英伟达推出Fast-dLLM,无需训练即可将扩散大语言模型推理速度提升27.6倍,加速长文本生成,同时保证生成质量。
原文标题:谷歌之后,英伟达入局扩散大语言模型,Fast-dLLM推理速度狂飙27.6倍
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 Fast-dLLM 在长文本生成中实现了显著的加速,那么在实际应用中,这种加速对于哪些场景最有价值?例如,是更适合用于生成新闻报道、小说,还是代码?为什么?
3、Fast-dLLM 的核心在于无需重新训练即可加速扩散模型,那么这种“即插即用”的加速方案是否会成为未来 AI 模型优化的一个趋势?如果未来模型越来越大,这种方案是否还有效?
原文内容

在大语言模型(LLM)领域,推理效率是制约其实际应用的关键因素之一。谷歌 DeepMind 的 Gemini diffusion 曾以 1400 tokens / 秒的生成速度震惊学界,展现了扩散模型在并行生成上的潜力。然而,开源扩散 LLM 却因缺乏 KV 缓存机制和并行解码质量衰退,实际推理速度长期被自回归模型压制.
近日,NVIDIA 联合香港大学、MIT 等机构重磅推出 Fast-dLLM,以无需训练的即插即用加速方案,实现了推理速度的突破!

-
论文:Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
-
项目地址:https://nvlabs.github.io/Fast-dLLM
-
论文链接:http://arxiv.org/abs/2505.22618
-
GitHub 链接:https://github.com/NVlabs/Fast-dLLM
