小红书&西交大开源DeepEyes模型,无需依赖复杂工作流或大规模监督数据,通过端到端强化学习实现视觉与文本深度融合,复现OpenAI o3 “用图思考”能力。
原文标题:OpenAI未公开的o3「用图思考」技术,被小红书、西安交大尝试实现了
原文作者:机器之心
冷月清谈:
怜星夜思:
2、DeepEyes 的成功,是否意味着端到端强化学习将成为多模态模型训练的主流方法? 传统的监督微调(SFT)方法是否还有存在的价值?
3、DeepEyes 模型强调了不需要依赖外部 OCR 工具,那么对于一些极端情况,比如图像文字非常模糊或者字体非常特殊,DeepEyes 如何保证识别的准确率?是否可以考虑结合外部工具来提升鲁棒性?
原文内容

OpenAI 推出的 o3 推理模型,打破了传统文字思维链的边界 —— 多模态模型首次实现将图像直接融入推理过程。它不仅 “看图”,还能 “用图思考”,开启了视觉与文本推理深度融合的问题求解方式。例如,面对一张物理试卷图像,o3 能自动聚焦公式区域,分析变量关系,并结合知识库推导出答案;在解析建筑图纸时,o3 可在推理过程中旋转或裁剪局部结构,判断承重设计是否合理。这种 “Thinking with Images” 的能力,使 o3 在视觉推理基准测试 V* Bench 上准确率飙升至 95.7%,刷新了多模态模型的推理上限。
然而,OpenAI 如何赋予 o3 这一能力,学界和工业界仍不得而知。为此,小红书团队联合西安交通大学,采用端到端强化学习,在完全不依赖监督微调(SFT)的前提下,激发了大模型 “以图深思” 的潜能,构建出多模态深度思考模型 DeepEyes,首次实现了与 o3 类似的用图像进行思考的能力,并已同步开源相关技术细节,让 “用图像思考” 不再是 OpenAI 专属。

-
论文地址:https://arxiv.org/abs/2505.14362
-
项目地址:https://visual-agent.github.io/
-
Github 地址:https://github.com/Visual-Agent/DeepEyes
用图像进行思考
近期,受到 R1 的启发,出现不少多模态模型采用以文本为核心的思考方式,即 “先看后想”—— 模型先观察图像,再通过纯文本推理来解决复杂的多模态问题。然而,这种方法存在显著局限:一旦进入推理阶段,模型无法 “回看图像” 来补充或验证细节信息,容易导致理解偏差或信息缺失。
相比较之下,更为有效的多模思考方式应是 “边看边想”—— 模型在推理过程中能够动态地调用图像信息,结合视觉与语言的交替交互,从而增强对细节的感知与理解。这种把图像融入思考过程不仅提升了模型应对复杂任务的灵活性,也显著增强了其多模态理解与推理能力。
我们先简单感受一下 DeepEyes 和 o3 是如何结合图像进行推理的!


