15k-237和NELL-995数据集的Hits@1分别绝对提升12.8%、16.2%和6.8%;直推设定下的提升幅度分别为12.3%、8.2%和9.1%。在CATS的变体中,"完整版"在6个案例中的4个取得最佳结果,验证了联合利用潜在类型约束和子图上下文的重要性。TAR变体在直推场景表现更优,因其依赖训练图中已知实体的类型信息;而SR变体通过从测试图采样的邻域事实和路径,在归纳场景展现更强性能。
消融研究
RQ1:小样本场景下的有效性在训练图仅含1000或2000个三元组的极端稀疏设定下,CATS在12个案例中的10个实现MRR显著提升。TAR变体在直推场景优于SR,因稀疏性限制了邻域事实和路径的采样质量;而归纳场景中SR仍保持优势,因其依赖测试图的补充结构信息。值得注意的是,在训练三元组较少的NELL-995直推设定中,CATS未达最优性能,表明极稀疏结构会降低模型上限。
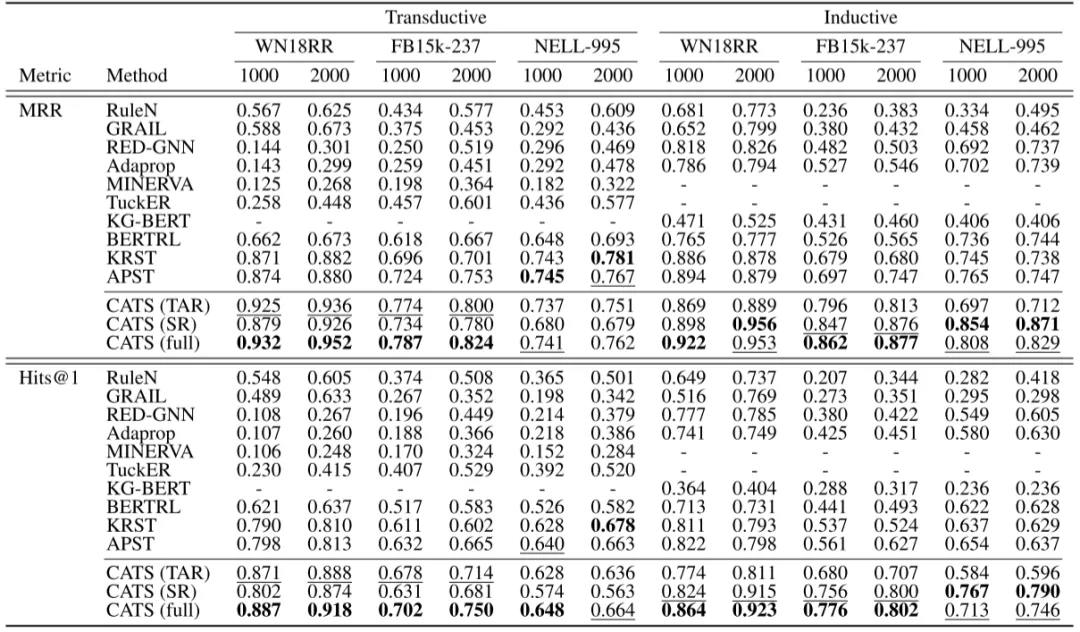
RQ2:推理路径与邻域事实的作用实验表明两者均能提升性能,但邻域事实的贡献更显著。移除路径过滤步骤会导致性能下降,验证了基于度数的过滤机制有效性。
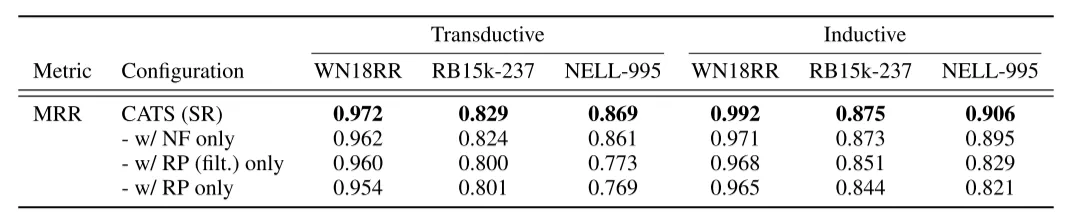
RQ3:大语言模型内部知识的影响零样本实验显示,未经微调的LLM无法可靠评估三元组,表明性能提升并非源于模型预训练知识。仅依赖提示词而无监督微调的版本同样表现不佳,证实自然语言与知识图谱三元组间存在语义鸿沟。
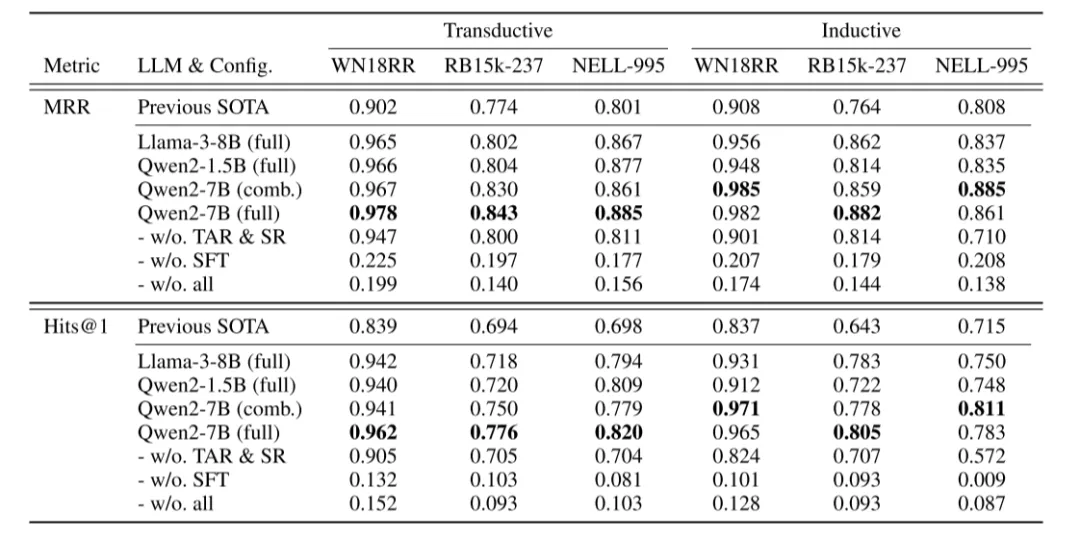
RQ4:模型规模的影响在Llama3-8B、Qwen2-1.5B和Qwen2-7B上的实验表明,CATS在不同规模模型上均显著优于基线。Qwen2-1.5B将平均推理时间降至0.51秒,实现效率与性能的平衡,而Qwen2-7B的进一步提升说明模型规模可能带来增益。
结论
本文提出了CATS,一种新颖的上下文感知知识图谱补全方法。CATS通过引导LLM基于潜在类型约束、筛选的推理路径和相关邻域事实来评估查询三元组的合理性。在适当的提示和监督微调(SFT)的充分指导下,CATS在直推式、归纳式和少样本场景下均实现了最先进的性能,展现了其鲁棒性和泛化能力。总体而言,CATS展示了利用LLM在结构化数据上进行知识密集型推理任务的潜力。
编辑:文婧
