字节Seed开源8B代码模型Seed-Coder,超越同规模SOTA!核心在于用小模型管理数据,通过自生成和筛选高质量训练数据提升代码生成能力。#开源 #代码模型 #AI
原文标题:字节Seed首次开源代码模型,拿下同规模多个SOTA,提出用小模型管理数据范式
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到Seed-Coder的评分模型以DeepSeek-V2-Chat为基础,你觉得使用LLM来评估代码质量是否靠谱?有没有什么潜在的风险?
3、字节Seed开源Seed-Coder,以及其他的视频生成模型、推理模型、智能体等,你觉得这种开源策略对于整个AI社区会带来什么影响?
原文内容

字节Seed首次开源代码模型!
Seed-Coder,8B规模,超越Qwen3,拿下多个SOTA。
它证明“只需极少人工参与,LLM就能自行管理代码训练数据”。
通过自身生成和筛选高质量训练数据,可大幅提升模型代码生成能力。
这可以被视为对DeepSeek-R1模型自我生成和筛选训练数据策略的扩展。
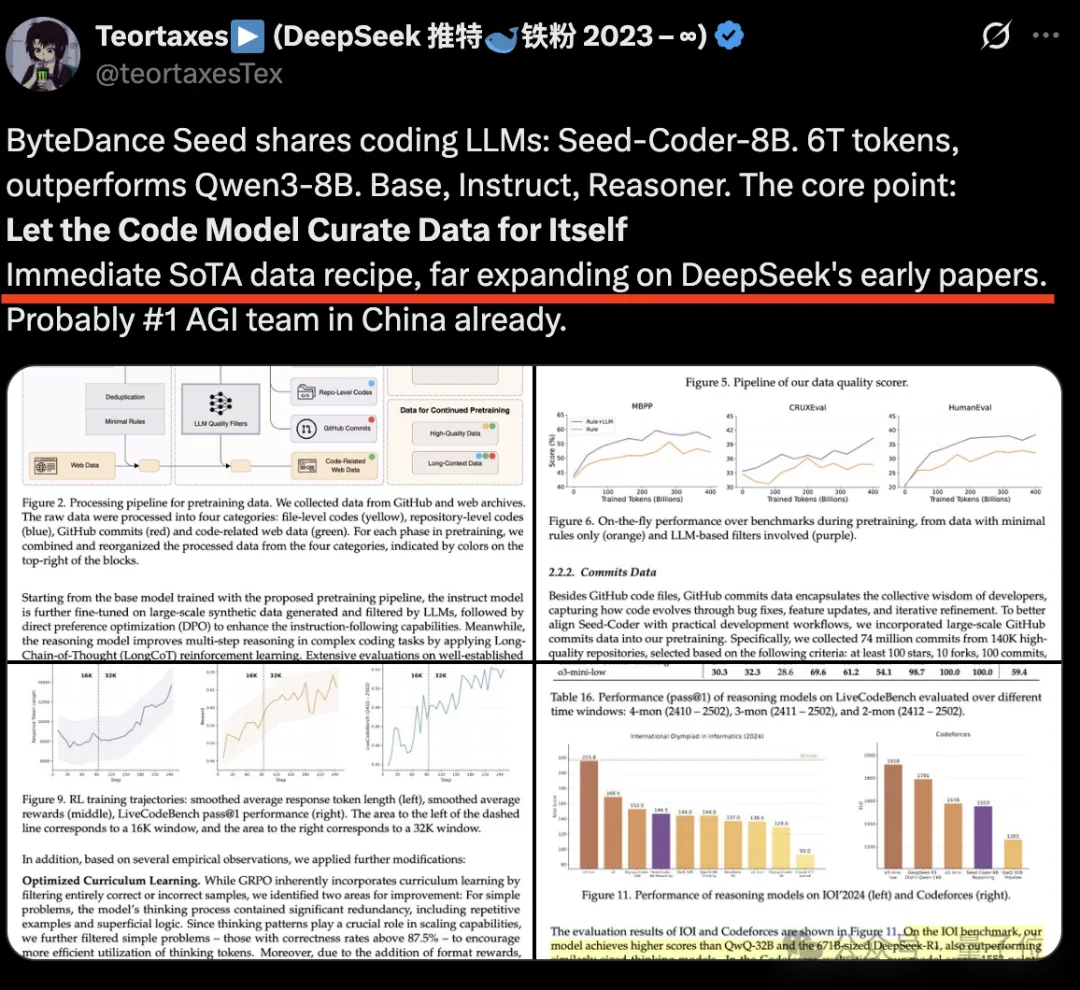
一共包含三个版本:
-
Base
-
Instruct
-
Reasoning
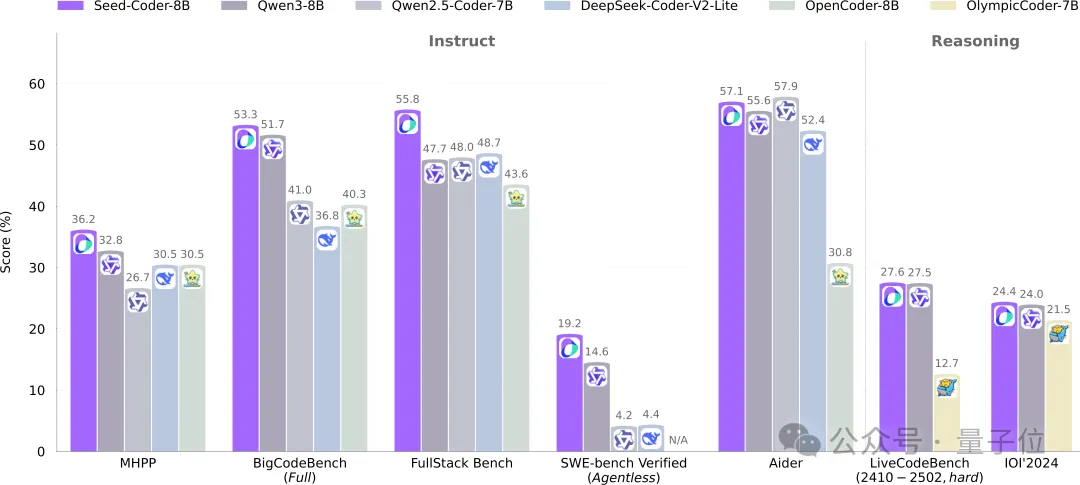
其中,Instruct在编程方面表现出色,拿下两个测试基准SOTA。
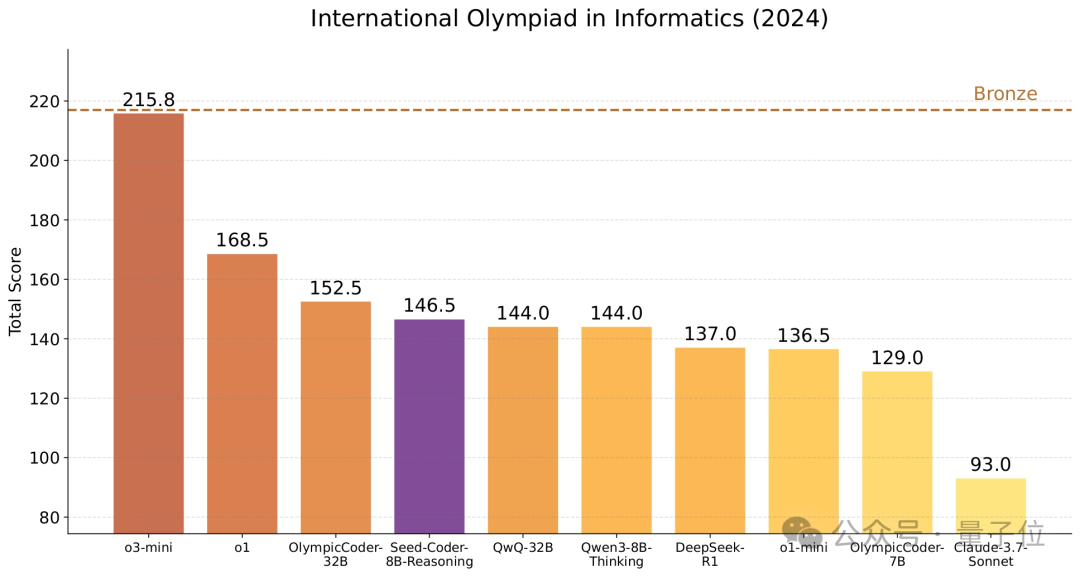
推理版本,在IOI 2024上超越了QwQ-32B和DeepSeek-R1。
用模型管理训练数据
