清华提出一种无监督低光图像增强与去噪框架,有效解决真实场景中低光照图像的复杂退化问题,提升图像质量。
原文标题:清华团队新作:无监督低光图像增强与去噪,效果惊艳!
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到该方法是“无监督”的,这意味着什么?相比于有监督学习方法,无监督学习在低光图像增强领域有什么优势和劣势?
3、文章中使用了离散余弦变换(DCT)对物理先验进行建模,这有什么作用?为什么选择DCT,而不是其他的变换方法,比如傅里叶变换?
原文内容

论文题目:INTERPRETABLE UNSUPERVISED JOINT DENOISING AND ENHANCEMENT FOR REAL-WORLD LOW-LIGHT SCENARIOS
论文地址:https://arxiv.org/pdf/2503.14535
代码地址:https://github.com/huaqlili/unsupervised-light-enhance-ICLR2025

创新点
-
提出了一种适用于真实场景的零参考联合去噪与低光照增强框架。该框架基于物理成像原理和Retinex理论,通过生成具有不同光照和噪声水平的配对子图像进行训练,有效解决了真实世界低光照图像中复杂的退化问题,如局部过曝光、低亮度、噪声和不均匀光照等。
-
利用离散余弦变换(DCT)对物理先验进行建模,捕捉复杂的复合退化。通过设计全局学习型编码器从先验中提取隐式退化表示,在频域内分离复杂退化特征,避免了以往方法中按顺序处理特征的局限性。
-
开发了一种新的混合先验注意变压器网络,将退化特征整合到反射图重建中,同时自适应地增强光照。这种网络设计有助于更好地处理多种退化模式,提高融合图像的质量和细节保留。
方法
本文提出了一种适用于真实场景的零参考联合去噪与低光照增强框架。该框架基于物理成像原理和Retinex理论,通过生成具有不同光照和噪声水平的配对子图像进行训练。方法首先利用离散余弦变换(DCT)对物理先验进行建模,捕捉复杂的复合退化,并设计全局学习型编码器从先验中提取隐式退化表示。接着,开发了混合先验注意变压器网络,将退化特征整合到反射图重建中,同时自适应地增强光照。
与其他方法在SIDD数据集上的结果对比