通过创新的技术组合,在不依赖重新训练模型的前提下,该工作为扩散模型的推理加速带来了突破性进展。本文将结合具体技术细节与实验数据,解析其核心优势。
一、 核心技术
分块 KV 缓存与置信度感知并行解码
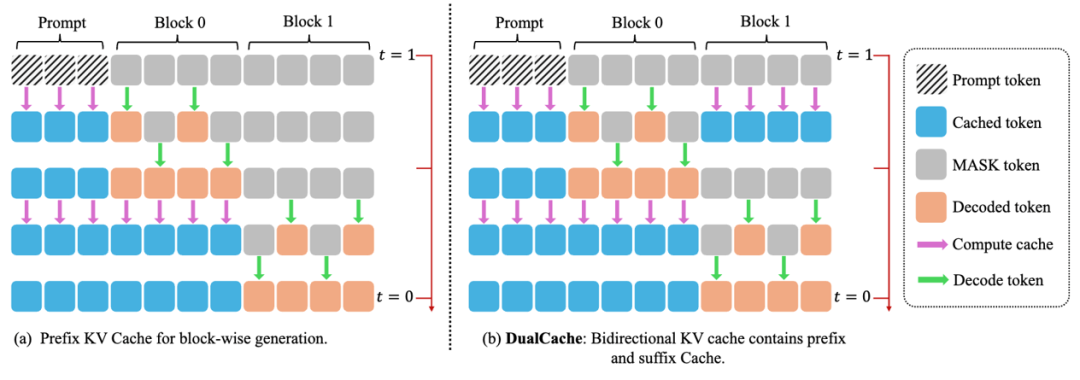
1. 分块 KV 缓存(Block-Wise KV Cache):激活重用率超 90% 的双向加速
传统扩散模型因双向注意力机制难以直接复用计算结果,导致长序列推理效率低下。Fast-dLLM 提出分块 KV 缓存机制,通过以下设计实现高效计算:
-
双向缓存策略:采用 DualCache 同时缓存前缀(Prompt)和后缀(Masked Tokens)的注意力激活值(KV Cache),如图 1 (a)(b) 所示。在分块生成时,前序块的 KV 激活可直接复用于后续块,减少重复计算🔄。
-
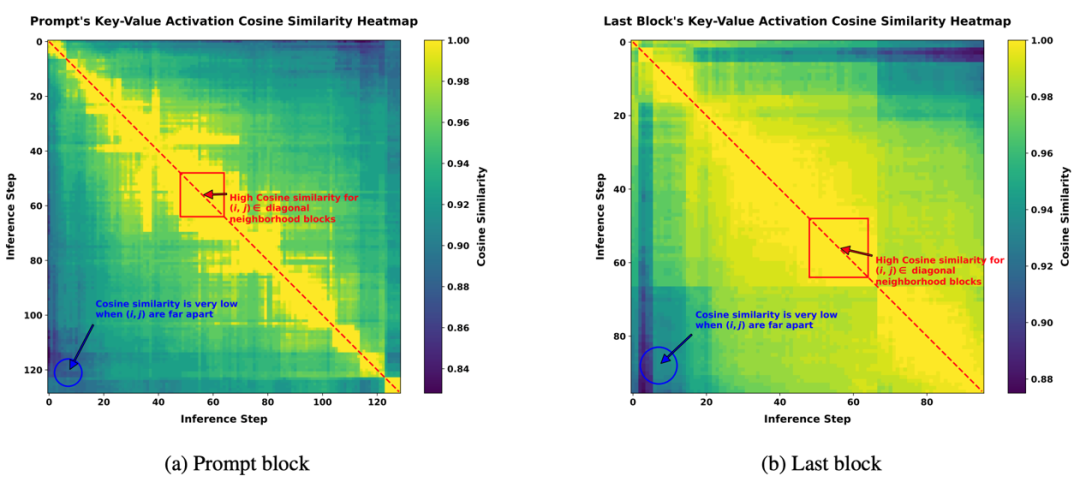
高相似度验证:实验表明,相邻推理步骤的 KV 激活余弦相似度接近 1(图 2),证明缓存复用的可行性。例如,在 LLaDA 模型中,通过缓存可实现 90% 以上的激活重用,单步计算量显著降低。
2. 置信度感知并行解码(Confidence-Aware Parallel Decoding)
并行解码虽能提升速度,但条件独立假设易破坏 token 依赖关系,比方说这个例子 The list of poker hands that consist of two English words are: _ _.。后续两个单词可以是 “high card,” “two pair,” “full house,” 或者是 “straight flush.”。值得注意的是,这两个单词之间存在关联。