Seed-Coder的前身是doubao-coder,采用Llama 3结构,参数量为8.2B,6层,隐藏层大小为4096,采用分组查询注意力(GQA)机制。
最关键的工作是数据的处理,Seed团队提出了一种“模型中心”的数据处理方式,使用模型来策划数据。
具体来说,模型会从GitHub和网络档案爬取原始代码数据,经过几个处理步骤后输出最终的预训练数据。
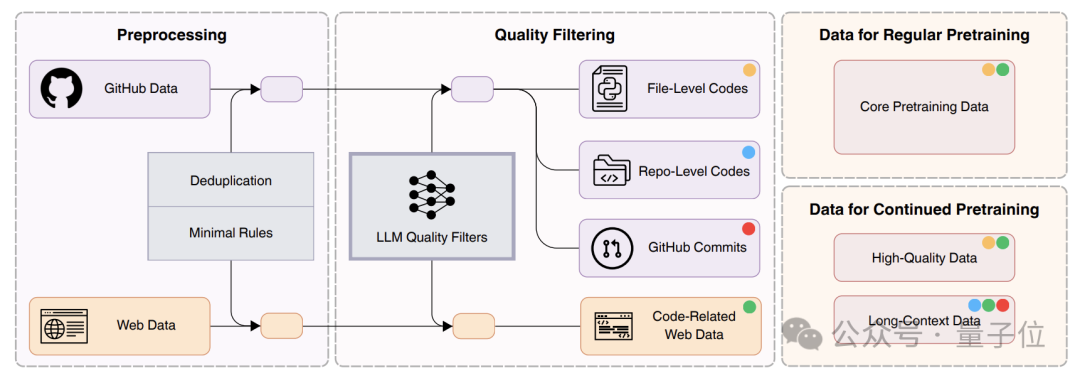
Seed-Coder的过滤数据分为四个类别:
-
文件级代码:来自GitHub的单个代码文件,经过处理后保留了高质量的代码内容。
-
仓库级代码:基于仓库结构的代码文件,保留了项目结构信息,使模型能学习到代码间的关系。
-
Commit数据:GitHub提交的快照,包括提交信息、仓库元数据、相关文件和代码补丁,包括来自14万个高质量仓库的7400万次提交;
-
代码相关网络数据:从网络存档中提取的包含代码块或高度代码相关的文档。
先看看代码的处理,在预处理阶段,系统在仓库和文件两个层级实施去重,SHA256哈希进行精确去重,并通过MinHash算法进行近似去重。
这种双层策略产生了两种变体的代码语料库——文件级变体用于短上下文窗口训练,仓库级变体保留了项目结构以支持更连贯的长上下文学习。
随后,系统使用Tree-sitter等语法解析器检查剩余文件,丢弃那些包含语法错误的文件。这个预处理阶段总共减少了大约98%的原始数据量。
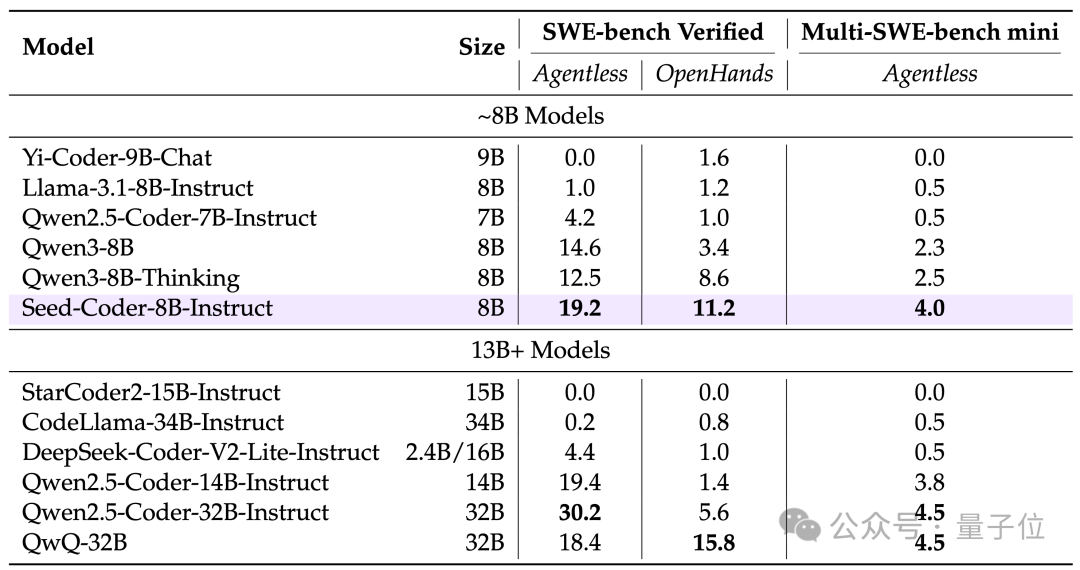
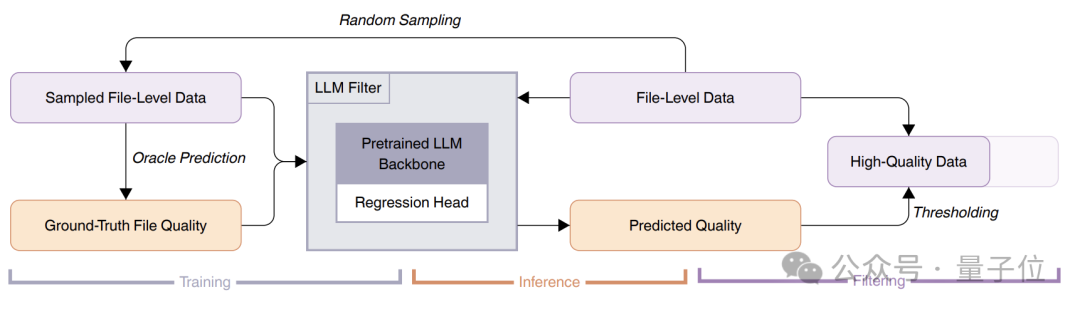
在质量过滤阶段,Seed-Coder使用一个经过22万+份代码文档特殊训练的评分模型来过滤低质量代码文件。
