新加坡国立大学提出Manual2Skill框架,利用视觉语言模型解析家具装配说明书,助力机器人自主完成复杂装配任务,为机器人学习复杂操作技能提供新途径。
原文标题:RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Manual2Skill框架目前在“最终部件插入”环节仍需人工干预,未来如何通过技术手段实现这一环节的自动化?
3、Manual2Skill框架在零样本扩展中表现出色,但主要是在相似的装配任务上。如果面对完全不同类型的任务,例如烹饪或医疗手术,该框架是否仍然适用?需要进行哪些改进?
原文内容

本文共同第一作者为新加坡国立大学博士生铁宸睿和多伦多大学研究助理/本科生孙圣翔。合作者为朱锦轩、刘益伟、郭京翔、胡越、陈浩楠、陈俊廷、吴睿海。通讯作者为新加坡国立大学计算机学院助理教授邵林,研究方向为机器人和人工智能。
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。
尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人类演示数据和训练样本的稀缺性。
为解决这一问题,研究团队提出 Manual2Skill,一种基于 VLMs 的创新框架,使机器人能通过高级视觉说明书自主理解并执行家具装配任务,模仿人类学习装配的过程。该方法弥合了抽象指令与物理执行之间的鸿沟,显著提升了机器人在真实操作场景中的实用性。
目前,该论文已被机器人领域顶级会议 Robotics: Science and Systems XXI(RSS 2025)接收。

-
论文标题:Manual2Skill: Learning to Read Manuals and Acquire Robotic Skills for Furniture Assembly Using Vision-Language Models
-
