提出双分支知识蒸馏(DBKD)模型用于异常分割,通过多尺度输入重建和特征提取增强模型表示能力,在MVTec AD数据集上达到SOTA。
原文标题:TIM 2025 | 通过残差特征聚合模块的双分支知识蒸馏用于异常分割
原文作者:数据派THU
冷月清谈:
本文提出了一种名为双分支知识蒸馏(DBKD)的异常分割新方法,旨在解决现有基于知识蒸馏的异常检测方法中存在的模型表示能力有限和异常响应消失问题。该方法通过引入多尺度输入重建分支和多尺度特征信息提取分支,增强了模型对异常样本的表示能力。同时,设计了残差特征聚合模块(RFAM)来压缩教师网络的高维特征,确保输入到多尺度输入重建分支的信息有效性。实验结果表明,DBKD在MVTec AD数据集上取得了最先进的性能。
怜星夜思:
1、这个DBKD方法在实际工业应用中,除了MVTec AD数据集,还有哪些潜在的应用场景?
2、论文中提到的残差特征聚合模块(RFAM)是如何平衡计算效率和特征表示质量的?
3、知识蒸馏中,教师网络的选择对学生网络的性能影响大吗?如果想进一步提升DBKD的效果,除了优化网络结构和损失函数,还可以从哪些方面入手?
2、论文中提到的残差特征聚合模块(RFAM)是如何平衡计算效率和特征表示质量的?
3、知识蒸馏中,教师网络的选择对学生网络的性能影响大吗?如果想进一步提升DBKD的效果,除了优化网络结构和损失函数,还可以从哪些方面入手?
原文内容

来源:PaperEveryday本文约2800字,建议阅读5分钟本文通过提高模型表示的多样性来解决异常响应消失的问题。本文提出的双分支知识蒸馏(DBKD)模型中的多尺度输入重建分支通过恢复输入的多尺度表示来提高其表示能力。
论文信息
