DeepSeek发布R1推理模型更新(0528),采用MIT许可证,参数量达6850亿,实测性能提升显著,尤其在代码能力方面表现突出。网友期待R2。
原文标题:DeepSeek-R1今天一次「小更新」,颠覆了大模型格局,网友:尽快放R2
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 DeepSeek R1-0528 在解决简单问题时存在“过度思考”的现象,你认为这是所有大模型的通病吗?如果是,有哪些可能的解决方案?
3、DeepSeek R1 的快速迭代更新,是否预示着大模型领域的技术进步速度正在加快?对于开发者和普通用户来说,这种快速变化意味着什么?
原文内容
编辑:泽南、Panda
超出所有人的期待。
千呼万唤始出来,DeepSeek 迎来了推理模型更新。

昨晚,DeepSeek 官方宣布其 R1 推理模型升级到了最新版本(0528),并在今天凌晨公开了模型及权重。
HuggingFace 链接:https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
模型文件上传时间是凌晨 1 点,不知 DeepSeek 工程师们是不是加班到了最后一刻。也有网友表示,这回又在端午节假期前发新模型,简直比放假通知还靠谱。
这次更新的升级版 R1 参数量高达 6850 亿,体量巨大,虽然开源了出来,但大多数人只能围观。如果「满血版」不进行蒸馏,是肯定无法在消费级硬件上本地运行的。