然而,MDMs 中的多令牌预测过程首先为每个令牌生成一个概率分布,然后从这些分布中独立采样。这种独立采样可能导致不理想的组合(如生成 “high house” 等无效组合)。Fast-dLLM 通过动态置信度筛选解决这一问题(所谓置信度,是指模型给 token 赋予的概率大小):
-
阈值激活策略:仅对置信度超过阈值(如≥0.9)的 token 进行并行解码,低置信度 token 留待后续步骤处理。如图 3 所示,该策略可在保证生成质量的前提下,并行输出多个 token。
-
理论证明:当 (n+1)ϵ≤1 时(n 为并行解码 token 数,并且并行解码的 n 个 token 的置信度都大于 1-ϵ),贪婪解码策略下并行解码与顺序解码结果一致,从数学层面确保了生成逻辑的连贯性。
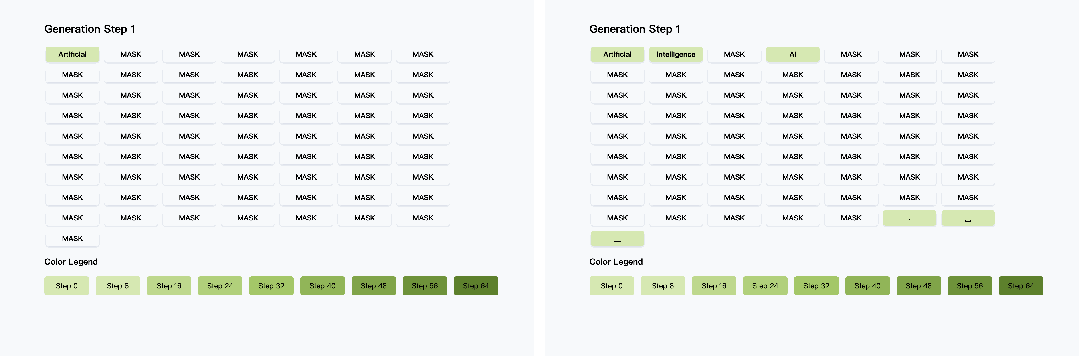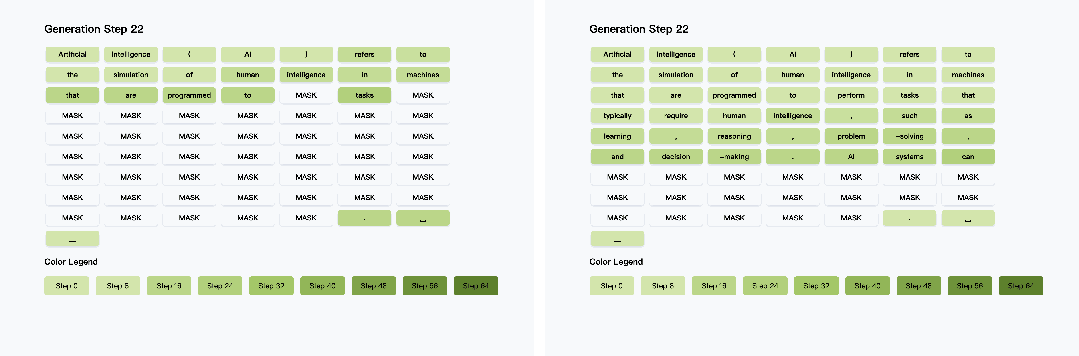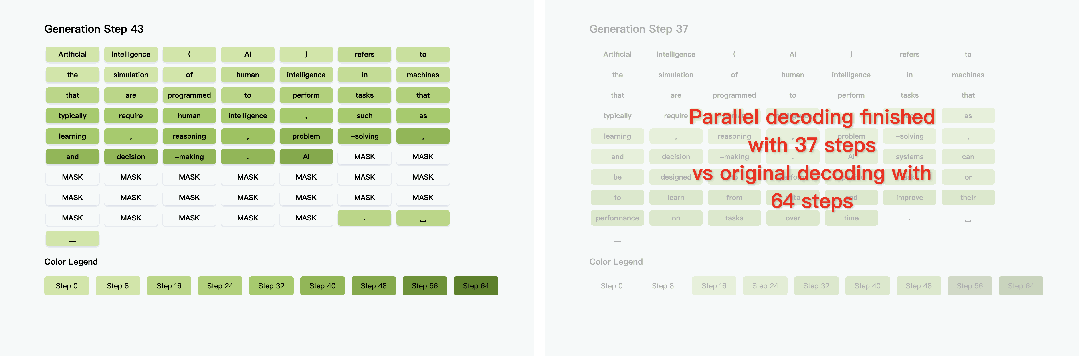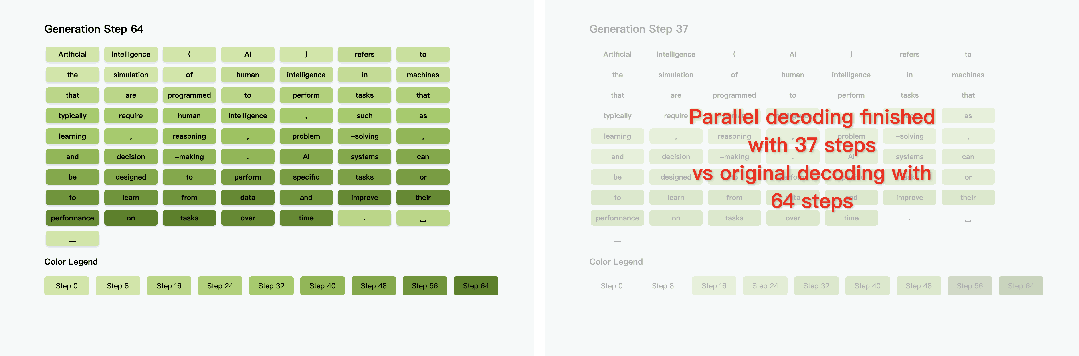
3. 伪代码:分块 KV 缓存与置信度感知并行解码流程
以下是 Fast-dLLM 算法的核心伪代码,结合了分块 KV 缓存以及置信度感知并行解码,无需训练就可以在现有的开源 Diffusion LLM(如 LLaDA、Dream)上即插即用进行推理加速。

二、 性能突破
速度与精度的均衡优化
1. 长文本生成:27.6 倍端到端加速
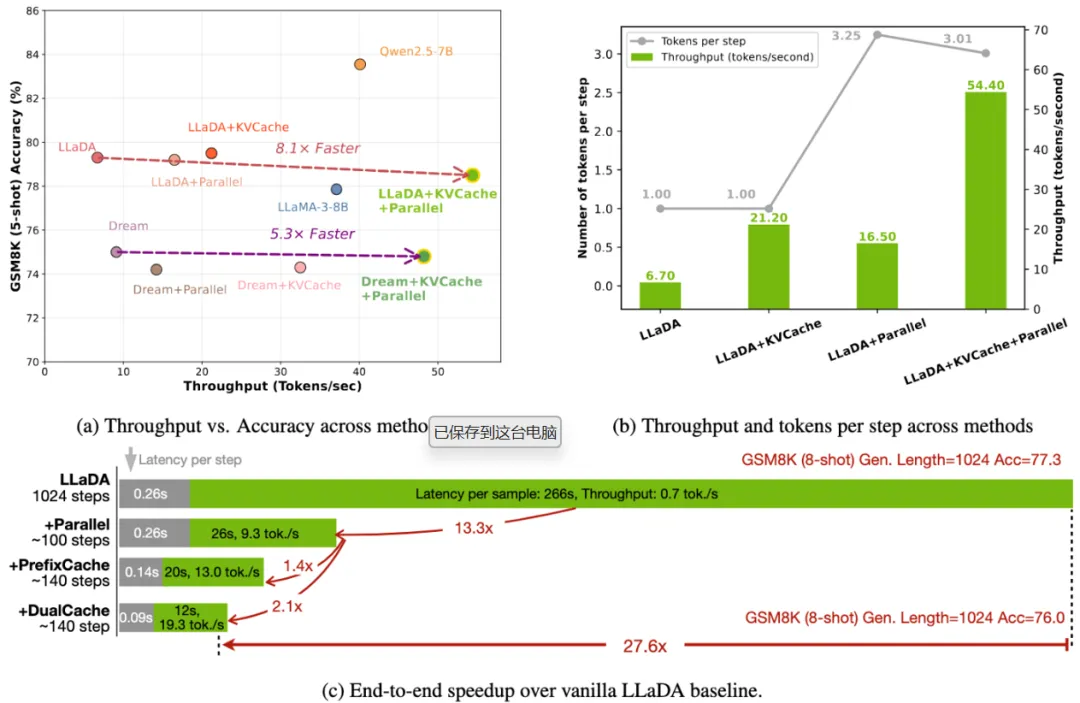