DeepEyes 与 o3 的推理流程对比
我们使用与 OpenAI o3 官方评测中相同的图像进行测试。测试用户提出问题 “What is written on the sign?”(牌子上写了什么?),DeepEyes 展现出与 o3 类似的 “用图像思考” 的能力,整个过程可分为三步:
第一步:全局视觉分析
模型快速扫描图像,利用自身的视觉感知能力精准锁定画面中的矩形牌子区域,并识别其为文字信息载体。
第二步:智能工具调用
鉴于原图中文字区域分辨率较低,模型自主决策调用图像缩放工具,生成边界框并裁剪放大目标区域,使内容清晰可辨。
第三步:细节推理识别
在清晰图像的基础上,模型结合视觉和文本推理能力,准确识别并输出牌子上的文字:Ochsner URGENT CARE。
整个流程无需依赖任何外部 OCR 工具,纯粹通过模型内部的定位、变换和推理完成识别任务,充分展示了 DeepEyes 原生的 “看图思考” 能力。
DeepEyes:激发模型原生的用图像思考能力
一、模型结构
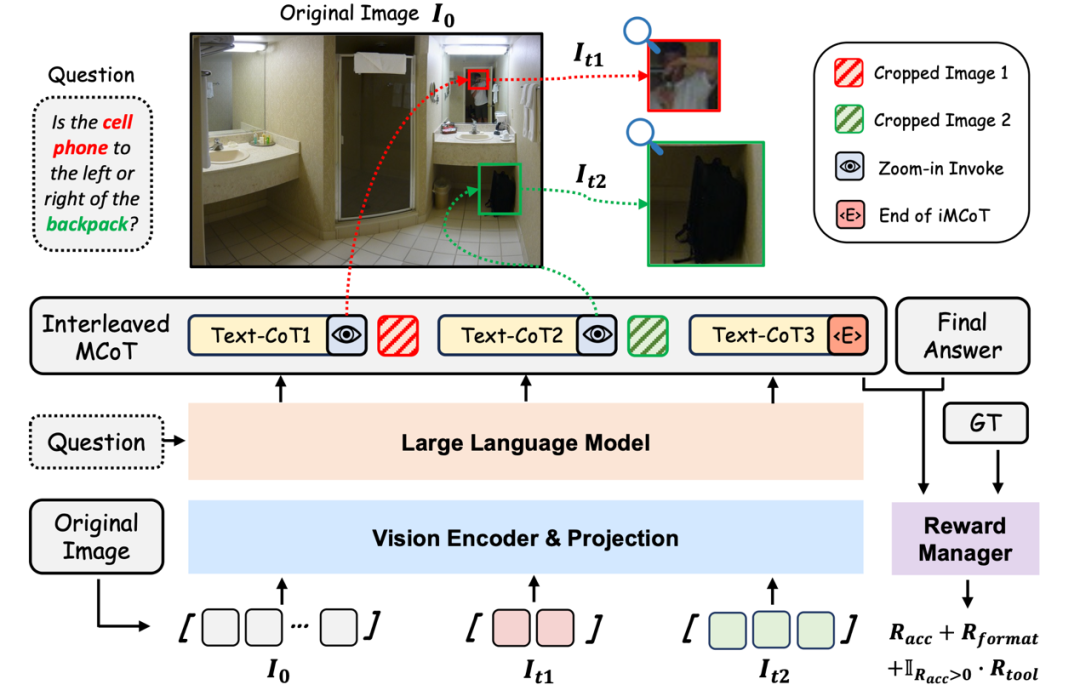
DeepEyes 的架构与传统多模态推理模型一致,但在推理流程上引入了 “自驱动视觉聚焦” 机制。推理起始阶段,模型首先基于文本内容构建初步思维链。例如,在判断 “手机与背包的位置关系” 这一问题时,模型会生成内部推理如:“需要确定手机与背包的位置,可能需在图像中定位相关物体”。随后,模型根据推理进展判断是否需要图像辅助信息。若问题涉及小物体、模糊区域或细节不清晰的区域,模型将自主生成边界框坐标,裁剪图像中可能包含关键信息的区域(如手机和背包位置),并聚焦这些区域进行深入分析。裁剪图像随后以自回归方式重新输入模型,作为新的视觉证据,与现有文本推理共同作用,驱动后续推理过程更加准确、具备视觉上下文感知能力。
二、如何获得用图像进行思考的能力?从生物进化的角度进行思考
直观来看,如果希望模型掌握利用工具进行图像分析的能力,就应提前准备一批调用工具的思维链数据,并通过监督微调(SFT)逐步训练模型,从模仿过渡到真正掌握这种能力。不少多模态模型会采用「先监督,后强化」的训练路径:先用推理数据进行冷启动,让模型 “学会思考”,再通过强化学习(RL)提升其推理上限。
不过,这种能力形成的路径与生物进化迥异。例如,生活在约 3.75 亿年前的提塔利克鱼是鱼类向陆生脊椎动物演化的关键过渡物种。它并非通过模仿其他生物在陆地上的行为获得生存能力,而是在水陆环境差异巨大、旧能力难以应对新环境时,原生出一种全新的适应机制 [Nature. 440 (7085): 757–763]。
类比来看,如果将大模型视作一种 “生物”,是否也能在训练环境和奖励结构发生巨大变化时,像提塔利克鱼一样,激发出原本不具备的新能力?

