介绍GRAPHGPT-O,一种新型多模态大语言模型框架,可从图结构数据中联合生成图像和文本,有效提高多模态数据处理能力。
原文标题:CVPR 2025|多模态图像生成!图结构×大模型强强联手!
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、GRAPHGPT-O模型中,图结构Q-Former的作用是什么?如果用GNN替代Q-Former,性能为什么会下降?
3、文章提到了顺序推理和并行推理两种生成策略,这两种策略分别适用于什么场景?有没有可能将二者结合起来,以获得更好的生成效果?
原文内容

来源:多模态机器学习与大模型本文共1300字,建议阅读5分钟
本文提出一种面向多模态属性图(MMAGs)的多模态大语言模型(MLLM)框架。

-
论文链接:https://arxiv.org/pdf/2502.11925
简介
本文提出 GRAPHGPT-O,一种面向多模态属性图(MMAGs)的多模态大语言模型(MLLM)框架,支持从图中联合生成图像和文本。为解决图规模爆炸、图结构非欧几里得性质、模态层级依赖和推理顺序依赖等关键挑战,GRAPHGPT-O 引入了:PPR 采样机制,图结构线性化或层级表示方法,融合 Q-Former 的层次对齐器,适应多种生成策略的推理机制。该方法在多个真实领域数据集(如 ART500K 和 Amazon-Beauty)上实现了显著优于现有基线模型的性能。
研究动机
虽然MLLMs能处理图文输入,但现实中的图文数据常以图结构存在(如商品图谱、艺术品网络),包含节点关联(例如同作者、同风格),但 MLLMs 难以直接利用此类结构性信息。面临挑战包括:
(1) 图结构爆炸:邻居扩展导致上下文过长;
(2) 非欧空间:图无法直接序列化处理;
(3) 模态层级依赖:节点与子图间信息结构复杂;
(4) 推理依赖性:文本与图像生成顺序互相影响。
论文贡献
(1)提出了一种基于 PageRank 的个性化图采样方法来提取相关子图信息,从而有效缓解图大小爆炸问题。
(2)研究了图线性化的各种设计方法,使其非欧几里得性质适应顺序 MLLM 处理范式。
(3)构建了一个分层图对齐器,结合节点级模态融合 Q-Former 和图结构 Q-Former 来捕获 MMAG 中的分层模态依赖关系。
(4)探索了不同的推理策略,包括顺序和并行生成,以解决 MMAG 中跨模态的推理依赖关系。凭借自适应图提示设计和专门的对齐技术,GRAPHGPT-O 实现了 MMAG 中的有效理解和内容生成,克服了与图拓扑和多模态属性集成相关的关键挑战。
GRAPHGPT-O模型
图1给出了模型的整体框架。输入为一个多模态属性图 ,节点 同时具备文本 和图像 。目标是联合生成 ,即:

给定多模态属性图 (MMAG) 中的目标节点,首先使用个性化 PageRank 进行邻居采样。然后,这些采样的邻居节点被输入到分层多模态对齐器 (Hierarchical Multimodal Aligner),该对齐器负责对齐文本、图像和图结构数据。节点的每个模态最初都经过编码,并通过多个自注意力层和交叉注意力层进行融合,以生成多模态节点 token。随后,这些 token 由图结构 Q-former 处理,最终作为多模态 LLM 的输入。
GRAPHGPT-O 框架主要由4个步骤组成,(1)将图信息引入 MLLM。(2)基于 PageRank 的个性化图采样策略,以应对图规模爆炸式增长的挑战。(3)图线性化策略,开发了一个分层图对齐器,以解决图的非欧几里得特性并捕捉 MMAG 中的分层模态依赖关系。(4)探讨不同的生成策略来管理跨模态的推理依赖关系。
PPR 采样——缓解图规模爆炸
使用 Personalized PageRank (PPR) 计算与目标节点相关的邻居:
-
PPR 传播方程:
-
邻居选择:

图线性化与层级对齐——解决图结构输入问题
线性表示: 将邻居节点的文本/图像按顺序打包为序列输入:

层级 Q-Former: 两级 Transformer 结构,对图进行深层次对齐:
-
节点级 Q-Former:
-
输入拼接:
-


-
跨注意力提取核心表示:
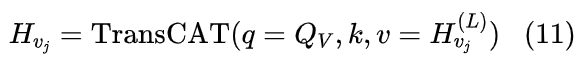
-
自注意力层:
-
图结构 Q-Former:
-
初始输入:
-



-
输出融合:
-
层级自注意力:
最终将图结构表示 输入 MLLM。
多模态生成优化-融合图、文、图像
-
模态统一训练损失:

-
图像生成(Stable Diffusion)损失:

推理机制设计——解决模态顺序依赖
提供两种推理方案:
(1)顺序推理
-
文本先:
-
图像先:
(2)并行推理
实验结果与分析
📊 数据集
-
ART500K:艺术品图谱(图像+标题+风格关系)
-
Amazon-Beauty / Amazon-Baby:商品图谱(图像+标题+共购关系)
📈 指标
-
CLIP-I2:生成图像质量(图像 vs GT)
-
CLIP-IT:图文对齐性
-
Perplexity:文本生成连贯性
-
KL-DV:生成节点与邻居分布的 KL 散度