题目:Dual-Branch Knowledge Distillation via Residual Features Aggregation Module for Anomaly Segmentation
通过残差特征聚合模块的双分支知识蒸馏用于异常分割
作者:You Zhou, Zihao Huang, Deyu Zeng, Yanyun Qu, Zongze Wu
源码链接:https://github.com/EWAN9709/DBKD
论文创新点
-
双分支知识蒸馏框架:论文提出了一个双分支知识蒸馏(DBKD)框架,通过引入多尺度输入重建分支和多尺度特征信息提取分支,增强了模型对异常样本的表示能力。
-
残差特征聚合模块(RFAM):作者设计了一个残差特征聚合模块(RFAM),用于将教师网络的高维特征压缩为紧凑且有效的低维特征嵌入。
-
余弦相似度损失函数:论文提出了一种基于余弦相似度的损失函数,用于衡量教师网络和学生网络之间的特征差异。
-
多尺度异常检测与分割:通过多尺度特征提取和多尺度输入重建,DBKD框架能够在多个尺度上捕捉异常信息,从而在图像级异常检测和像素级异常分割任务中取得了显著的性能提升。
摘要
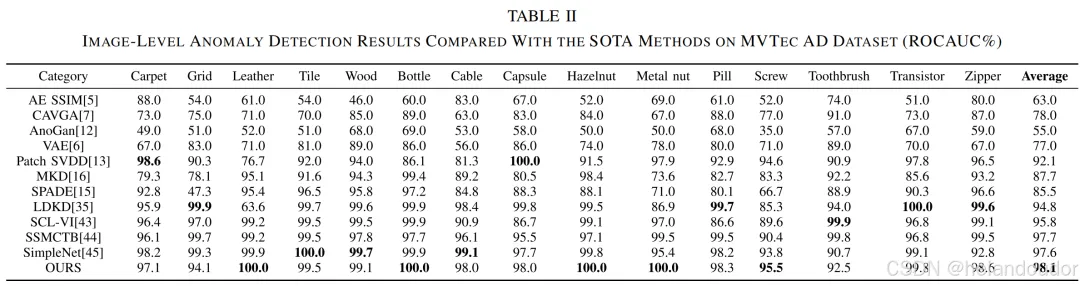
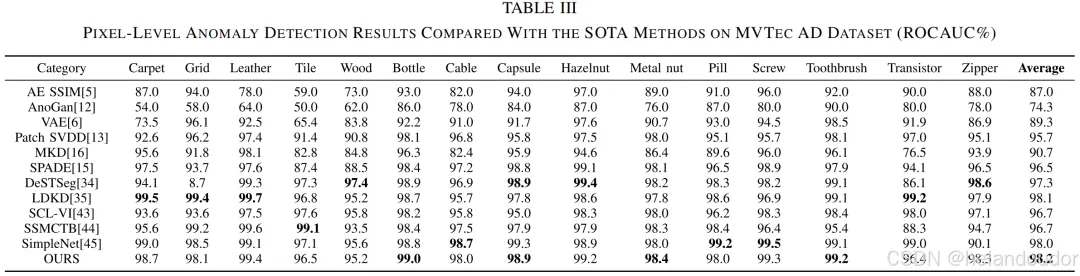
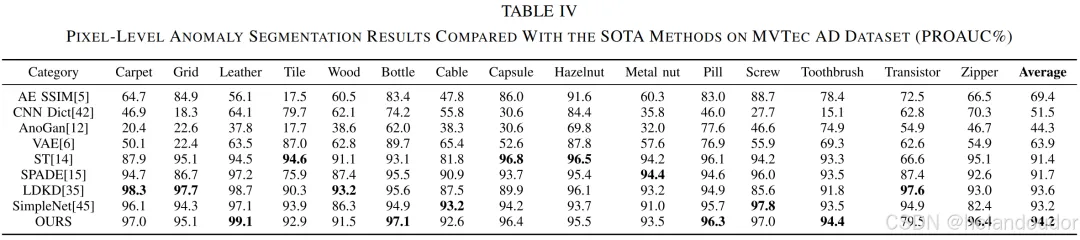
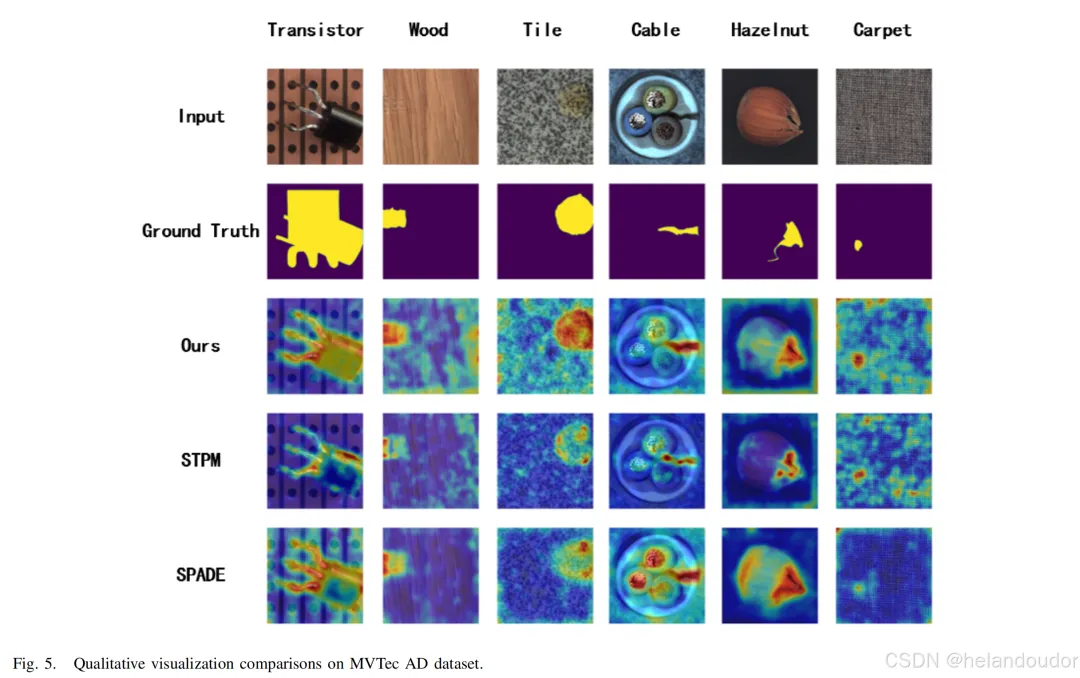
无监督图像异常检测和分割算法在实际工业质量检测过程中具有重要意义。基于知识蒸馏框架的异常检测方法通过表征异常样本之间的差异来检测异常。该方法使用相似的模型结构构建教师和学生网络,导致模型表示能力有限,并且由于异常激活值的消失而导致检测失败。本文通过提高模型表示的多样性来解决异常响应消失的问题。