三、基于 outcome-based 奖励的端到端强化学习策略
受提塔利克鱼进化机制的启发,我们设计了一套具备难度差异的数据集,用于有效激发大模型的工具使用能力。数据筛选和构建遵循以下三项原则:(1)剔除过难或过易的问题;(2)优先选取通过图像分析工具可以显著提升信息增益的样本;(3)补充传统推理数据,以维持图像领域的推理能力。数据集的构建细节可参考原文及代码实现。
在这套具备难度与奖励差异的数据集上,我们发现,即使不经过 SFT 冷启动,仅依赖端到端的强化学习,也能有效激发模型的调用工具进行图像推理的能力。具体来说,DeepEyes 使用了如下的 outcome-based 奖励函数:
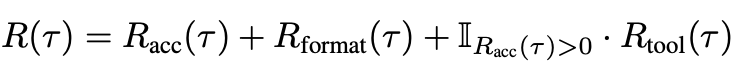
奖励函数分为准确率奖励,格式奖励,以及条件工具奖励。准确率奖励和格式奖励与 R1 的奖励类似,而条件工具奖励则是只有当模型正确回答且正确使用工具才会给予额外的奖励,指导模型在必要时候使用工具。
在上述奖励函数的激励下,DeepEyes 将在学习用图像推理的过程中,从最开始的「盲目尝试」,再到后期的「有效调用」,呈现出了与人类类似的学习模式。具体而言,学习过程可以分为三个阶段:
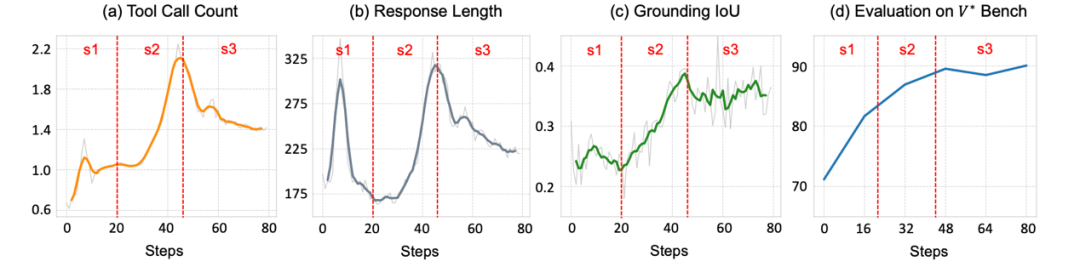
1. 懵懂期(前 20 步):DeepEyes 像新手一样乱点屏幕,随便框选区域,结果十次有九次「瞄错地方」,准确率较差;
2. 探索期(20-45 步):DeepEyes 开启「广撒网模式」,疯狂调用工具缩放各种区域,虽然准确率提升,但像「多动症患者」一样生成冗长响应;
3. 成熟期(45 步后):DeepEyes 突然「开悟」,学会先在脑子里「预判」关键区域,再精准缩放验证,工具调用次数不断减少,准确率却持续提升。
DeepEyes 性能评估
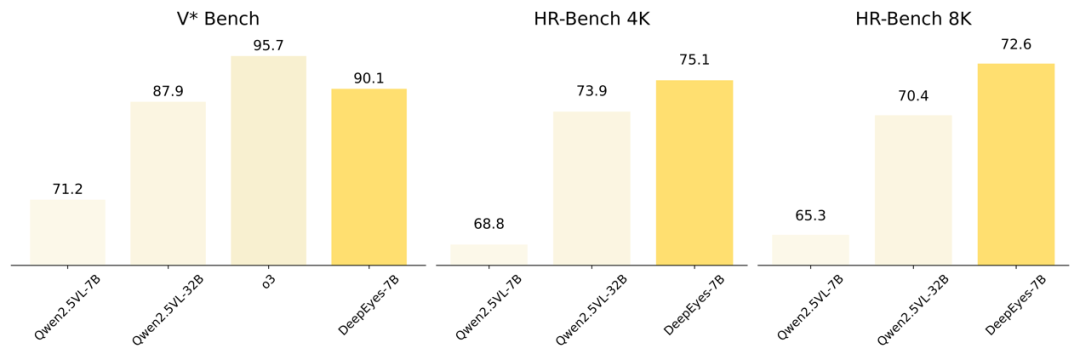
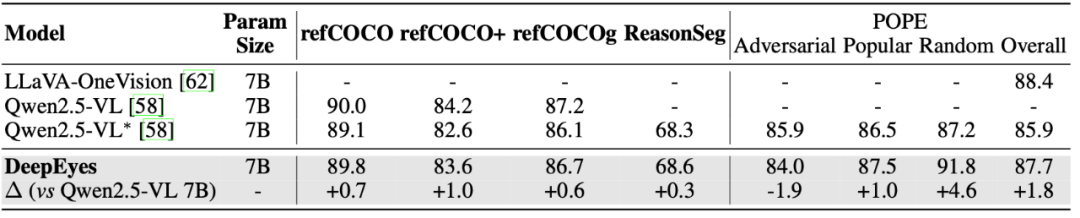

DeepEyes 在多个测试集上表现出色,尤其在视觉搜索任务中展现出领先优势。在 V* Bench 上取得了 90.1 的准确率,在 HR-Bench 上也大幅超越现有的基于工作流的方法。另外,DeepEyes 7B 模型在视觉搜索任务中显出高于 Qwen-VL 32B 模型,这也进一步说明了构建用图像思考能力的必要性。
值得一提的是,DeepEyes 在无需调用任何外部工具的情况下,便具备出色的图像定位与理解能力,这些能力完全由模型自身学习获得。同时,当需要更高精度时,DeepEyes 也可以选择调用工具对图像细节进行确认,从而在降低幻觉方面取得改进。
