ICML2025论文亮点:提出“偏好优化”方法,将强化学习应用于组合优化问题,通过关注解的相对优劣,显著提升求解效率和质量,在TSP、CVRP和FFSP等问题上表现突出。
原文标题:【ICML2025】组合优化问题中的偏好优化
原文作者:数据派THU
冷月清谈:
本文介绍了一种名为“偏好优化”的全新方法,旨在解决神经组合优化中强化学习方法面临的挑战,如奖励信号减弱和探索效率低下等问题。该方法通过将定量奖励转化为定性偏好,关注解之间的相对优劣,并结合策略重参数化和偏好模型构建熵正则化的强化学习目标函数,使策略直接对齐于偏好信号。此外,该方法还将局部搜索技术集成到微调阶段,以生成高质量的偏好对,从而帮助策略摆脱局部最优。实验结果表明,在旅行商问题(TSP)、容量限制车辆路径问题(CVRP)和柔性流水车间调度问题(FFSP)等多个基准测试中,该算法在收敛效率和解质量方面均优于现有强化学习方法。
怜星夜思:
1、偏好优化方法中,将定量奖励转化为定性偏好,并通过关注解之间的相对优劣来提升性能,这个思路在其他领域是否有借鉴意义?例如,在推荐系统或者金融投资领域?
2、文章提到将局部搜索技术集成到微调阶段,而非作为后处理步骤,这样做的好处是什么?为什么之前的强化学习方法通常将局部搜索作为后处理?
3、文章在TSP、CVRP和FFSP等问题上验证了算法的有效性,这些问题有什么共性?偏好优化方法在解决其他类型的组合优化问题时,是否也能取得类似的性能提升?
2、文章提到将局部搜索技术集成到微调阶段,而非作为后处理步骤,这样做的好处是什么?为什么之前的强化学习方法通常将局部搜索作为后处理?
3、文章在TSP、CVRP和FFSP等问题上验证了算法的有效性,这些问题有什么共性?偏好优化方法在解决其他类型的组合优化问题时,是否也能取得类似的性能提升?
原文内容

来源:专知本文约1000字,建议阅读5分钟本文提出了一种新方法——偏好优化(Preference Optimization)。

强化学习(Reinforcement Learning, RL)已成为神经组合优化中的一项强大工具,使模型能够在无需专家知识的前提下学习解决复杂问题的启发式策略。尽管已有显著进展,现有的RL方法仍面临诸多挑战,例如在庞大的组合动作空间中奖励信号逐渐减弱、探索效率低下等问题,导致整体性能受限。
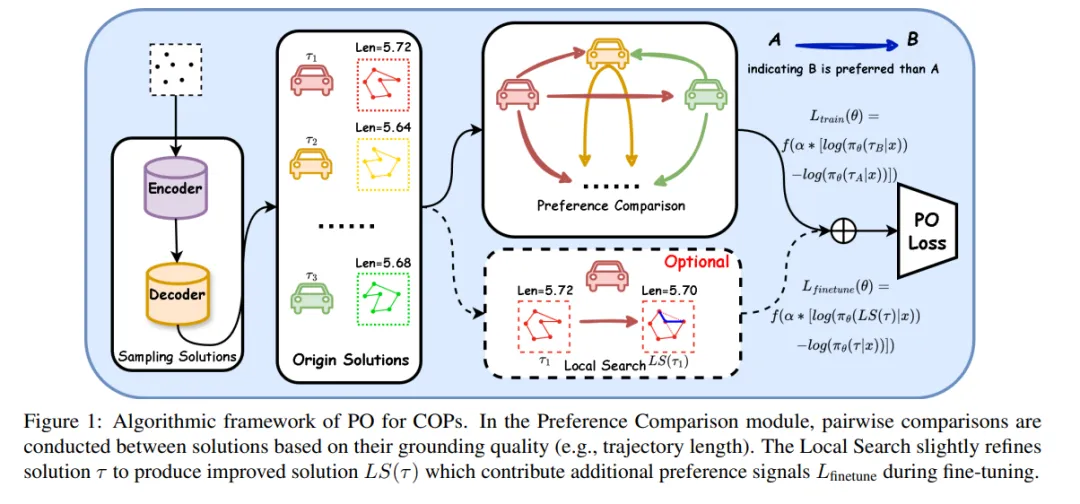
为此,本文提出了一种新方法——偏好优化(Preference Optimization)。该方法通过统计比较建模,将定量的奖励信号转化为定性的偏好信号,重点关注样本解之间的相对优劣。在方法上,我们通过对奖励函数进行策略重参数化,并引入偏好模型,构建了一个熵正则化的强化学习目标函数,该目标能够使策略直接对齐于偏好信号,同时避免了难以处理的计算复杂度。
此外,我们将局部搜索技术集成进微调阶段(而非作为后处理步骤),用于生成高质量的偏好对,从而帮助策略跳出局部最优陷阱。
在多个基准任务上的实验结果表明,例如旅行商问题(TSP)、容量限制车辆路径问题(CVRP)以及柔性流水车间调度问题(FFSP),我们的算法在收敛效率和解质量方面显著优于现有强化学习方法。