本文提出的双分支知识蒸馏(DBKD)模型中的多尺度输入重建分支通过恢复输入的多尺度表示来提高其表示能力。多尺度特征信息提取分支通过提取不同尺度的特征信息来增强其捕捉缺陷细节信息的能力。此外,作者设计了一个残差特征聚合模块(RFAM),将教师模型的高维特征压缩为紧凑且有效的低维特征嵌入,确保多尺度输入重建分支输入的有效性。所提出的DBKD在著名的MVTec AD数据集上达到了最新的最先进水平(SOTA),在15个类别中的异常检测和异常分割的接收者操作特征曲线下面积(ROCAUC)分别为98.1%和98.2%
关键词
异常检测,异常分割,特征嵌入,知识蒸馏,无监督学习。
III. 双分支知识蒸馏框架
架构
如图3所示,DBKD主要由教师网络、上采样学生网络和下采样学生网络组成。作者使用在ImageNet数据集上预训练的ResNet34和WideResNet50作为教师网络的骨干网络,其作用是提取输入样本的全面特征表示。下采样学生网络与教师网络具有相同的输入和结构,因此可以充分利用教师网络中不同维度特征层的详细信息。上采样学生网络使用与教师网络不对称的反卷积层,以提高特征恢复能力,从而增强DBKD对异常的表示多样性,同时避免激活差异消失的问题。为了确保异常样本在特征空间中的分布差异,并使上采样学生网络获得紧凑且有效的信息,作者设计了一个可训练的RFAM来连接教师网络和上采样学生网络。
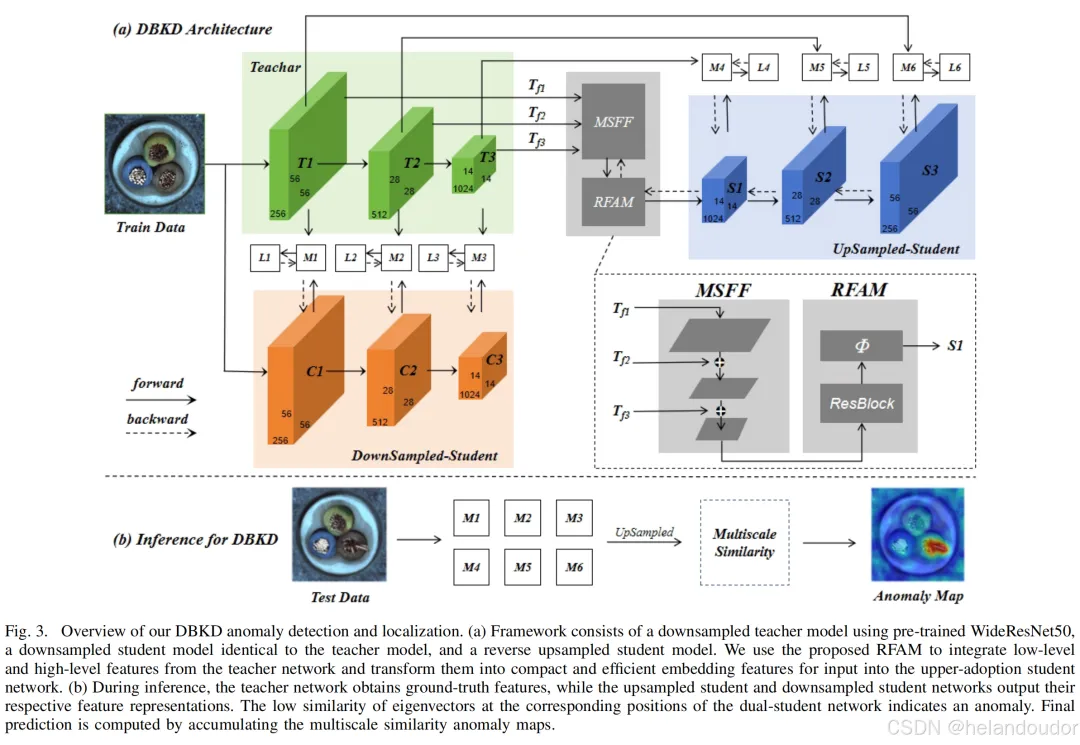
残差特征聚合模块
为了使上采样学生模型的输入对异常检测有效,作者设计了一个特征嵌入模块,如图4所示。下采样学生模型和下采样教师模型具有相同的输入和相同的模型结构,因此知识可以轻松有效地从教师模型传递到学生模型,然后基于特征空间中的分布差异实现正常样本和异常样本之间的差异。