此外,除了视觉感知,DeepEyes 的数学推理能力也有明显提升,展现出多模态模型在跨任务能力上的潜力。
DeepEyes 的独特优势
与传统的基于工作流或纯文本推理的模型相比,DeepEyes 具备以下关键优势:
1. 训练更简洁:传统方法依赖大量难以构建的 SFT 数据,而 DeepEyes 仅需问答对即可训练,大幅降低数据获取门槛。
2. 更强泛化能力:基于工作流的模型受限于人工规则设计,适用范围有限。DeepEyes 通过端到端强化学习,能在不同任务中动态选择推理路径,展现出跨任务泛化能力。
3. 端到端联合优化:工作流方法通常对各子模块独立优化,容易陷入次优。DeepEyes 通过端到端强化学习实现全局联合优化,显著提升整体性能。
4. 深度多模态融合:相比纯文本推理,DeepEyes 构建融合视觉与文本的思维链,在推理过程中动态交织图像与语言信息,提升感知与决策精度。
5. 原生工具调用能力:DeepEyes 依靠内生视觉定位能力而非外部工具,能原生执行 “图像思考” 流程。工具使用过程可被直接优化,实现更高效、更准确的图像辅助推理,这是传统外部调用方法所不具备的能力。
结语
DeepEyes 展示了多模态推理模型的新范式:无需依赖复杂工作流或大规模监督数据,通过端到端强化学习,即可实现视觉与文本深度融合、原生工具调用和动态推理路径选择。它不仅降低了训练门槛,还显著提升了泛化能力和整体性能。在多个视觉推理任务中,DeepEyes 已成功展现出与 OpenAI o3 相当的 “图像思考” 能力,为开放世界的多模态智能探索提供了切实可行的新路径。
作者介绍
本文作者来自小红书和西安交通大学,其中郑子维、Michael Yang、Jack Hong 和 Chenxiao Zhao 为共同一作,排名不分先后。郑子维,就读于西安交通大学,主要研究方向是 VLM Reasoning、Agent 以及视频理解;Michael Yang 的研究方向是 RL、LLM Reasoning 以及 Agent;Jack Hong 的研究方向为多模态大模型、LLM Reasoning 以及计算机视觉;Chenxiao Zhao 是小红书 Hi Lab 算法研究员,主要研究方向是 RL。该工作是郑子维、Michael Yang 和 Jack Hong 在小红书实习期间完成。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com