新算法RXTX助力XX^T矩阵乘法运算性能提升5%,由强化学习与组合优化技术驱动,有望显著降低能耗,但工程化应用仍面临挑战。
原文标题:矩阵乘法新突破!XX^T原来可以更快!RL助力搜索,世界纪录又被提升了5%
原文作者:机器之心
冷月清谈:
怜星夜思:
2、RXTX算法在小规模矩阵上已经超越了Strassen算法,那么在实际应用中,对于不同规模的矩阵,我们应该如何选择合适的矩阵乘法算法?有没有一个通用的选择标准?
3、文章提到RXTX算法的工程化应用仍面临挑战,特别是硬件适配和内存管理。大家觉得有哪些具体的工程难题需要解决?以及可以从哪些方面入手来克服这些难题?
原文内容

深圳市大数据研究院、香港中文大学(深圳)研究团队最新研究发现,![]() 这类特殊的矩阵乘法可以进一步加速,并在强化学习与组合优化技术的结合下发掘出了一种新的算法,节省 5% 的乘法数量。
这类特殊的矩阵乘法可以进一步加速,并在强化学习与组合优化技术的结合下发掘出了一种新的算法,节省 5% 的乘法数量。

-
论文标题:XXt Can Be Faster
-
论文链接:https://arxiv.org/abs/2505.09814
该成果在国际社交媒体平台 X 引发热烈讨论,并引起 MIT、斯坦福、哈佛及 Google DeepMind 科学家的广泛关注。
背景
矩阵乘法优化堪称计算机科学领域的「珠穆朗玛峰」。自 1969 年 Strassen 算法横空出世以来,这个充满组合爆炸可能性的数学迷宫就持续考验着人类智慧的边界。
Google DeepMind 为此专门投入四年心血,先后推出 AlphaTensor、AlphaEvolve 等机器学习系统来攻克这一难题。这就像短跑运动员将百米纪录从 9.58 秒推进到 9.57 秒——每个 0.01 秒的突破背后,都是对计算理论极限的重新定义。
![]() (矩阵乘以自身的转置)这类特殊的矩阵乘法广泛存在于各类数据科学的实际应用中,实际应用包括:
(矩阵乘以自身的转置)这类特殊的矩阵乘法广泛存在于各类数据科学的实际应用中,实际应用包括:
-
5G 与自动驾驶定制芯片设计
-
线性回归与数据分析
-
大语言模型训练算法(Muon、SOAP)
![]() 这类操作每分钟在全球执行数万亿次,假如能减少该操作的计算量,对能耗开销可以带来相当可观的节省。令人惊讶的是,相比于普适的矩阵乘法 AB,研究者对于
这类操作每分钟在全球执行数万亿次,假如能减少该操作的计算量,对能耗开销可以带来相当可观的节省。令人惊讶的是,相比于普适的矩阵乘法 AB,研究者对于 ![]() 这类的特殊矩阵乘法的关注少之又少。Google DeepMind 的 AlphaTensor、AlphaEvolve 探索了带有特殊结构的 AB 矩阵乘法,但他们尚未汇报任何关于
这类的特殊矩阵乘法的关注少之又少。Google DeepMind 的 AlphaTensor、AlphaEvolve 探索了带有特殊结构的 AB 矩阵乘法,但他们尚未汇报任何关于 ![]() 的结果。
的结果。
通过观察![]() 运算的特殊结构,该团队发现
运算的特殊结构,该团队发现 ![]() 的计算确实存在加速空间!
的计算确实存在加速空间!
主要贡献
在 AI 技术的辅助下,研究团队发掘了新算法(RXTX),以让 ![]() 这一常见的底层操作减少 5% 的运算量,这可以进一步转换成节省 5% 的能耗以及时间(特别的,能耗开销主要由乘法运算数量决定)。值得一提的是,RXTX 的 5% 加速不仅对超大规模矩阵成立,对小规模矩阵也成立,比如:RXTX 对 4x4 矩阵 X 仅需 34 次乘法运算。此前最先进的 Strassen 算法需要 38 次乘法(减少 10% 运算量)。
这一常见的底层操作减少 5% 的运算量,这可以进一步转换成节省 5% 的能耗以及时间(特别的,能耗开销主要由乘法运算数量决定)。值得一提的是,RXTX 的 5% 加速不仅对超大规模矩阵成立,对小规模矩阵也成立,比如:RXTX 对 4x4 矩阵 X 仅需 34 次乘法运算。此前最先进的 Strassen 算法需要 38 次乘法(减少 10% 运算量)。