不过这种不说话直接放链接的态度还是引来了网友们的普遍欢迎。
根据 DeepSeek 的小范围通知,更新后的 R1 版本采用 MIT 许可证,这意味着它可以用于商业用途,从版本号看来这是一个「小」升级,不过人们大量实测后发现,新版大模型的性能提升颇为明显。
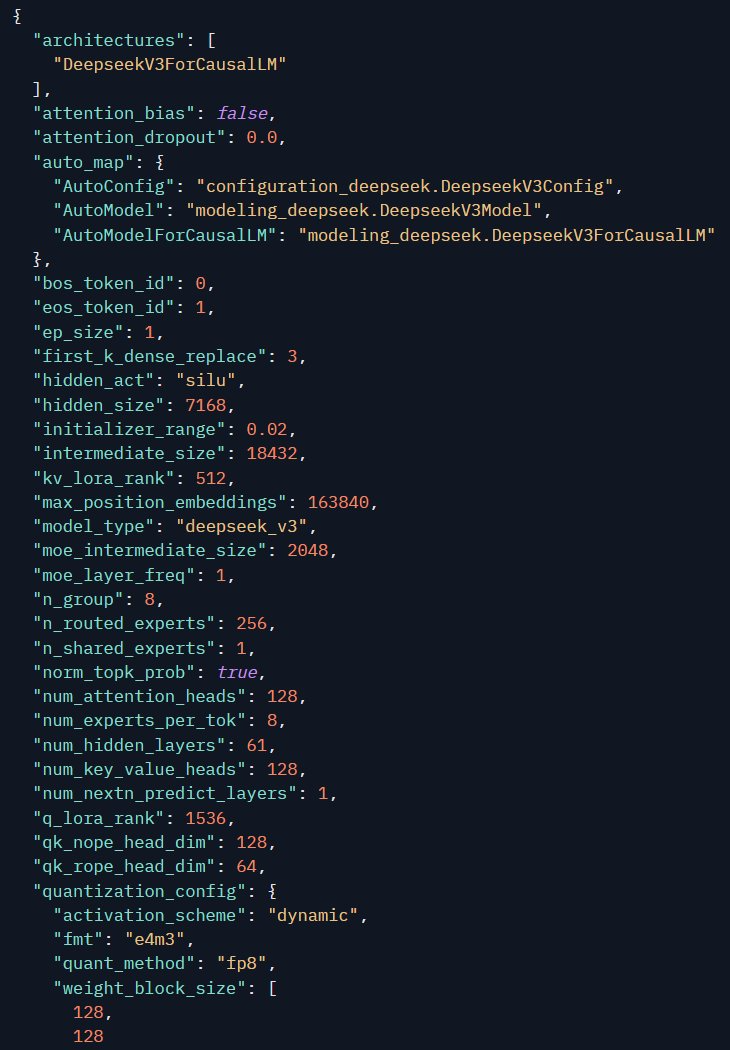
我们也能在新版 DeepSeek-R1 模型的配置文件中看到更多但并不出人意料的信息,包括采用了 DeepSeek-V3 作为基础模型以及 MoE、隐藏层大小、量化等配置。
我们现在已经可以在 DeepSeek 的网页端和 App 上直接用上这个最新版本的大模型。
有网友总结表示,新的 DeepSeek-R1-0528 可以进行更加深度的推理,输出的文本更加自然,结构更有层次感,它展现出了独特的推理风格,不仅速度很快,而且进行了充分的思考。与上周发布的 Claude4 类似,现在的 DeepSeek 也可以进行长时间的思考了,据说能持续 30-60 分钟。
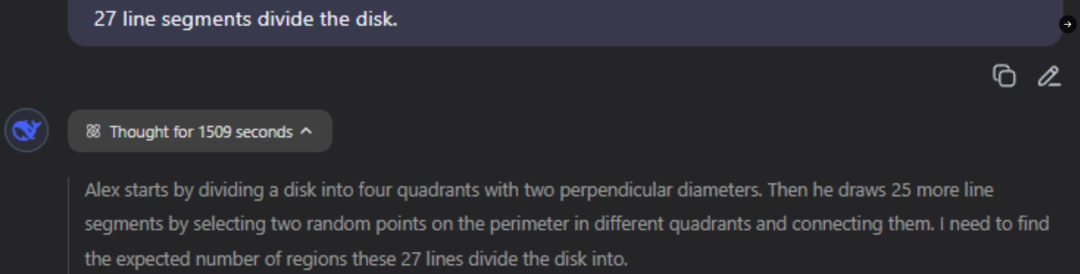
已经有一些网友实测时遇到了 DeepSeek 的长考,这 deep research 可够深度的:
基准评分,成绩大幅提升
DeepSeek R1 发布以来,大模型领域的格局已经发生了变化。原版 R1 的成绩如今已不再领先,R1-0528 的出现修正了结果。