论文链接:https://arxiv.org/abs/2502.10090
-
项目主页:https://owensun2004.github.io/Furniture-Assembly-Web/
研究背景
家具装配是一项复杂的长时程任务,要求机器人:(A) 理解所有零件的拼接关系和顺序;(B) 估计每一步拼接时部件的位姿;(C) 生成物理可行的动作以完成部件组装。
尽管许多计算机视觉方法通过几何或语义技术在部件位姿预测(B)方面取得显著成果,但它们大多忽视了同样关键的拼接顺序理解(A)和动作生成(C)环节 [1, 2]。
现有的端到端机器人装配系统通常依赖模仿学习或强化学习。虽然在某些场景下有效,但这些方法需要大规模数据集和大量计算资源,难以推广至真实环境中的通用长时程操作任务 [3, 4]。
近年来,视觉语言模型(VLMs)在高层规划、环境理解甚至直接机器人控制方面展现出潜力。部分研究尝试整合这些能力用于机器人装配,但多局限于简单几何物体且在真实装配场景中鲁棒性不足 [5]。
关键问题在于,现有 VLM 方法(乃至多数当前方法)缺乏对结构化外部指导(如人工设计的说明书)的利用。这种缺失限制了它们在依赖抽象符号指令的复杂装配任务中的表现。
相比之下,人类能够从抽象的说明书中提取信息并学习操作技能,这揭示了机器人能力的一个重要缺口:从抽象的、为人类设计的指导信息中学习物体操作技能。
凭借强大的视觉与语言推理能力,VLMs 为弥合这一缺口提供了独特机遇。通过挖掘说明书中的结构化知识,VLMs 可使机器人更高效可靠地完成复杂多步骤装配任务。
Manual2Skill:
基于 VLM 的说明书引导式机器人装配框架
为解决复杂长时程装配的局限性,研究团队开发了 Manual2Skill —— 一种创新框架,利用 VLMs 将基于说明书的视觉指令转化为机器人装配技能。
Manual2Skill 包含三个核心阶段:
-
层级化装配图生成:通过 VLM 解析说明书图像,构建描述家具部件结构关系的层级化装配图。