评分模型以DeepSeek-V2-Chat为基础,评价指标包含四个关键方面:
-
可读性:包含合理数量的注释,遵循一致的命名规范,并遵循通用的格式和结构规范;
-
模块性:结构合理,避免功能过于复杂或冗长,通过模块化实现逻辑功能清晰分离;
-
清晰度:减少冗余,(如过多的函数调用、大段注释代码或调试打印语句),每个代码块的意图表达清晰;
-
可重用性:没有语法和逻辑错误、避免过多硬编码数据、设计便于与其他项目集成、功能完整且有意义。
评分模型被要求给出一个从0到10的总体评分,并提供详细解释,之后将分数重新缩放到[0,1]范围,并使用1.3B参数的预训练Llama 2模型,通过回归头进行一个epoch的微调作为质量评分器。
最终基于这种评分方法,Seed团队过滤掉了得分最低的约10%文件,得到了支持89种编程语言、包含约1万亿个独特token的语料库。
再来是Commit的部分,Seed-Coder从14万个高质量GitHub仓库中收集了7400万个提交记录。这些仓库的筛选标准包括:至少100颗星、10个fork、100次提交和100天的维护活动。
每个提交记录都包含丰富的元数据,如提交消息、代码补丁、合并状态以及提交前的代码快照。
为了在预训练中有效利用这些数据,Seed-Coder将每个提交样本格式化为一个代码变更预测任务。给定一个提交消息及其相关上下文,模型需要预测被修改的文件路径以及相应的代码变更。
在进行去重和预处理后,Seed-Coder获得了约1000亿token的提交数据语料库用于预训练。
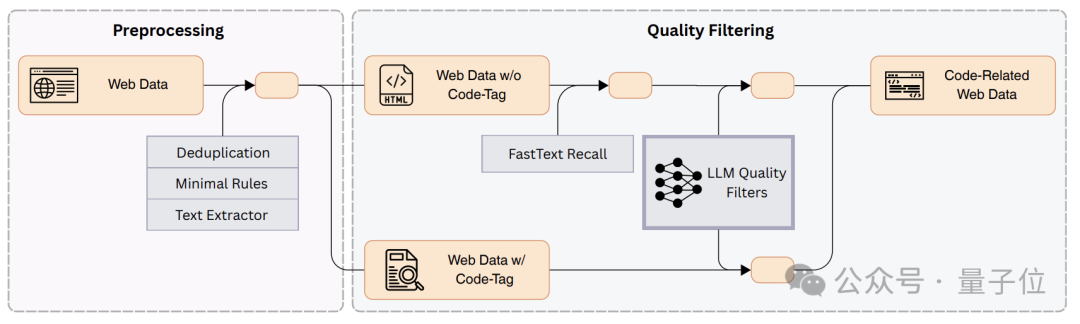
