ICML 2025 Spotlight 论文提出多智能体系统「自动化失败归因」,构建数据集 Who&When,探索 AI 自动定位出错 Agent 和环节。能否让AI成为智能系统的“故障侦探”?
原文标题:ICML 2025 Spotlight | 谁导致了多智能体系统的失败?首个「自动化失败归因」研究出炉
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到当前 SOTA 模型在失败归因任务上的表现不理想,你认为这背后的原因是什么?未来有哪些可能的改进方向?
3、文章指出失败归因是连接评估与改进的缺失环节,你认为自动化失败归因的实现,会对多智能体系统的开发和应用带来哪些具体的影响?
原文内容

想象这样一个场景:你开发了一个由多个大型语言模型 Agent 组成的智能团队,它们协作完成复杂任务,比如一个 Agent 负责检索,一个负责决策。然而任务失败了,结果不对。
问题来了:到底是哪个 Agent 出了错?又是在对话流程的哪一环节?调试这样的多智能体系统如同大海捞针,需要翻阅大量复杂日志,极其耗时。
这并非虚构。在多智能体 LLM 系统中,失败常见但难以诊断。随着这类系统愈加普及,我们急需新方法快速定位错误。正因如此,ICML 2025 的一篇 Spotlight 论文提出了「自动化失败归因(Automated Failure Attribution)」的新研究方向,目标是让 AI 自动回答:是谁、在哪一步导致了失败。
该工作由 Penn State、Duke、UW、Goolge DeepMind 等机构的多位研究人员合作完成。