-
分步骤位姿估计:预测每个装配步骤中涉及的家具部件的精确 6D 位姿。
-
动作生成与执行:将位姿信息转化为可执行的机器人轨迹。
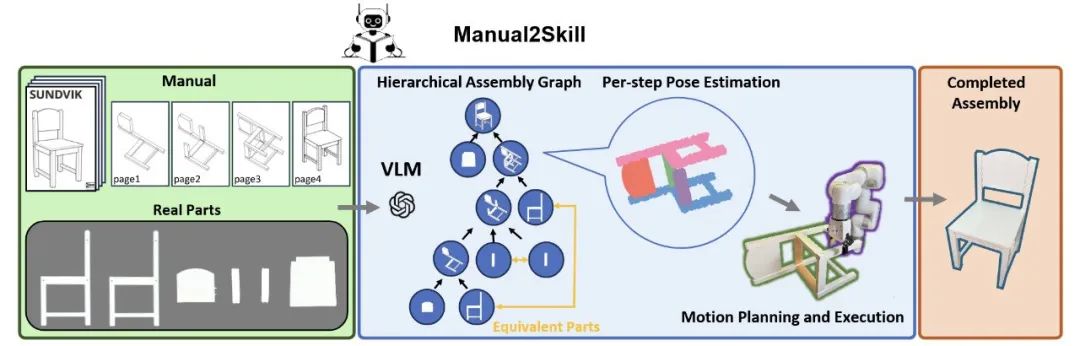
图 1:Manual2Skill 框架
该框架解决了现有机器人装配方法的两大核心限制:
-
通过将人类理解的抽象示意图转化为结构化装配层级图与部件位姿,使机器人能从说明书提取可操作信息,避免了对大规模高质量演示数据集的依赖。
-
将装配层级图作为结构化装配信息的核心表征,为真实装配任务提供通用解决方案,适用于所有多步骤复杂装配问题。
阶段 I: 层级化装配图生成
Manual2Skill 的首阶段将人类可理解的说明书转化为机器人可执行的任务规划。通过视觉语言模型(GPT-4o)对说明书示意图和预装配场景图像进行联合推理,生成编码家具部件与子组件结构关系的层级化装配图。
在此图中:
-
叶节点代表原子部件。
-
非叶节点表示通过连接部件/子组件形成的复合结构。
-
从叶节点向根节点遍历可获得完整的逐步装配流程。
为构建该图,Manual2Skill 通过整合多模态输入,特别是多张图像的视觉信息与文本指令组成的多轮提示序列,完成两个关键子阶段:
-
跨域视觉理解:通过视觉提示技术(如 Set-Of-Marks 和 GroundingDINO)和几何视觉推理,GPT-4o 将预装配场景图片中的物理部件与其说明书图示进行语义关联,从而解析每个部件的作用与位置。
-
结构化信息提取:基于已识别的部件信息,使用链式思维(Chain-of-Thought)、由简至繁(Least–To–Most)和上下文学习(In-Context Learning)等提示技术,判断说明书中每个步骤涉及的特定部件。
该结构化图表征为下游位姿估计与运动规划奠定基础,确保复杂装配任务的精准顺序执行。
阶段 II: 分步骤装配位姿估计