对于从网络获取的数据,Seed-Coder也提出了一个专门的提取框架。
在预处理阶段,框架对大规模网络档案进行高效预处理,并识别出两类原始数据:
-
第一类是HTML中带有明确代码标签(如
…)的网页,这些可以通过标准规则直接提取; -
第二类是没有明确代码标签但可能包含代码或相关知识的数据,这类数据由于其体量和复杂性带来了提取挑战。
与GitHub数据处理类似,研究团队实施了精确和近似去重技术,并开发了启发式规则来在预处理阶段剔除明显的低质量文档(例如少于10个词的文档)。
在质量过滤阶段,框架采用两个互补策略来确保数据质量:首先是识别代码相关性,然后评估已识别内容的内在质量。
在代码相关性识别步骤中,研究团队首先从Common Crawl数据中抽取了1000万个网页样本,将具有代码特征的页面标记出来,建立评估数据集。
这个数据集中70%用作训练集,用于训练fastText模型来自动识别代码相关内容,剩余30%作为验证集来评估模型效果。
在质量评估步骤中,系统使用LLM对已识别的代码相关内容进行评分,评分标准采用0-10分制,评估内容的规范性、完整性和价值。
但在实际评估过程中,研究者发现不同类型网站的得分出现了系统性偏差:
文档网站、技术博客等由于格式规范、结构清晰,普遍获得较高分数;而技术论坛、问答平台等网站,虽然往往包含有价值的技术讨论和解决方案,但因其非正式的格式而得分较低。
为了解决这种评分偏差,研究团队对评分系统进行了优化——首先将网站按其内容形式和功能进行分类,然后为每类网站制定专门的评分标准和筛选阈值。
通过这套经过优化的双重过滤机制,系统最终构建了一个约1.2万亿tokens的网络数据语料库。
基于前面的四个数据类别,Seed-Coder的预训练分为了两个阶段。