-
论文标题:Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
-
arXiv 地址:https://arxiv.org/pdf/2505.00212
-
代码地址:https://github.com/mingyin1/Agents_Failure_Attribution
背景挑战
LLM 驱动的多智能体系统在诸多领域展现出巨大潜力,从自动化助手协同办公到多 Agent 合作完成 Web 复杂操作等。然而,这些系统脆弱性也逐渐显现:多个 Agent 之间的误解、信息传递错误或决策不当,都可能导致整体任务失败。
对于开发者来说,一个失败案例往往意味着必须手动审阅长长的对话日志,试图找出哪个 Agent 在哪一步出了差错。这种调试过程既费时费力,也需要调试者对整个任务逻辑非常熟悉。更大的挑战在于,缺乏系统化的方法来定位失败原因 —— 传统评估只关注任务成功与否,但很少深入到「失败责任」这一层面上。
结果就是,多智能体系统一旦出错,我们往往只能知道「出了问题」却无法快速知道「问题出在哪、因何而起」。这种局面严重限制了多智能体系统的改进和可信度。如果无法自动归因失败,我们就难以针对性地加强某个 Agent 的能力或优化协作策略。换言之,失败归因是连接评估与改进的缺失环节。
研究内容
针对上述挑战,这篇 ICML 2025 Spotlight 论文率先提出并 formalize 了 LLM 多智能体系统的自动化失败归因这一新任务。
研究的核心目标:给定一个多 Agent 协作任务的失败日志,自动确定导致失败的罪魁祸首是哪个 Agent(「Who」),以及决定性错误发生在交互的哪一步(「When」)。
为推动这一方向,作者构建了首个用于失败归因研究的基准数据集 ——「Who&When」。该数据集精心收集了 127 个多智能体系统的失败日志,涵盖了多个公开基准(如 GAIA、AssistantBench 等)中的复杂任务,具有相当的多样性。更重要的是,作者为每条失败日志都提供了细粒度的人工标注:
-
标记出导致任务失败的责任 Agent(即「Who」,哪个智能体犯了错)
-
标记出导致失败的关键错误步骤(即「When」,在整个对话 / 操作序列中的第几步出了错)
-
以及相应的自然语言解释(即「Why」,为什么这个错误会导致失败)
基准数据集地址:https://huggingface.co/datasets/Kevin355/Who_and_When
这种标注使得数据集既可用于训练模型自动定位「谁」和「何时」出错,也方便人类分析失败的原因。数据集中「Who」和「When」标注的引入填补了以往多智能体评测中对失败原因关注的空白。可以说,Who&When 数据集为自动失败归因任务提供了首个标准测试床,让研究者能够在统一语境下探索让 AI 自动当「故障侦探」的可能性。
技术细节
有了数据集,接下来作者设计了三种用于自动失败归因的初步方法,并对它们进行了系统比较:
-
All-at-Once 方法:将完整的多 Agent 日志一次性交给 LLM,让其整体判断 「哪个 Agent 在哪一步出错」。优点是调用少、成本低,擅长宏观归因;缺点是信息量大,易错过细节。
-
Step-by-Step 方法:模拟人工调试,让 LLM 逐轮分析每一步交互,逐步定位错误。优点是粒度细、定位准;缺点是调用频繁、成本高,且误判可能累积。
-
Binary Search 方法:对日志进行二分,逐步缩小范围,最终锁定出错步骤。在调用次数和定位精度之间取得平衡,适合长日志。缺点是需要多轮交互,复杂度居中。值得注意的是,每种方法在准确性、成本和粒度上各有权衡,没有一种方法能在所有指标上全面胜出。这三种方案共同构成了自动失败归因任务的初步解法库,探索了从「一步到位」到「循序渐进」再到「折中求解」的不同思路。作者在论文中详细讨论了它们各自的优劣。
实验结果
作者在 Who&When 数据集上对上述方法进行了系统评估,带来了许多发人深省的发现:
-
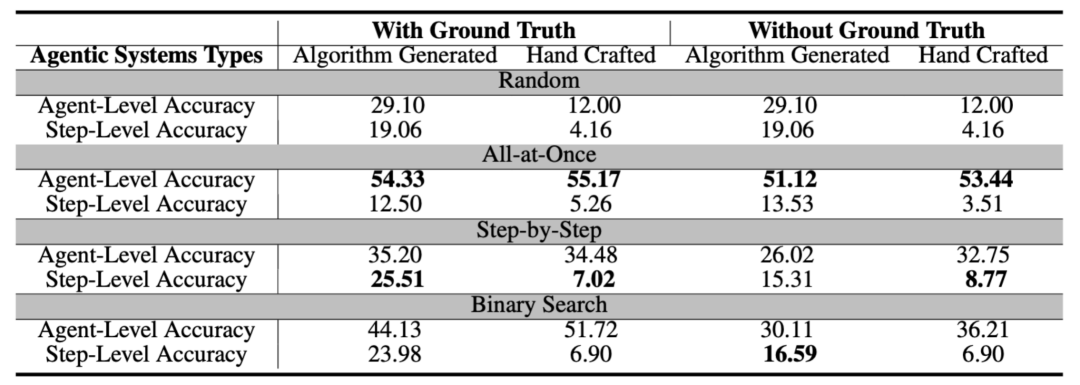
整体表现有限:当前方法效果仍较差。最佳模型在识别出错 Agent 上准确率仅约 53.5%,而准确定位错误步骤的准确率更低,仅 14.2%,几乎接近瞎猜。一些方法甚至表现不如随机,显示任务本身极具挑战性。
-
各有所长:不同方法擅长不同子任务。All-at-Once 更擅长识别「谁」出错,Step-by-Step 更适合找出「何时」出错,而 Binary Search 表现居中,平衡调用成本和定位精度。
-
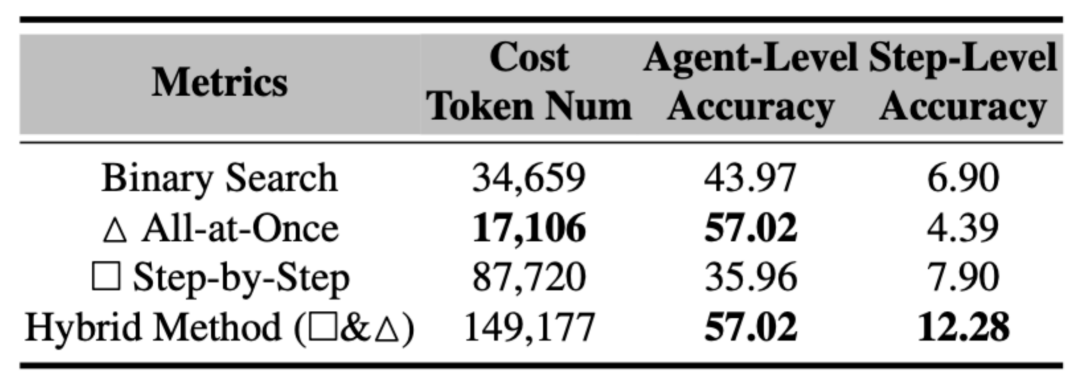
混合策略更优但代价高:将多种方法结合(如先用 All-at-Once 找嫌疑 Agent,再用 Step-by-Step 精查)确实提升了准确率,验证了方法间的互补性。但计算成本显著增加,需在效果与资源之间权衡。
-
现有 SOTA 模型乏力: OpenAI o1 或者 DeepSeek R1,表现仍不理想,远未达到实用水平。可见,失败归因任务对 AI 推理与理解能力的要求,远超当前模型在常规任务中的表现,凸显了其挑战性和研究价值。

结论
自动化失败归因有望成为多智能体 AI 系统开发中的重要一环,它将帮助我们更深入地理解 AI 代理的失败模式,将「哪里出错、谁之过」从令人头疼的谜题变成可量化分析的问题。因此,我们可以在评估与改进之间架起桥梁,打造更可靠、更智能的多 Agent 协作系统。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com