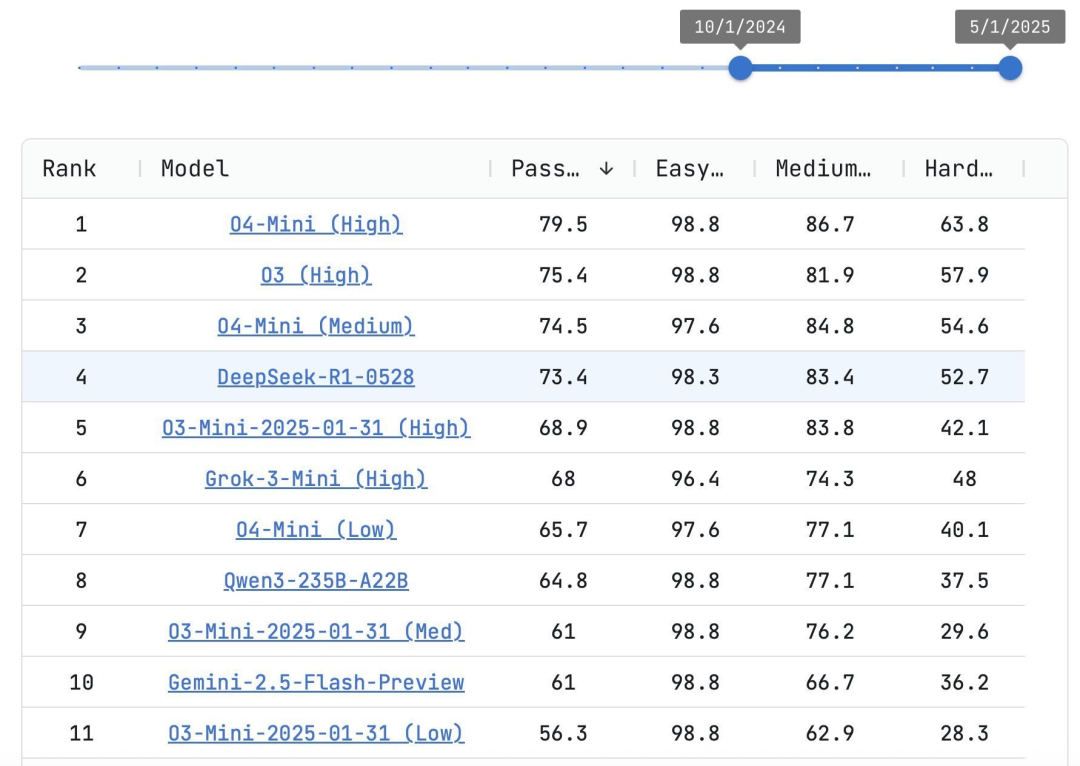
R1-0528 模型的第一个 Benchmark 成绩是 LiveCodeBench,它超越了 O3-Mini,几乎与 O3(High)的评分相当,在编程任务上相比上个版本有了显著的提升。
要知道 DeepSeek 模型是完全开源的,App 目前为止也完全免费,这可以说是开源的胜利。
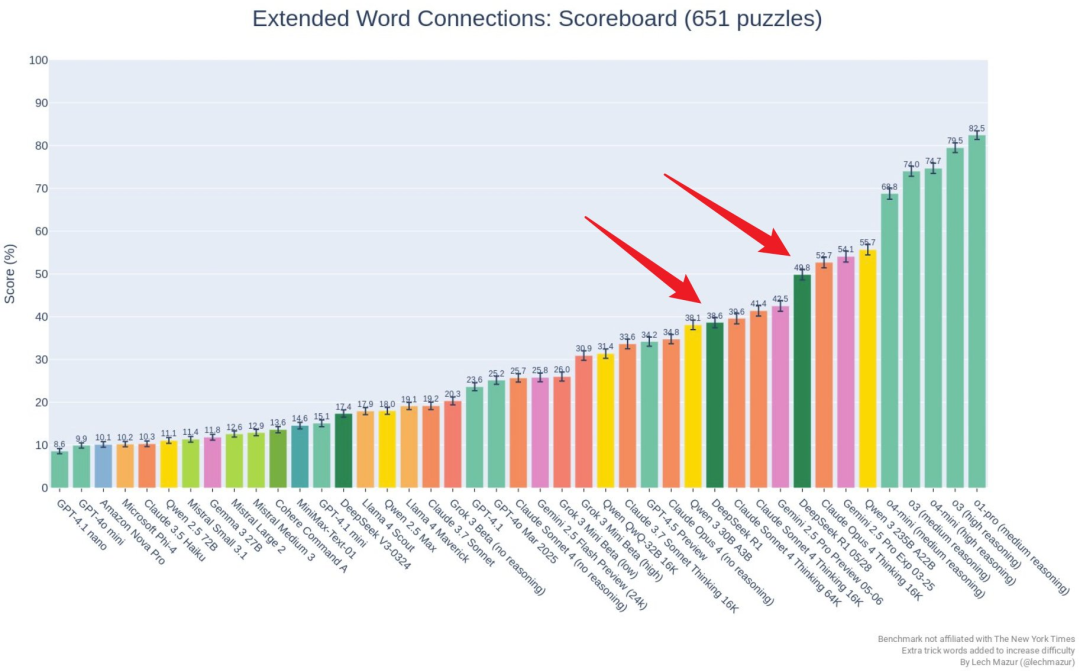
另外,其在 Extended NYT Connections 基准上的成绩也已经出炉,相比于前一代 DeepSeek-R1,最新的 0528 版本的提升非常明显,从 38.6 增至了 49.8,接近 Claude Opus 4 Thinking 16k;不过在该基准上,DeepSeek-R1-0528 仍旧没有挤进 OpenAI o 系列模型占据的第一梯队。
目前,ChatBot Arena 上也已经更新了新版本的 DeepSeek R1,让我们看看大家充分测试过后它的排名能爬到多高。
网友实测:代码能力大幅提升
虽然 DeepSeek-R1-0528 才刚出来不久,但已经有不少网友分享了自己的实测结果。
比如开发者 Haider 就通过一个编程挑战赛(构建一个词评分系统)挑战了当前主流的前沿模型,结果发现,目前只有 o3 和新版 DeepSeek-R1 能够完成这个挑战。这不禁让他感叹:DeepSeek is so back...