其中,第一个阶段为常规预训练,使用的是文件级代码和代码相关网络数据,目的是构建模型的基础能力。
第二个阶段是持续预训练,使用所有四个类别的数据,并额外引入了高质量数据集和长上下文数据集,以增强性能并进行对齐,同时刺激模型理解长上下文数据的能力。
除了常规的next-token预测目标外,Seed-Coder还采用了Fill-in-the-Middle(FIM)和Suffix-Prefix-Middle(SPM)训练,分别增强上下文感知完成和中间内容能力。
基于基础模型,Seed团队还开发了Seed-Coder的两个特殊变体——
-
指令模型(-Instruct):目的是增强模型的指令遵循能力,其训练分为监督微调(SFT)第二阶段和直接偏好优化(DPO)两个阶段;
-
推理模型(-Reasoning):目的是提升模型在复杂编程任务中的多步推理能力,采用长链条思维(LongCoT)强化学习训练。首先使用从编程竞赛问题和高质量模型生成的解决方案进行预热训练,然后通过GRPO框架实施强化学习训练。
这两个变体的设立,进一步扩展了Seed-Coder的实用性。
字节Seed最近更开放了
除了开源Seed-Coder外,字节Seed近期多个动作也都聚焦在了降门槛、开源开放方面。
比如在基础模型方面,发布了视频生成和推理模型。
视频生成模型Seaweed,70亿参数原生支持1280x720分辨率、任意宽高比和时长视频生成,效果超越140亿参数模型。
它强调了成本方面的优势,使用665000 H100 GPU小时完成训练,中小团队可部署,仅需40GB显存单GPU就可生成分辨率达1280x720的视频。
