对比四种开源工具在 PDF 转 Markdown 用于 RAG 上的效果,Docling 信息提取出色但速度慢,可通过并行处理优化。
原文标题:独家|为RAG准备好PDF
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到了使用云服务并行处理来加速 Docling 的转换速度,你认为这种方式还有哪些潜在的风险或者需要注意的地方?
3、如果让你设计一个 PDF 转换为 Markdown 的最佳方案,你会如何结合这四种工具的优点?
原文内容

我从几十份年度报告(带图表)中创建了一个图形存储。
![]()

图片来自Unsplash的年度报告设计机构-Yak Report
可以将PDF转换成文本但是从来没那么容易过。
我最近在RAG(检索增强生成,retrieval-augmented generation)中创建了一个图形数据存储。换句话说,我们创建了一个GraphRAG。
如何在几分钟内建立一个知识图形(并使其适合企业使用)
图形RAG对其他广泛使用的支持矢量存储的RAG软件来说是一个极好的替代。他们引入了推理。例如,使用语义相似性检索(在矢量存储中用于提取信息的技术),你可以提问去年某一公司的CFO是谁。因为某一公司去年的年度报告会明确提到它的CFO。但是考虑这样一个问题:某公司的哪两位主管曾在同一学校学习?如果没有提到学校名字,提取过程并不能获取任何相关信息。但是图形RAG可以。
然而,关键问题是我们如何构建图形来提取信息。我最近在另一篇文章中提到这个问题。往回想一步,我们是如何以更容易创建图形的方式来准备年度报告的呢?
这是本文的关注点所在。
我们所有工作的第一步是将PDF数据转换成文本。然而,年度报告是复杂的文件。不会仅仅有文本。还有图和表等等。每一部分都提供了关于公司的关键信息。
所以,让我们从这里开始。
如何将PDF转换为富文本
大多数Python程序员都会在某些时候使用PDF阅读器——至少是为了跟随教程。最流行的事PyPDF2。