乘法运算量复杂度分析
研究团队对乘法运算量的复杂度进行了分析。分析结果表明,RXTX 的渐进常数 26/41≈0.63,较先前最优值 2/3≈0.66 降低 5%。

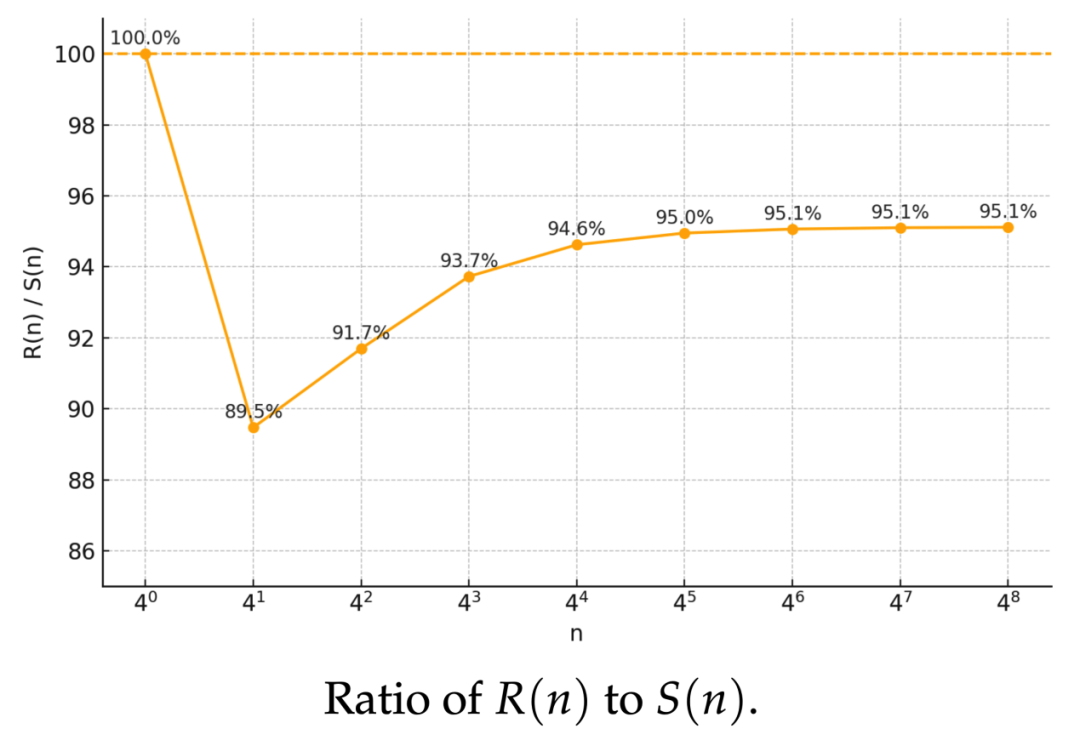
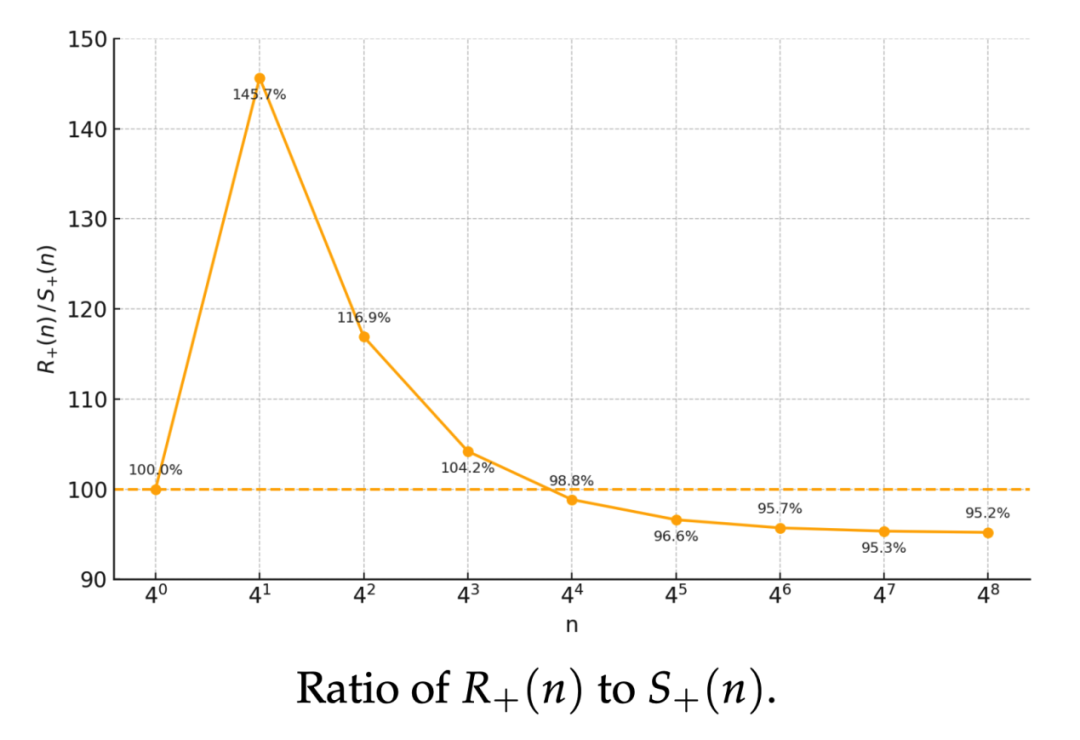
总运算量(乘法+加法)复杂度分析
研究团队进一步提供了总运算量(乘法+加法)的复杂度分析。分析结果表明,当 n≥256 时,RXTX 的总加法与乘法次数也少于现有最优方案,且渐进意义下约有 5% 的稳定提升。