然而,由于上采样学生模型的输入是一组低分辨率特征图,这些低分辨率特征图通过多次下采样操作(如池化操作或卷积操作)获得,以便提取更高级别的抽象特征。由于作者需要对这些特征图进行上采样,并与教师模型中间层的输出进行比较,特征空间中的分布差异可以区分正常样本和异常样本。因此,上采样学生模型的输入选择变得更加重要。此外,与一般的上采样模型不同,作者在上采样过程中无法获得下采样模型的中间表示。当作者在上采样过程中添加教师模型的中间表示时,教师模型中异常样本的知识也会被传递。在上采样过程中,异常样本的激活差异消失,因此作者要求上采样学生模型的输入既包含丰富的全局信息,又包含对恢复中间层特征有效的语义信息。
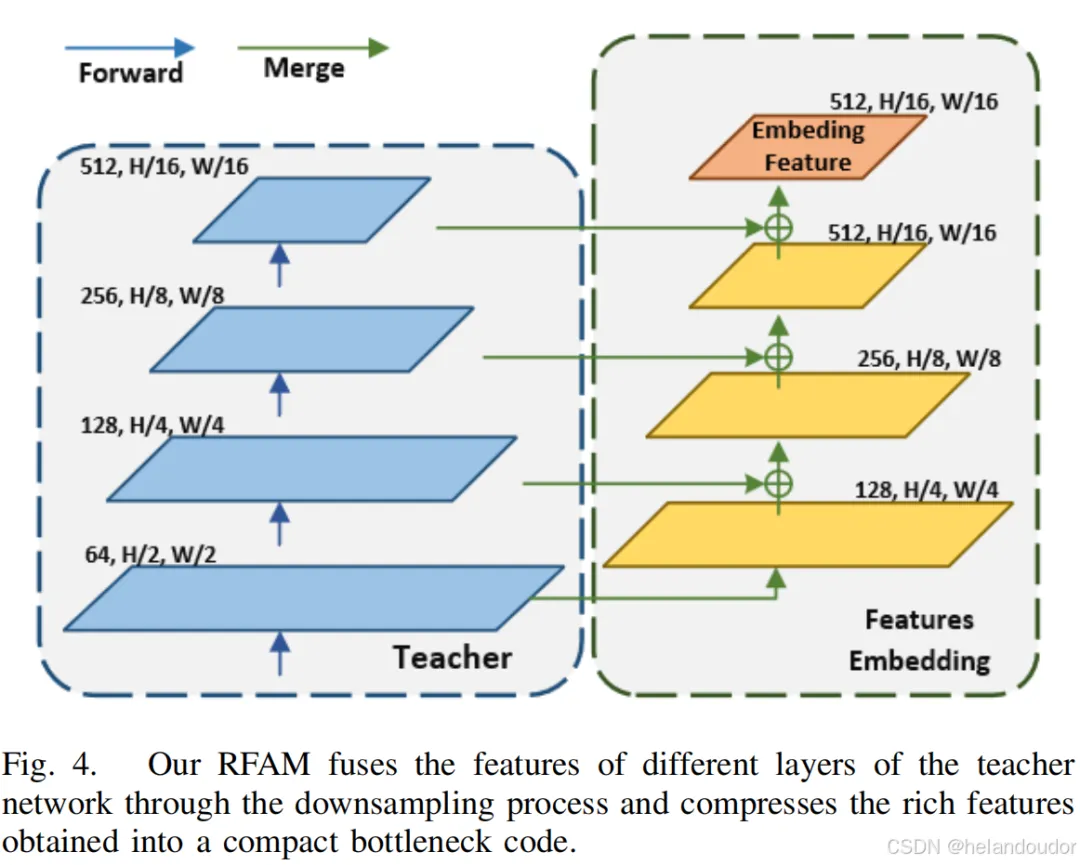
与直接使用下采样最后一层的常规上采样模型不同,在作者的上采样学生模型中,作者不仅使用教师模型第四层的输出特征作为输入。这是因为第四层的输出特征提取了深度和高级特征,如对象部分、结构和组成。仅使用该层的特征进行上采样,难以重建浅层特征。因此,作者需要对教师模型进行多尺度特征融合,以增强模型对输入特征的表示能力。如图4所示,作者提出的特征嵌入模块通过训练一个编码器获得有助于恢复教师模型中间层特征的嵌入向量,将教师模型的第一层特征作为特征嵌入模块的输入,并对特征图执行以下步骤:采样后与下一层的特征级联,然后进行下采样,直到收集到教师模型总共四层的特征,并获得对上采样学生模型恢复浅层特征非常有效的嵌入特征。在下采样过程中,使用WideResNet50中的BottleneckBlock,它由三个卷积层组成,其中第一个卷积层使用 卷积核减少特征图的通道数,第二个卷积层使用 卷积核进行特征提取,第三个卷积层使用 卷积核增加特征图的通道数。