在层级化装配图确定部件组合与装配顺序后,本阶段预测每个装配步骤中所有部件的 6D 位姿,实现部件间的精确物理对齐。
与过往方法通常一次预测整个装配过程中所有零件的位姿不同,这里我们对每个装配步骤,预测这一步中涉及到的所有部件/子组件的位姿,这一设置既更贴合真实世界中的拼装过程,也能使模型避免单次输入部件数量过多引起的性能下降。
同时我们还发现,尽管家具的形态有很大差别,但其基本部件的连接方式(比如板和棍的连接)较为固定,这种分步预测的方法能使模型更好地学习到这种基本连接方式,从而对测试集的物体实现更高的预测精度。
为实现此目标,跨模态位姿估计模型对说明书图像与家具部件 3D 点云进行联合推理。模型架构包含四个核心组件:
-
图像编码器(E_I):从说明书图像提取语义特征,捕获部件关系与朝向的视觉线索。
-
点云编码器(E_P):编码各部件的点云数据。
-
跨模态融合(E_G):使用图神经网络(GNN)整合图像与点云特征。
-
位姿回归器(R):从融合特征预测各部件的 SE(3) 位姿。
给定说明书图像 I_i 和涉及部件的点云集合![]() ,处理流程如下:
,处理流程如下:
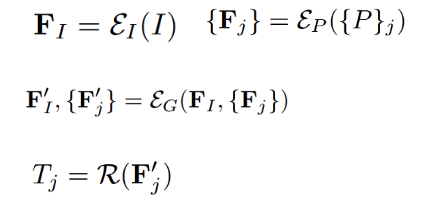
为确保预测的鲁棒性与准确性,模型采用复合损失函数:
-
SE(3) 变换误差(旋转测地距离 + 平移 MSE)
-
点云对齐损失(Chamfer 距离)
-
可互换部件的置换不变损失(评估所有有效排列并选择最小损失方案)
该设计使模型能够处理可变数量的输入部件,适应视觉相似/对称部件,以及泛化到训练集上未见过的新物体。
阶段 III: 机器人装配动作生成与执行
最终阶段将预测位姿转化为真实世界的机器人动作,实现装配计划的自主执行。我们在这一阶段使用基于启发式的抓取策略和稳健的运动规划算法,让机械臂抓取对应部件,并将其放置在预测位姿。
-
抓取规划与部件操控
我们使用 FoundationPose 与 SAM 估计场景中所有部件的初始位姿。根据部件几何特征应用启发式抓取策略:
-
棒状部件:沿主轴在质心处抓取。
-
扁平薄片部件:使用夹具/平台固定后沿边界稳定抓取。
-
运动规划与执行
抓取后,机器人使用 RRT-Connect(基于采样的运动规划器)计算从当前位姿到目标位姿的无碰撞轨迹。所有其他物体被视为避障点云。通过锚定位姿在轨迹中段重新评估抓取部件位置,确保精确跟踪与控制。
-
装配插入
最终部件插入是涉及精确对齐与力反馈的接触密集型任务。由于闭环插入的复杂性,目前由人类专家完成。我们会在未来的研究中,整合触觉与力传感器实现自主插入。
实验结果与分析
实验在仿真与真实环境中对多款宜家家具进行,验证 Manual2Skill 的鲁棒性与有效性。
-
层级化装配图生成
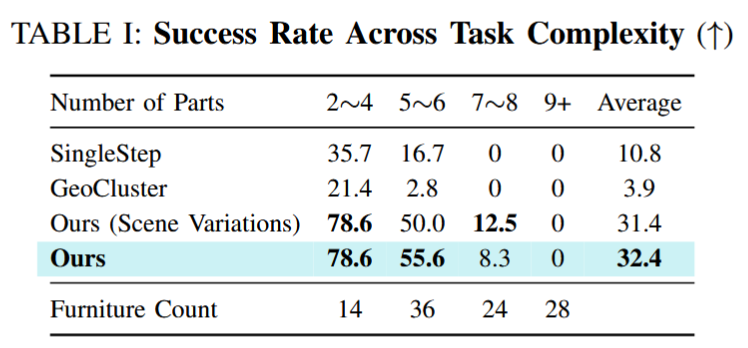
图 2:层级化装配图生成结果
我们在 102 本真实宜家家具说明书上测试了我们提出的层级化装配图生成方法的表现,可以看出,对于简单和中等复杂程度的家具(部件数 ≤ 6),我们的方法能比较准确地生成装配图,同时在所有复杂程度的家具上,我们的方法表现均显著优于基线方法。尽管所有方法在复杂家具上表现受限,但随着 VLM 性能的提升,我们方法的表现会随之提升。
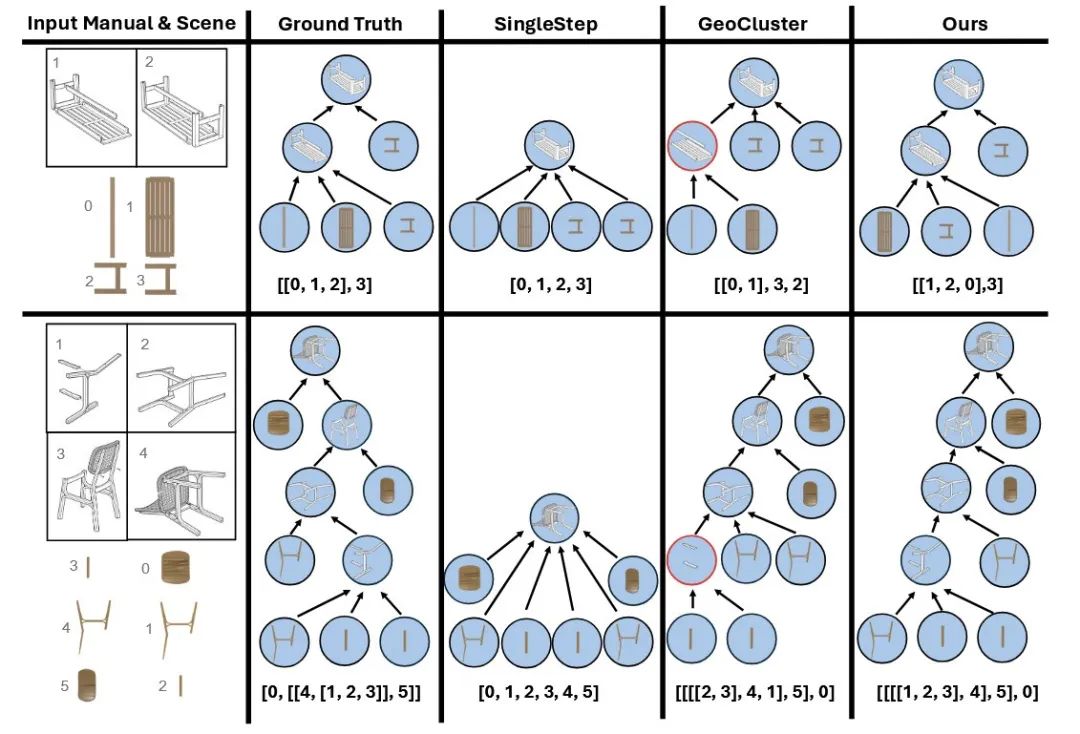
图 3:层次化装配图可视化
-
位姿估计
我们从 PartNet 数据集中选取了三类物体(椅子、台灯、桌子),每类物体各 100 个,并且在 Blender 中渲染出这些物体部件组合的示意图作为说明书图片。
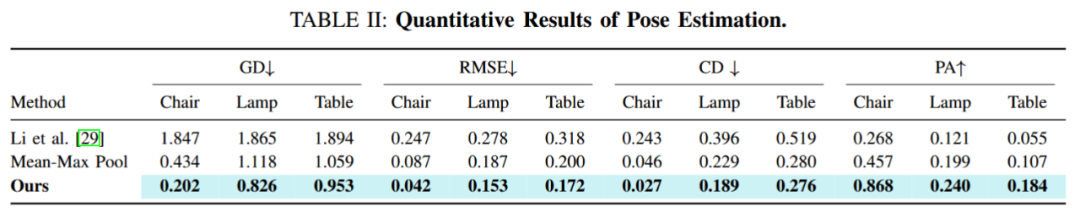
图 4:位姿估计实验结果
实验结果表明,凭借多模态特征融合与 GNN 空间关系建模,本方法在全部四个评价指标上超越基线方法。
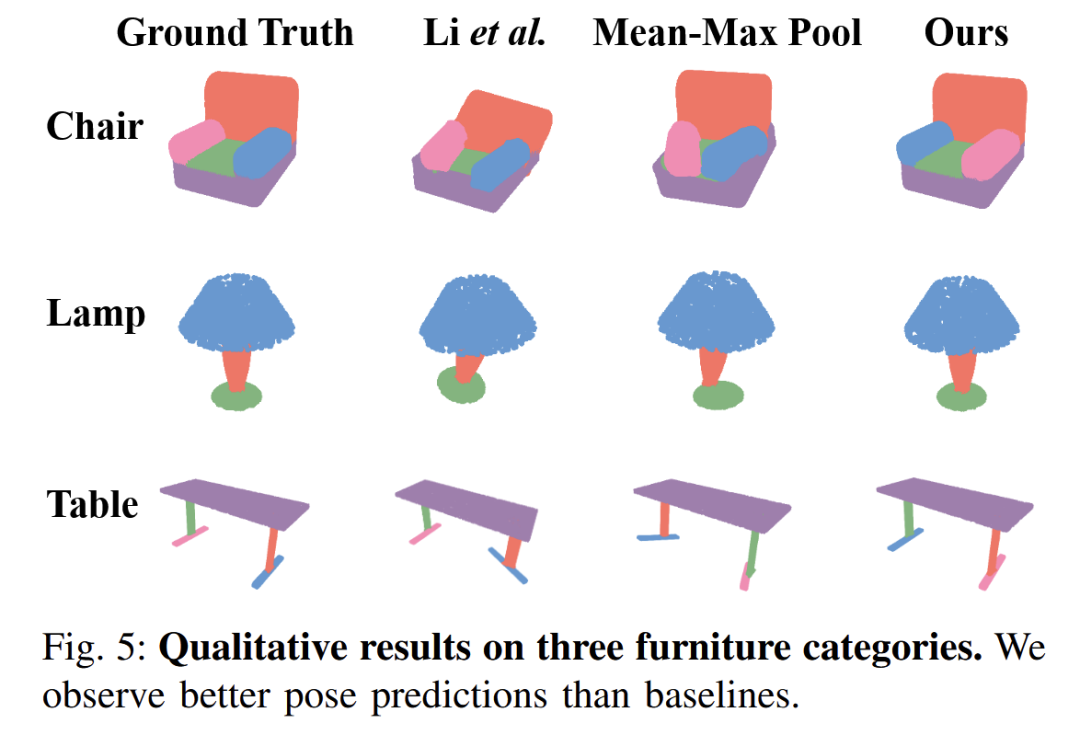
图 5:位姿估计可视化
-
仿真测试