也有网友通过一个小球撞墙实验直观地对比了 Claude-4-Sonnet 与 DeepSeek-R1-0528 的实际表现。可以看到,DeepSeek-R1 生成的代码在模拟物理碰撞方面表现会更好一些。
Hyperbolic Labs CTO 和联创 Yuchen Jin 也进行了简单测试,发现 R1-0528 是目前唯一一个始终能正确回答「what is 9.9 - 9.11?」的模型。

下面是他录制的演示视频:
机器之心也做了一次简单的尝试,让其用 Python 编写了一个可以将 Word 文档中的图片提取到固定路径的小程序。
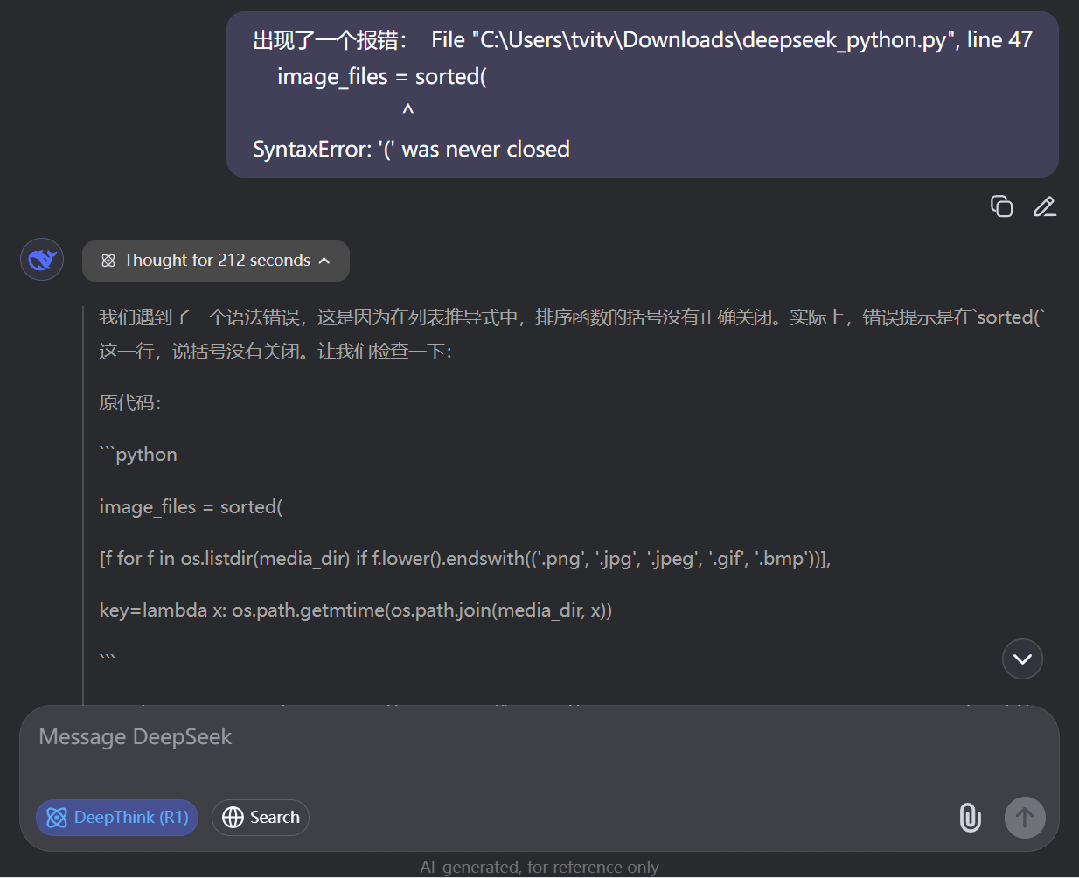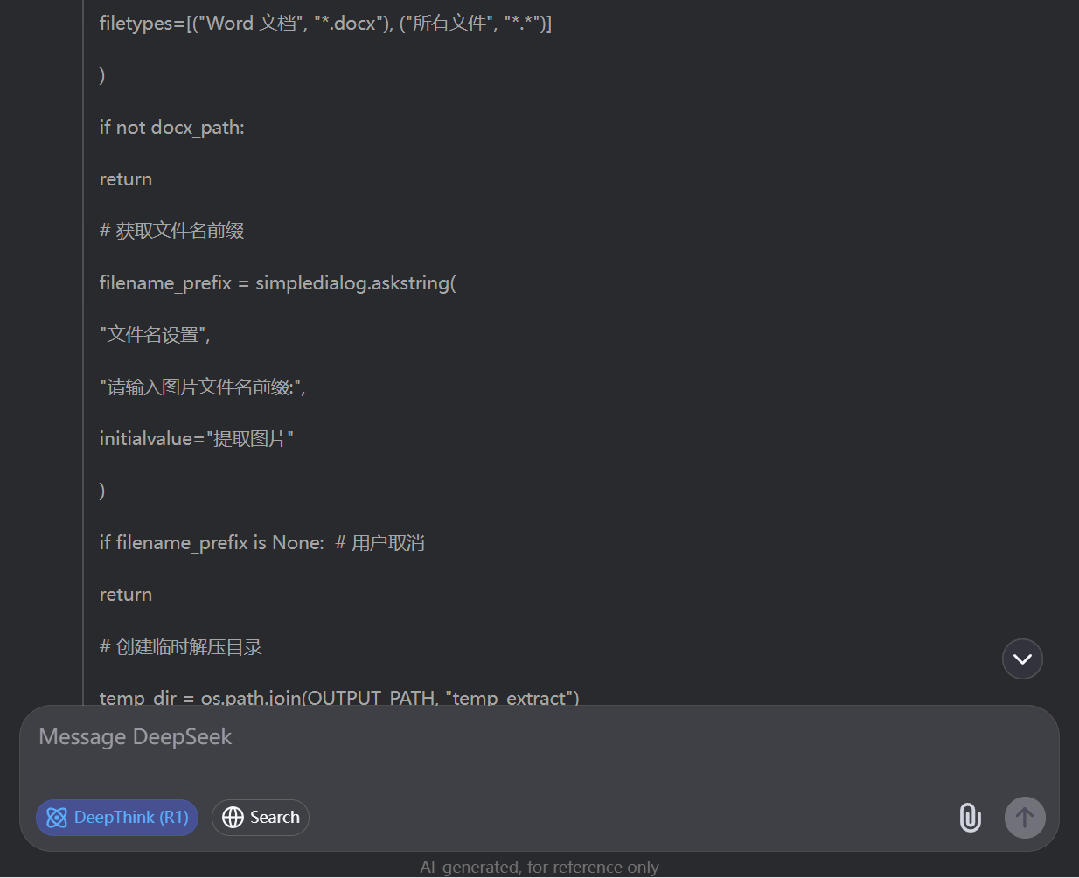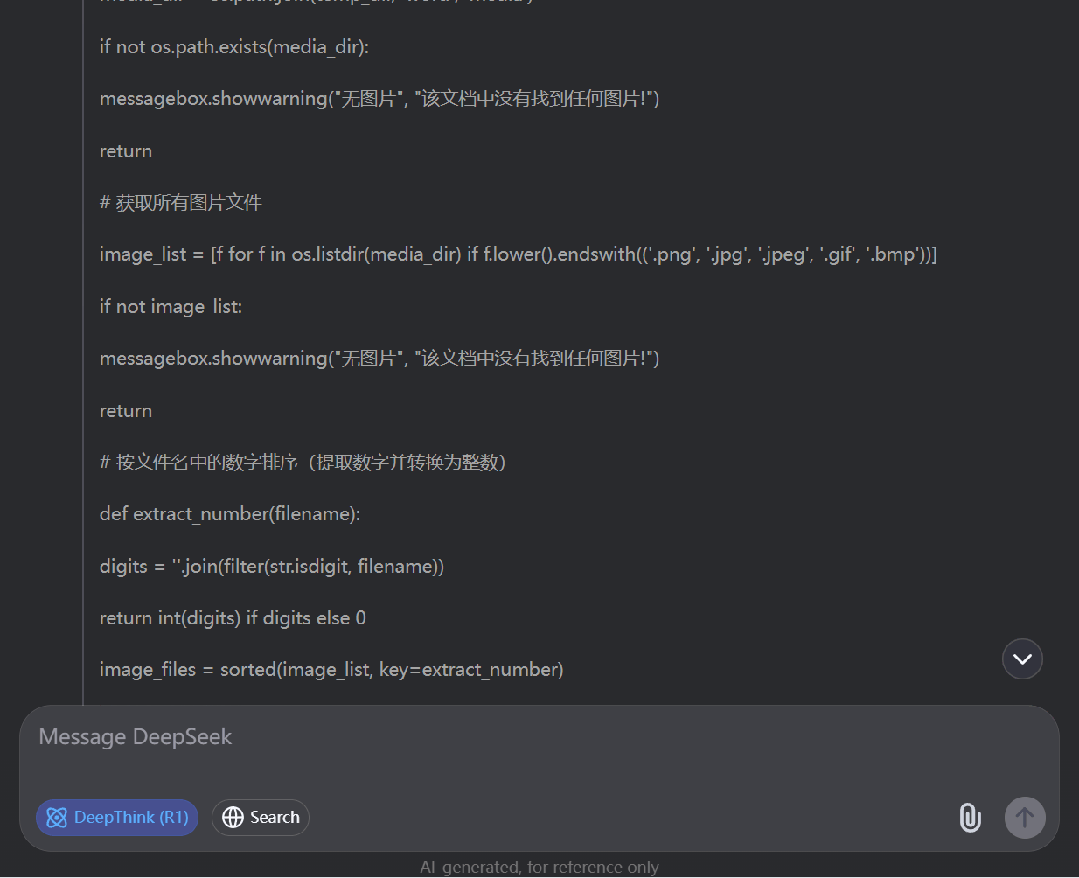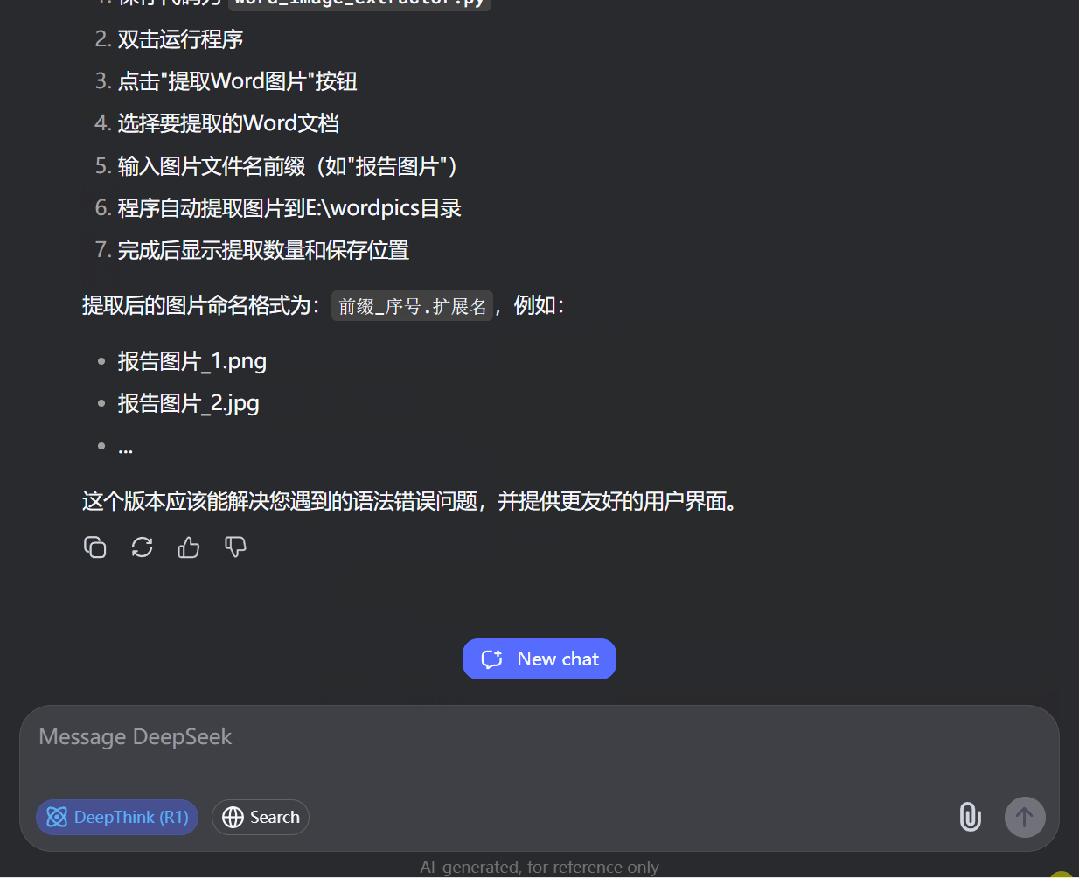