BottleneckBlock通过减少参数数量同时保持高质量的特征表示来提高计算效率。作为上采样学生模型的前置模块,特征嵌入模块可以有效地捕捉正常样本多尺度特征块中的有用信息,从而提高对更准确浅层特征的恢复。对于异常样本,特征嵌入模块为后续的异常检测任务提供了更具判别性的特征表示。
损失函数
数学上,设 表示从下采样教师模型到上采样学生模型嵌入空间的映射。作者DBKD模型中的配对激活对应关系为,其中 、 和 分别表示下采样学生模型、教师模型和上采样学生模型中的第 个块。,其中 、 和 表示第 层激活张量的通道数、高度和宽度。对于DBKD模型中的知识转移,作者设计了一个以余弦相似度为中心的损失函数,因为它更精确地捕捉了高维和低维信息之间的关系。具体来说,对于特征张量 、 和 ,作者计算它们之间的余弦相似度损失,以获得一个二维异常图 :
其中, 和 表示特征层的宽度和高度。 值越大,该位置的异常值越高。考虑到多尺度知识蒸馏方法,通过累积多尺度异常图获得学生优化的标量损失函数,其中 是实验中使用的特征层数:
在推理期间,当样本异常时,具有强大表征能力的教师模型可以反映其异常特征。然而,仅学习正样本的学生模型无法正确表示异常特征,接受教师模型有效输出的上采样学生网络也将与样本对应标准的学生网络的特征图有很大不同。由于结构不一致,当查询异常时,两个学生网络将与教师有不同的表示。从公式(2)中,DBKD获得了一组异常图,其中异常图 中的值反映了第 个特征图中特征的像素级异常。如果获得公式(3),则在双线性插值上进行上采样。作者可以使用异常响应图的上采样来定位查询图像中的缺陷。准确的评分图 将指示所有异常图中像素的累积:
IV. 实验
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。
编辑:文婧