深度思考模型Seed-Thinking-v1.5,更轻量级、更少激活参数,在数学、代码等推理任务重超越DeepSeek-R1。
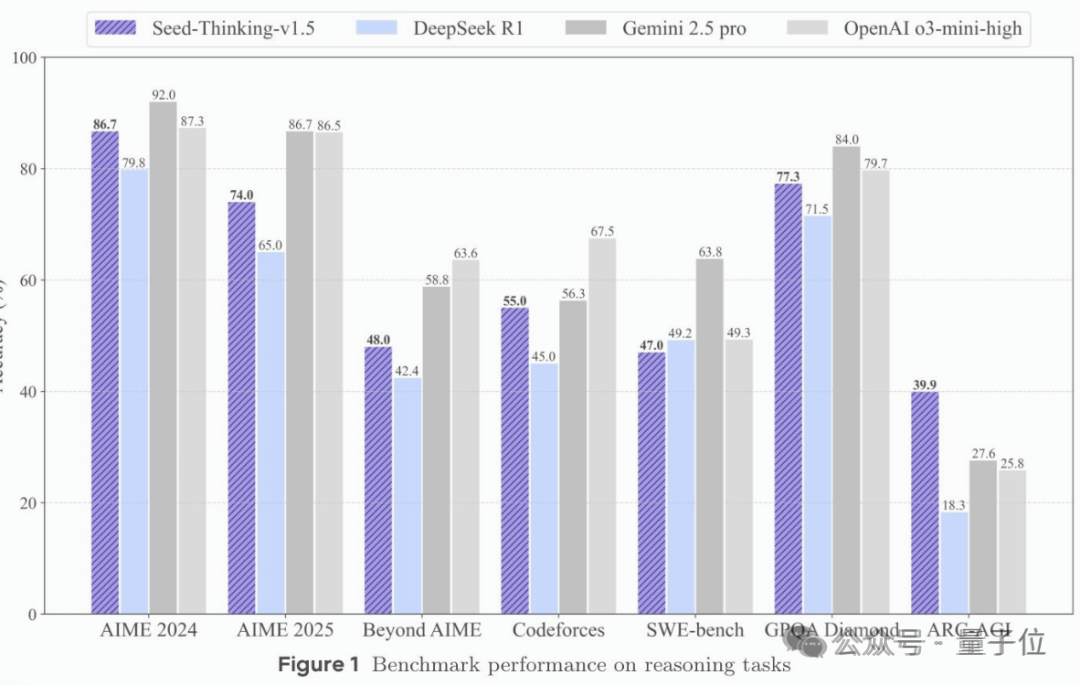
同时团队公开技术报告,介绍其中秘诀,通过数据、RL算法和RL基础设施三方面提升推理表现。
在智能体方面,与清华联手推出了电脑操作智能体UI-TARS,超越GPT-4o等,且免费商用。
它在Qwen-VL基础上而来,能一步步自动完成跨任务的复杂操作,并兼容各种系统。目前GitHub上星标已超过5.8k。
此外还推出了Multi-SWE-bench:用于问题解决的多语言基准。它跨越7种编程语言,包含1632个高质量实例。
……
与此同时,字节Seed内部也在不断调整。消息称,LLM 之下的3个团队,Pre-train(预训练)、Post-train(后训练) 和Horizon如今转为直接向Seed负责人吴永辉汇报。字节AI Lab中探索机器人&具身智能、AI for Science和AI安全可解释性的三个方向,也已并入Seed。
今年年初,字节正式设立代号为“Seed Edge”的研究项目,核心目标是做比预训练和大模型迭代更长期、更基础的AGI前沿研究,项目成员拥有宽松的研究环境、独立计算资源,并实行更长期的考核方式。拟定五大研究方向也完全面向下一代AI研究、原始性创新,或者是范式上的更迭。
而透过字节的动向,如今AI圈子的新风向也更明朗了。
开源、开放、原始性创新、AI普惠……
言而总之,还得是感谢DeepSeek了?(doge)
项目地址:
https://bytedance-seed-coder.github.io/
参考链接:
https://seed.bytedance.com/zh/