在 50 件简单至中等难度家具的仿真测试中,Manual2Skill 达成 58% 成功率,显著超越现有启发式方法,验证了层级化装配图、位姿估计与运动规划结合的有效性。
-
实物实验
我们在四款真实宜家家具(Flisat 凳、Variera 架、Sundvik 椅、Knagglig 箱)上测试了我们整套框架,体现了我们的框架在真实机器人装配任务中的可行性和出色表现。
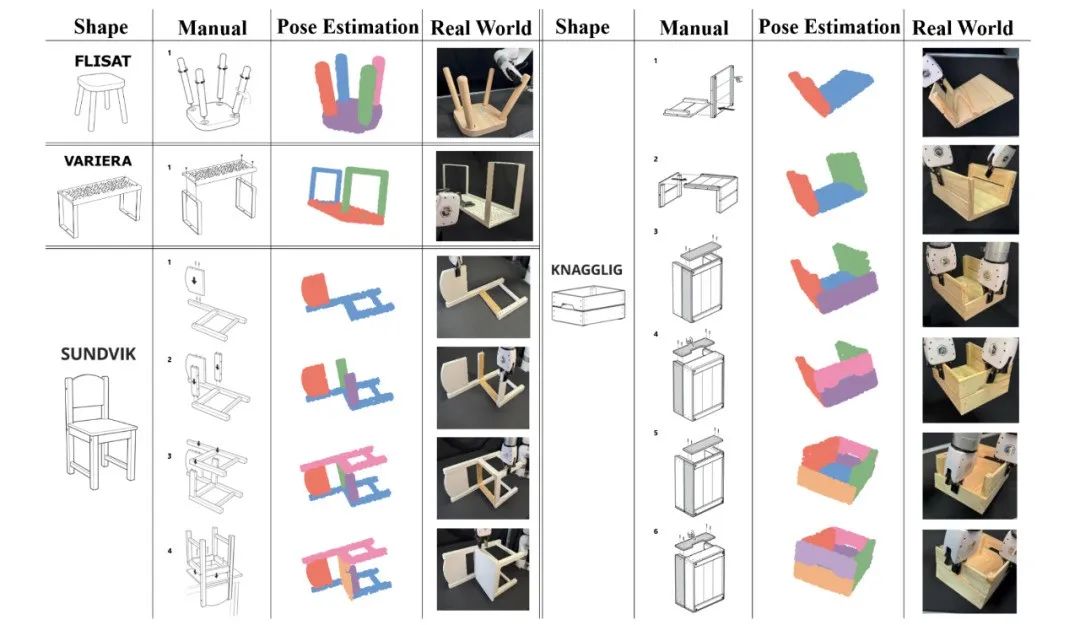
图 6:真实世界家具装配过程可视化
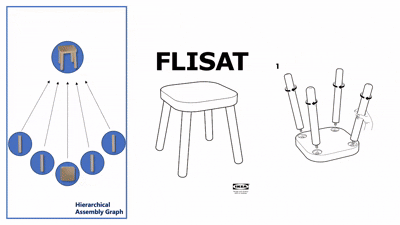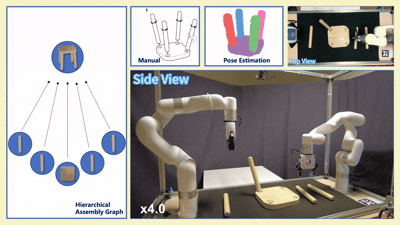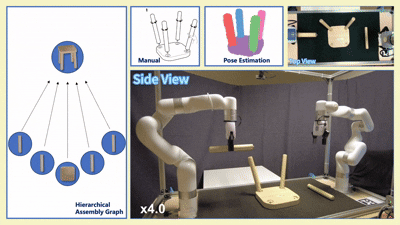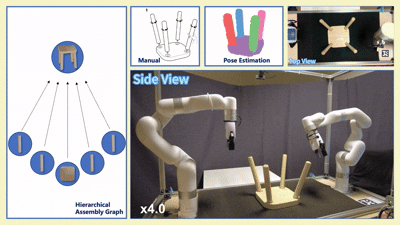
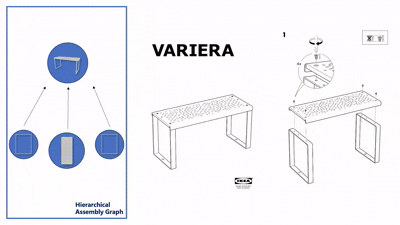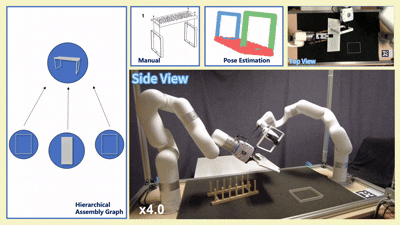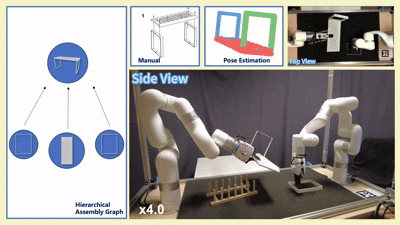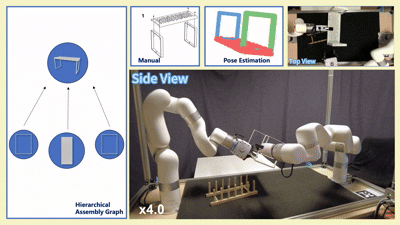
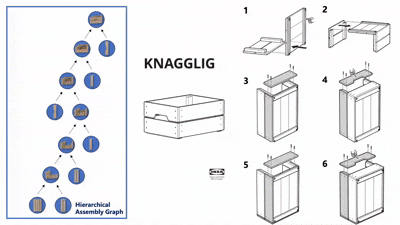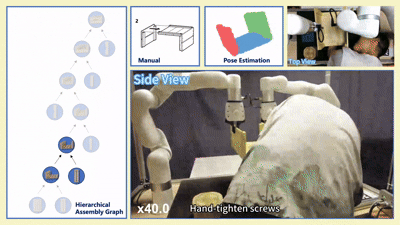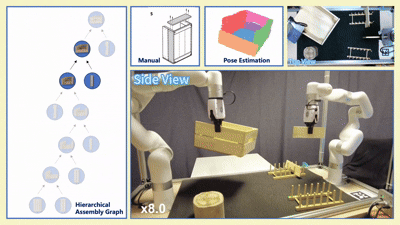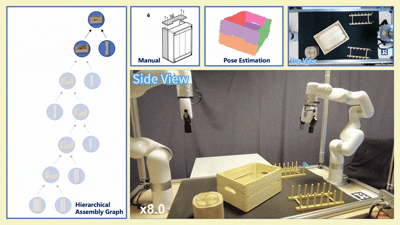
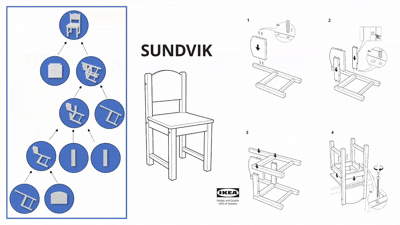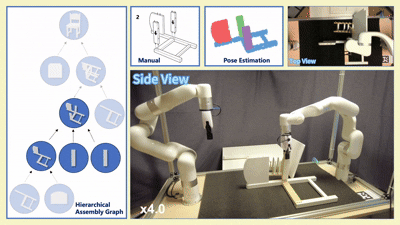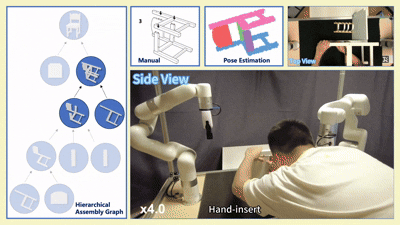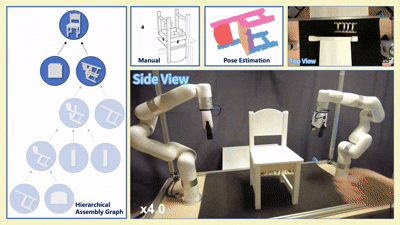