大多数的库确实能够完成工作。但是信息的帮助性却不大。
我很多年前就知道PyPDF2库了,它能提取所有的PDF内容为文本,没有任何格式。提取之后,你就不知道什么是题目什么是列表了。
然后就是PyMuPDF4LLM。这个包可以直接将PDF转换为markdown。Markdown也有大量关于文本结构的关键信息。像Langchain这样的框架支持markdown。他们使用文本格式中的额外信息来更好地分块和存储数据。反过来也使得提取相关数据更加容易。
PyMuPDF4LLM的问题在于,它不能很好地处理表格。提取的表格与原始表格相差甚远。(不要放弃PyMuPDF4LLM。它在我们的最终解决方案中仍然发挥了不可思议的作用)。
最近,我们尝试了几个其他的现代工具。一个是Docling,由IBM Deep Search开发的开源库,另一个是Marker,一个同样非常好的库。
下面是我们讨论的四个包转换的相同Pdf页输出。
PyPDF2:
![]() 信息提取为文本从PDF使用PyPDF2 -截图来自作者。
信息提取为文本从PDF使用PyPDF2 -截图来自作者。
PyMuPDF4LLM:
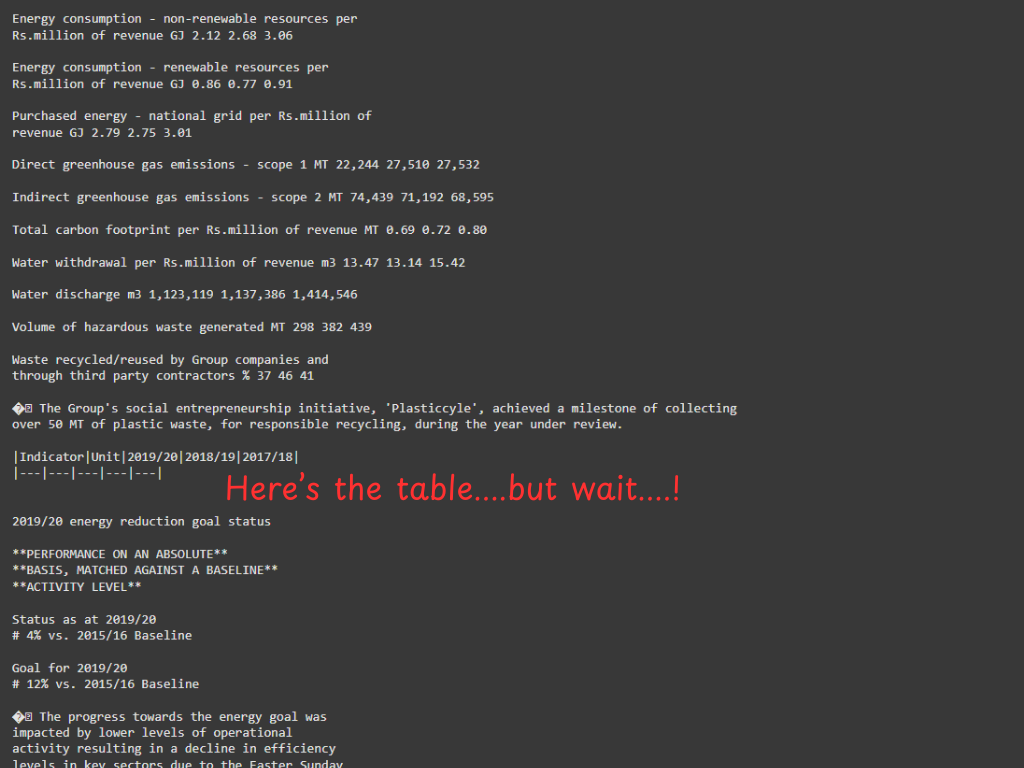
使用PyMuPDF4LLM从PDF中提取的降价信息-截图来自作者。
Docling:
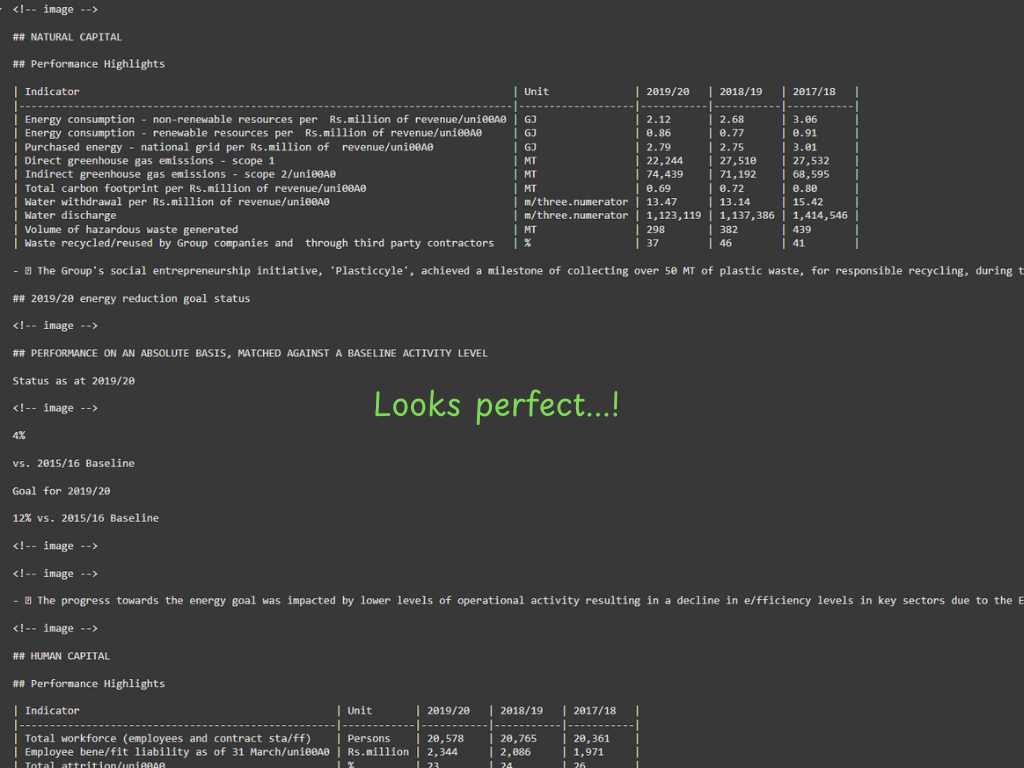
信息提取作为标记从PDF使用粘贴-截图来自作者。
Marker:
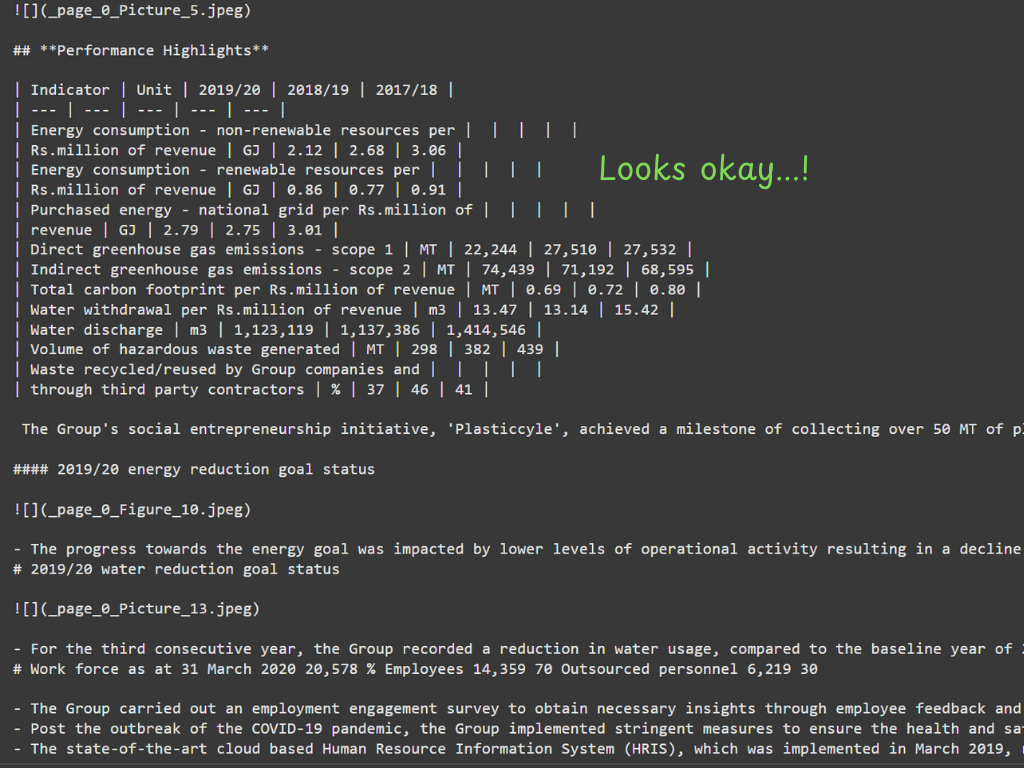
信息提取为markdown从PDF使用标记-截图来自作者。
Docling版本比其他两个版本更简洁,有更多的结构信息。它提取了包含所有相关信息的表格。它为图像留下了占位符,并保留了分层标题结构。所有这些信息都有助于创建块、图形数据库、更好的检索,并最终实现更好的RAG系统。
什么做得不好?