核心技术
该方法属于基于神经网络的大邻域搜索方法框架:
-
利用强化学习策略生成候选双线性乘积
-
构建组合问题一(MILP-A):将目标表达式构建为候选乘积的线性组合
-
构建组合问题二(MILP-B):筛选能完整表达
 结果的最小乘积集
结果的最小乘积集
这是 DeepMind 的 AlphaTensor 方法的一种变体——通过使用组合求解器,行动空间被缩小了一百万倍。以下为研究团队提供的 2*2 矩阵的简单例子:

总结
本文针对 ![]() 这类特殊矩阵乘法提出了创新性加速方法,通过引入 AI 方法设计出新型算法「RXTX」,成功实现了总运算量 5% 的优化。这一突破不仅从理论上拓展了人类对计算复杂度边界的认识,也为相关领域的算法优化提供了新的研究范式。
这类特殊矩阵乘法提出了创新性加速方法,通过引入 AI 方法设计出新型算法「RXTX」,成功实现了总运算量 5% 的优化。这一突破不仅从理论上拓展了人类对计算复杂度边界的认识,也为相关领域的算法优化提供了新的研究范式。
鉴于 ![]() 矩阵在多个学科领域的基础性作用,本研究成果有望为实际应用场景带来显著的能耗优化。然而,新算法的工程化应用仍面临硬件适配和内存管理等关键挑战,其产业化落地尚需学术界与工业界的持续协同攻关。要实现新算法的全方面落地,仍然面临诸多挑战,可谓任重道远。
矩阵在多个学科领域的基础性作用,本研究成果有望为实际应用场景带来显著的能耗优化。然而,新算法的工程化应用仍面临硬件适配和内存管理等关键挑战,其产业化落地尚需学术界与工业界的持续协同攻关。要实现新算法的全方面落地,仍然面临诸多挑战,可谓任重道远。
参考资料
Rybin, Dmitry, Yushun Zhang, and Zhi-Quan Luo. "$ XX^{t} $ Can Be Faster."arXiv preprint arXiv:2505.09814 (2025).

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com