-
零样本扩展
本方法可零样本推广至轮轴、玩具飞机甚至机械臂等手册引导式装配任务,成功率 100%,彰显 VLM-based 方案相比其他方法的泛化优势。
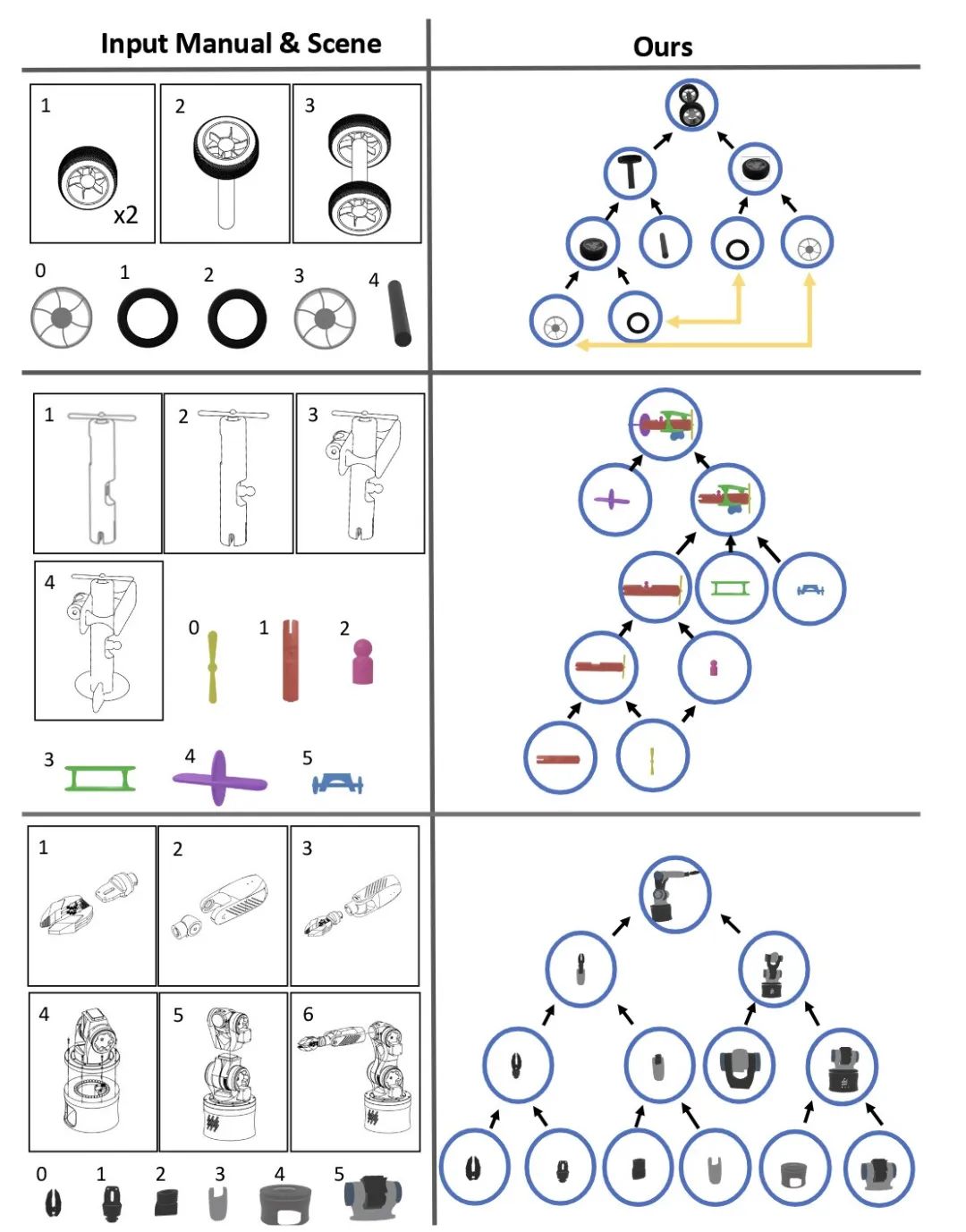
图 7:零样本扩展可视化
结论与展望
本文提出 Manual2Skill,一种开创性框架,通过 VLMs 使机器人能解析人工设计的视觉说明书并自主执行复杂家具装配任务。通过引入层级化图式指令解析与鲁棒位姿估计,Manual2Skill 有效弥合了抽象说明书与物理执行之间的鸿沟。
Manual2Skill 提出了一种新的机器人学习范式,机器人可以从为人类设计的说明书中学习复杂长程的操作技能,相比起收集大量人工示范数据做模仿学习,显著降低了复杂操作技能获取的成本和复杂度。同时,说明书通过抽象图表和符号表示传达操作知识,这种抽象化的表达方式捕获了操作过程的底层结构和核心逻辑,而非仅仅记录表面的动作序列。这种深层次的理解使得获得的技能能够在不同的物体配置、环境条件和机器人实体间实现有效泛化。
参考文献
[1] Yun-Chun Chen, Haoda Li, Dylan Turpin, Alec Jacobson, and Animesh Garg. 「Neural shape mating: Self-supervised object assembly with adversarial shape priors」. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12724–12733, 2022.
[2] Benjamin Jones, Dalton Hildreth, Duowen Chen, Ilya Baran, Vladimir G Kim, and Adriana Schulz. 「Automate: A dataset and learning approach for automatic mating of cad assemblies」. ACM Transactions on Graphics (TOG), 40(6):1–18, 2021.
[3] Mingxin Yu, Lin Shao, Zhehuan Chen, Tianhao Wu, Qingnan Fan, Kaichun Mo, and Hao Dong. 「Roboassembly: Learning generalizable furniture assembly policy in a novel multi-robot contact-rich simulation environment」. arXiv preprint arXiv:2112.10143, 2021.
[4] Zuyuan Zhu and Huosheng Hu. 「Robot learning from demonstration in robotic assembly: A survey」. Robotics, 7(2):17, 2018.
[5] Andrew Goldberg, Kavish Kondap, Tianshuang Qiu, Zehan Ma, Letian Fu, Justin Kerr, Huang Huang, Kaiyuan Chen, Kuan Fang, and Ken Goldberg. 「Blox-net: Generative design-for-robot-assembly using vlm supervision, physics simulation, and a robot with reset」. arXiv preprint arXiv:2409.17126, 2024.

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com