Marker和docking都很有前景。但是,如果我们花时间将PDF 转换为markdown,我不会很满意。
为了正确测试这一点,我对年度报告的一部分进行了分区,其中包括文本、表格和图像的混合。然后我用不同的页数创建了几个副本。
然后,我用每个工具对这些不同大小的PDF文件进行转换,并测量它们所花费的时间。这是最终结果。
![]()
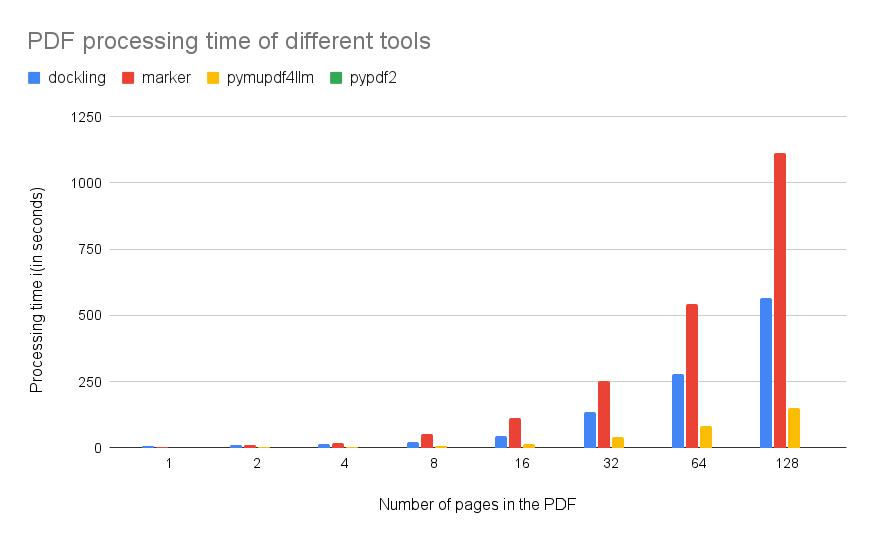
结果清晰表明Docling以及PyPDF2远不及另外两个选项速度快,尽管他们转换表格的能力让人印象深刻。
Docling处理单个PDF页大约需要4秒钟,而Marker需要双倍的时间。
我做了什么?
如何选择最佳的PDF转换Markdown工具
我们的项目有几十份年报。庆幸不是几百份。
如果每份年报大约300页,有50份使用docking,我们就需要17个小时(每份报告300页*50份报告*4秒每页/3600秒每小时)。
因此,我们可以负担得起这个时间。
但我们还在原型阶段。我们需要考虑扩大这个项目的规模。如果这个项目扩展到所有标准普尔500指数公司及其30年历史报告呢?
除非我们分配负载并同时执行,它将花费208天,这正是我们所做的。
我们创建了一个服务,可以在云上处理这些转换,并上传至图形数据库。这可以并行运行,并且可以很好地扩展。
如果您关注的是速度,那么PyPDF2是最好的——如果您不能在并行进程中运行docling的话。
最后的想法
PDF到markdown转换工具越来越强大了。但是转换PDF的表格到markdown表格仍然不够好。
我们已经比较四种免费的开源工具。然后,我们将markdown分块,并在一个RAG软件中将它们转换成图表。
在我们比较的工具中,Docling产生了出色的效果。不过,缺点在于它的性能。它比广泛使用的PyPDF2时间长得多。
因此,我们转移到云服务上,它可以很好地扩展并行进行转换。
感谢阅读,朋友!除了Medium,我也在LinkedIn和X上!
原文标题:
Preparing PDFs for RAGs
原文链接:
https://towardsdatascience.com/preparing-pdfs-for-rags-b1579fc697f1/
译者简介

翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