本图展示了本文方法与其他先进方法(如Liang et al. (2023)、Ma et al. (2022))在SIDD数据集上的去噪、增强和颜色保真度方面的对比结果。图中显示了不同方法处理后的图像效果,突出了本文方法在保持颜色真实性和增强图像细节方面的优势。
整体框架
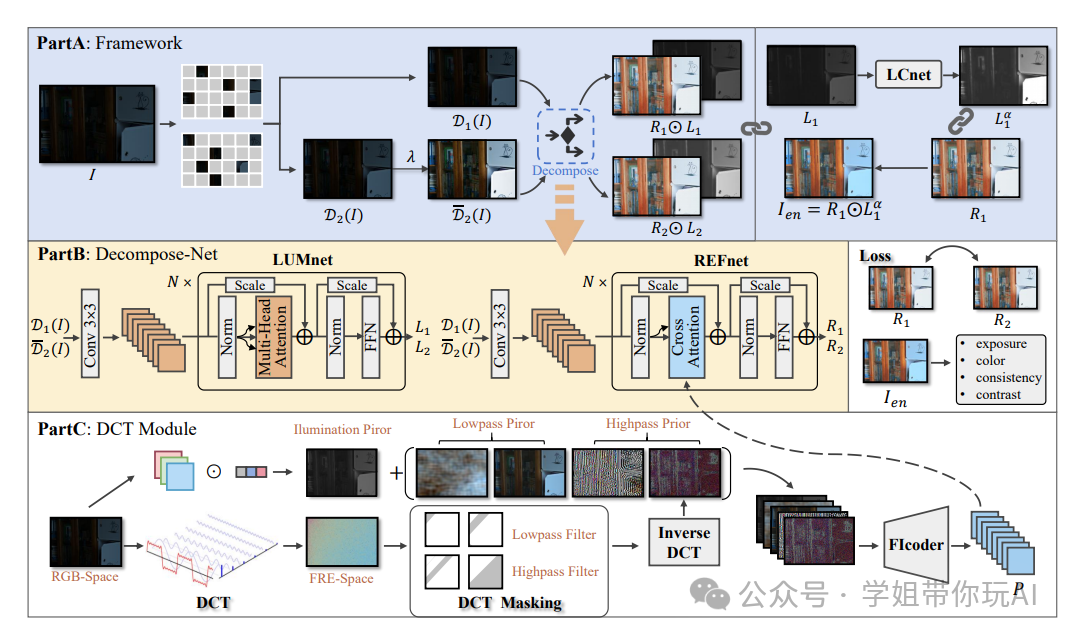
本图详细展示了本文方法的处理流程。首先,通过像素掩蔽和基于伽马的非线性增强对低光照全分辨率图像I进行预处理,生成具有不同光照和噪声水平的子图像。这些子图像随后经过Decompose-Net处理,该网络采用集成混合退化表示的变压器架构,并通过交叉注意力注入引导嵌入。最后,LCnet用于增强光照图。
多头交叉注意力引导的混合先验退化表示的说明
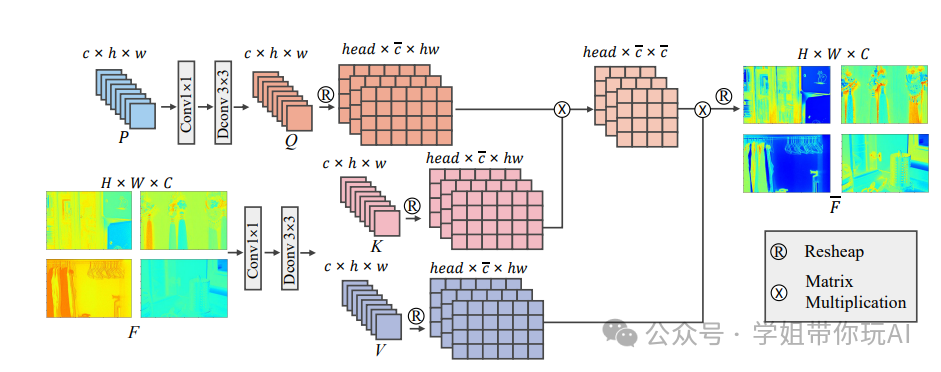
本图中说明了在REFnet中,特征令牌如何与退化表示进行交叉注意力计算,以指导反射率图的提取。经过处理后,特征图显示出更清晰的层次结构和更少的噪声,表明这种机制有效地整合了多种退化特征。
实验结果
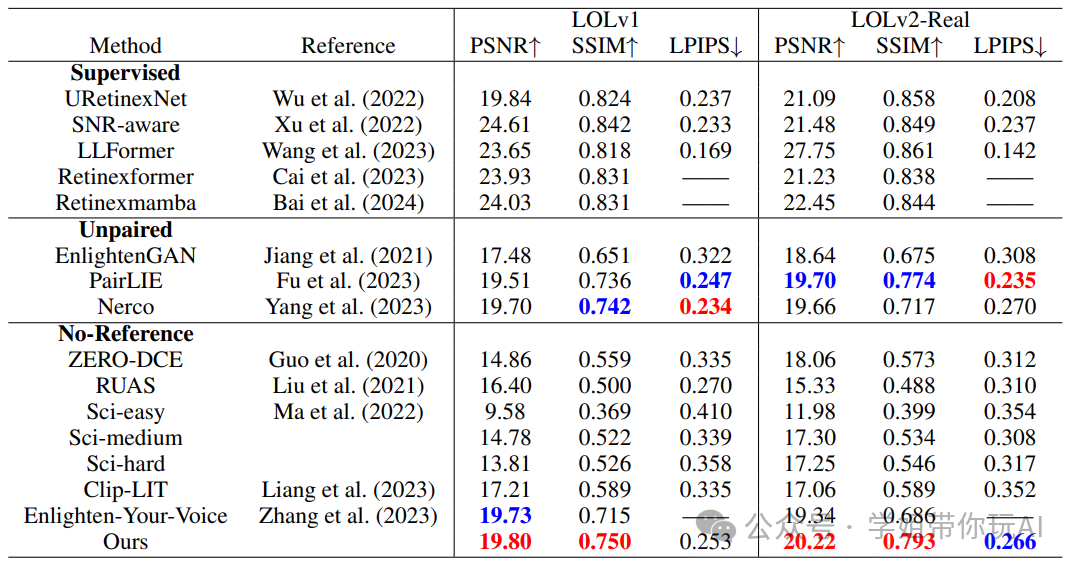
本表格详细列出了不同低光照图像增强方法在 LOLv1 和 LOLv2-Real 数据集上的性能评估结果,具体指标包括 PSNR↑、SSIM↑和 LPIPS↓。这些指标从不同角度反映了增强后图像的质量,其中 PSNR 和 SSIM 主要衡量图像的客观质量,LPIPS 则更侧重于感知质量。表中比较的方法涵盖了监督学习方法(如 URetinexNet、SNR-aware、LLFormer、Retinexformer 和 Retinexmamba)、无配对学习方法(如 EnlightenGAN、PairLIE 和 Nerco)、以及无参考学习方法(如 ZERO-DCE、RUAS、SCI 等)。可以看出,监督学习方法通常在 PSNR 和 SSIM 等客观指标上有较好的表现,但在 LPIPS 等感知指标上可能稍逊一筹。