可以看到,DeepSeek-R1 用一分多钟完成了任务,那实际效果如何呢?很遗憾,出现了一个报错:

这是一个简单的句法错误,下面我们直接将其反馈给 R1-0528。结果出现了一个有趣的现象,对于这个简单报错,R1 模型思考的时间(212 秒)远远超过了之前写出整个程序的时间。
查看其思考过程可知,新版本的 R1 与之前的版本一样存在过度思考的问题,即反复思考和验证原本很简单的问题。
不过好在,修改后的程序成功完成了指定任务,就是这 UI 字体有点不协调:
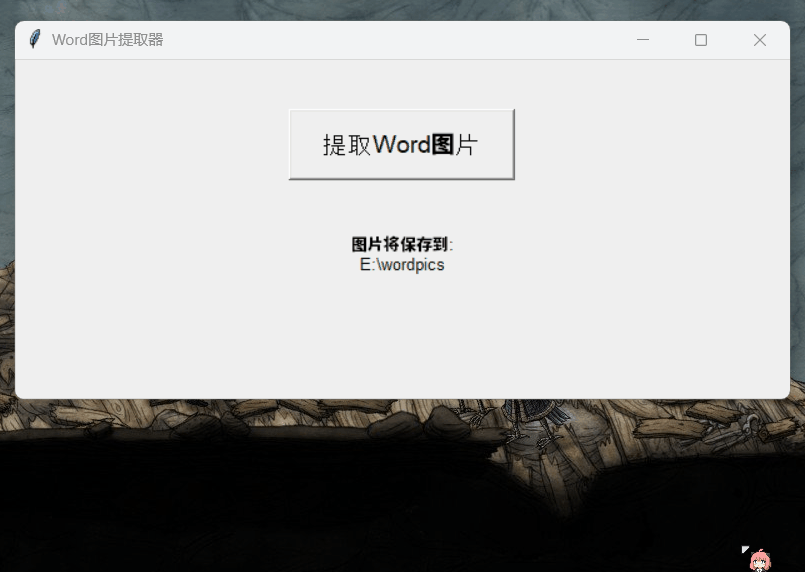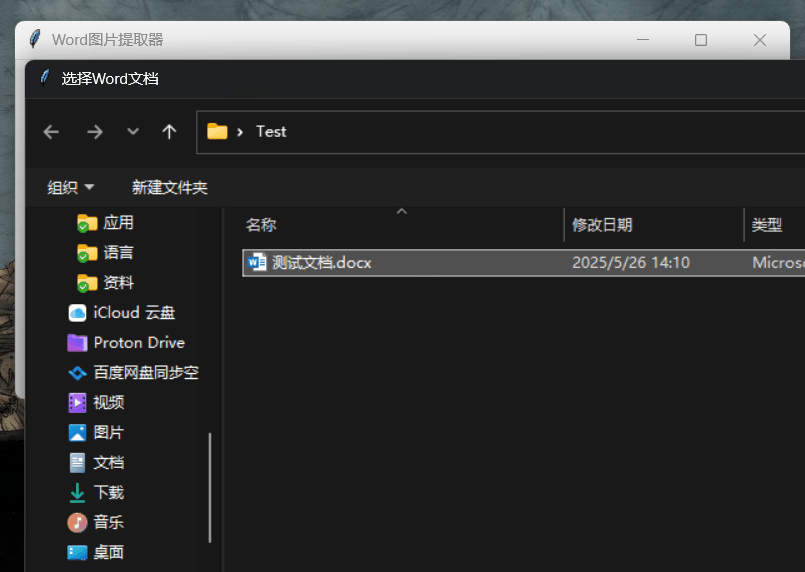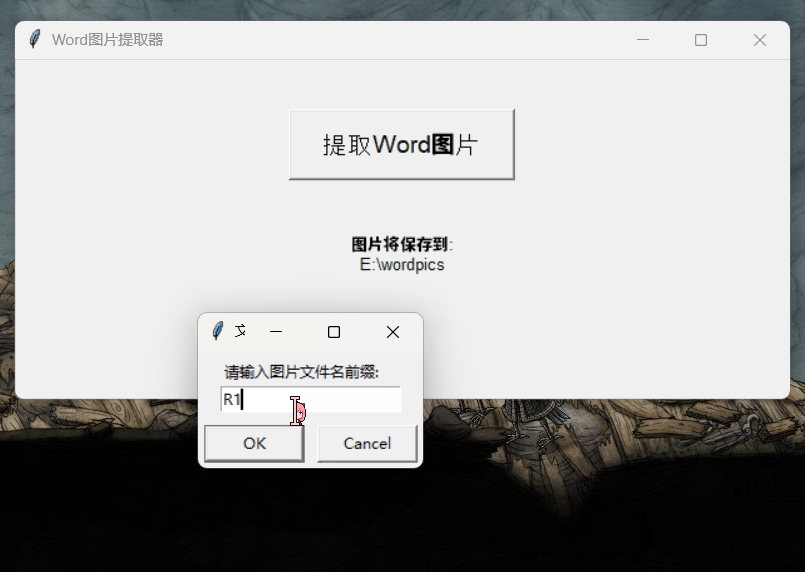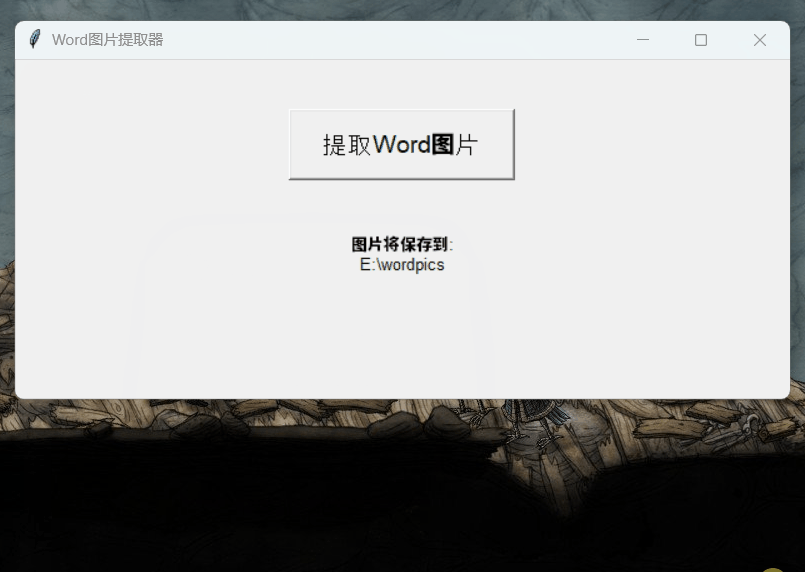
我们还进行了另一些简单测试。整体来说,我们感觉新版 DeepSeek-R1 相比前一版本确实提升不小,完成一个任务所需的对话轮次也少了许多。
最后,尽管 R1 这次提升很大,网友们还是期待 DeepSeek 尽快放出 R2。

一个小版本更新就如此惊艳,DeepSeek R2 会是什么样子?这一次,我们是不是要等到国庆节?

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com