在 LLaDA 模型上,针对 1024 token 的长文本生成任务,Fast-dLLM 将单步延迟从 0.26 秒降至 0.09 秒,整体耗时从 266 秒压缩至 12 秒,实现 27.6 倍端到端加速。这一提升在代码生成、数学推理等长序列场景中尤为显著,例如 8-shot 提示的 GSM8K 任务中,加速后仍能保持 76% 的准确率。
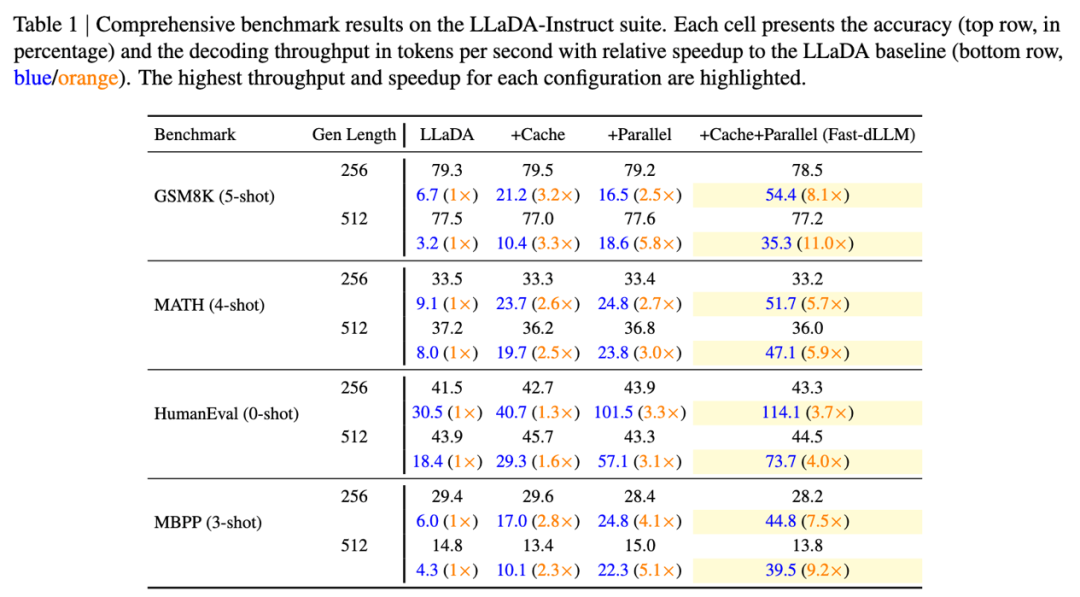
2. 精度保持:损失 < 2% 的基准测试表现
在主流基准测试中,Fast-dLLM 的准确率损失控制在 2% 以内:
-
GSM8K(5-shot):LLaDA+Fast-dLLM 准确率为 78.5%,仅比基线低 0.8%,但吞吐量提升 8.1 倍(图 5)。
-
HumanEval(代码生成):准确率达 44.5%,较基线提升 1.2%,同时吞吐量提升 3.7 倍。
-
多模型兼容:在 LLaDA、Dream 等模型上均实现高效加速,验证了技术的通用性。
三、 应用价值
无需训练的即插即用方案
Fast-dLLM 的零训练成本特性使其成为理想的推理优化工具,能够快速集成到现有的系统中。对于那些已经在使用扩散模型的企业和开发者来说,可以在不改变模型架构和训练流程的基础上,直接利用 Fast-dLLM 提升推理效率,缩短长文本生成耗时,为实际部署提供更可行的方案。
四、 总结与展望
Fast-dLLM 通过分块 KV 缓存与置信度感知并行解码的创新组合,实现了扩散模型推理效率的跨越式提升,同时保持了生成质量的稳定性。其技术设计为非自回归生成模型提供了新的优化范式,有望推动扩散模型在实时交互、长文本生成等场景中的广泛应用。未来,随着模型规模的扩大和蒸馏技术的深化,Fast-dLLM 或将进一步缩小与自回归模型的性能差距,成为 LLM 推理加速的核心方案之一。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com