40位数学家组队挑战OpenAI模型,结果AI以6:2胜出。AI的数学能力正在快速逼近人类专家水平。
原文标题:40位数学家组成8队与o4-mini-medium比赛,6队败北
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到人类专家可能因为时间限制而表现不佳,如果给人类团队更多时间或者允许使用更强大的计算工具,结果会如何?
3、你认为类似的“人机大战”对 AI 的发展有什么意义?是炒作噱头,还是真的能推动 AI 技术进步?
原文内容
编辑:Panda、陈陈
最近,AI 在数学和编程上的能力飞跃令人瞠目结舌 —— 在不少任务上,它已经悄然超越了我们大多数人类。而当它面对真正的专家,会发生什么?
Epoch AI 最近安排了一场硬仗:他们请来了 40 位数学家组成 8 支战队,与 OpenAI 的 o4-mini-medium 模型正面对决,考题来自高难度的 FrontierMath 数据集。
结果令人出乎意料:8 支人类队伍中,只有 2 支打败了 AI。也就是说,o4-mini-medium 以 6:2 的比分击败了由数学专家组成的「人类代表队」。Epoch AI 得出的结论是:「虽然 AI 还未明显达到超人级水平,但或许很快了。」
这场比赛引起了不少关注,有人认为 Gemini 2.5 Pro 深度思考就是 AI 明确超越人类的转折点,但也有人为人类打抱不平,认为对人类专家而言,4.5 小时不足于解答高难度数学题。对此你有什么看法呢?
下面就来具体看看这场「人机数学大战」吧。
人类在 FrontierMath 上的表现如何?
FrontierMath 是 Epoch AI 去年发布的一个基准,旨在测试 AI 数学能力的极限。其中包含 300 道题,难度从本科生高年级水平到连菲尔兹奖得主都觉得难的水平都有。
为了确定人类的基准,Epoch AI 在麻省理工学院组织了一场竞赛,邀请了大约 40 名优秀的数学本科生和相关领域专家参赛。参赛者被分成 8 个团队,每个团队 4 到 5 人,任务是在 4.5 小时内解答 23 道题,过程中可以使用互联网。
之后,他们与目前在 FrontierMath 基准上表现最好的 AI 系统进行了较量,即 o4-mini-medium。
结果如何?o4-mini-medium 的表现优于人类团队的平均水平,但低于所有团队的综合得分(至少有一支团队成功解答的问题的比例)。因此,AI 在 FrontierMath 上的表现还未达到明显的超人类水平 —— 但 Epoch AI 认为它们很快就会达到。
下图展示了人类与 AI 的成绩概况,详细的竞赛结果可在此电子表格中查看:https://docs.google.com/spreadsheets/d/11vysJj6_Gv8XE9U9qb2bq9PLqwW0Cj1HwFAA7lnl-LA/edit?usp=sharing
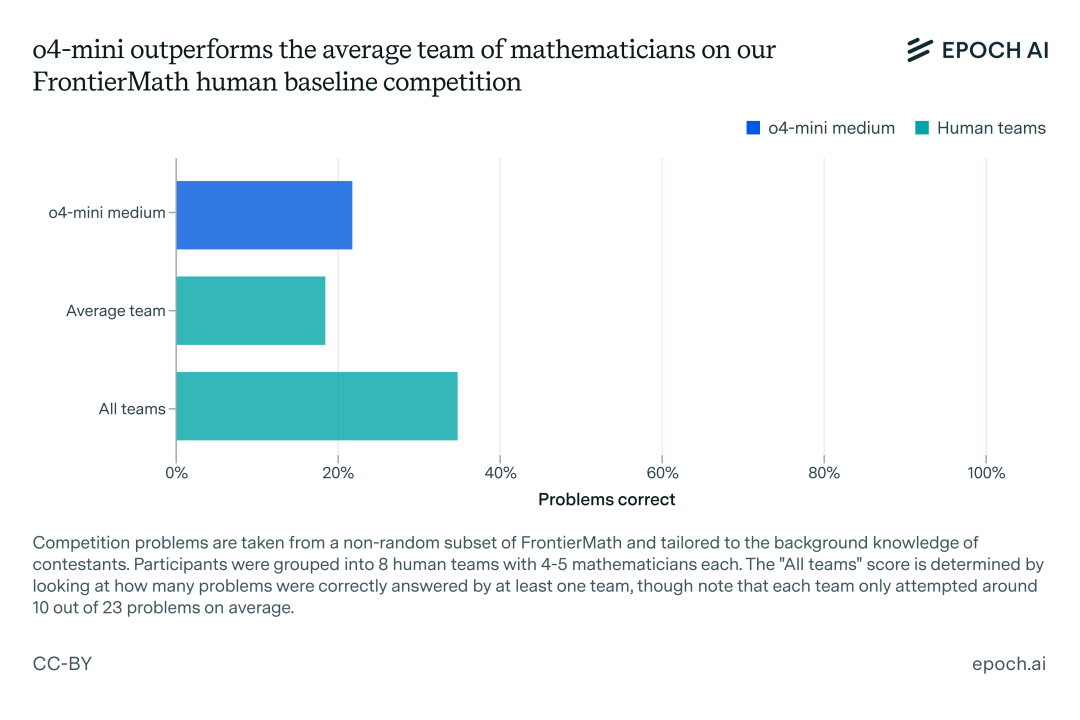
o4-mini-medium 在 FrontierMath 人类基准竞赛中得分为 22%,高于平均水平(19%),但低于所有团队的总得分(35%)。需要注意的是,o4-mini-medium 成功解答的问题都至少有一支人类团队成功解答。
然而,这些数据仅基于 FrontierMath 中一个不具代表性的小子集 —— 那么这对整体人类基准意味着什么呢?
Epoch AI 认为在 FrontierMath 上最具参考价值的「人类基准」应该在 30% 到 50% 之间,但遗憾的是,这个数字只是估测的,并不明晰。
下面,Epoch AI 简要解释了关于这个人类基准结果的四个方面,包括它的来源及其含义。
1. 参与者并不能完全代表前沿数学水平
为确保研究结果的高质量,参与人员需展现出卓越的数学能力。例如,符合条件者需具备数学相关博士学位,或本科阶段拥有极其突出的数学竞赛获奖记录。
该研究将参与者分为 8 个小组,每组 4 至 5 人,并确保每个团队在任一特定领域至少配备一名学科专家。这些学科专家可能是在该领域拥有研究生学位或正在攻读博士学位的人,并将该学科列为他们的首选领域。
2. 竞赛的目标是检验推理能力,而非一般知识
比赛过程更注重考查 AI 的推理能力,而非掌握了多少知识。
因而,FrontierMath 题库涵盖数论、微分几何等需要进行推理的领域,但在现实中,没有人类能同时精通所有这些学科的前沿进展。
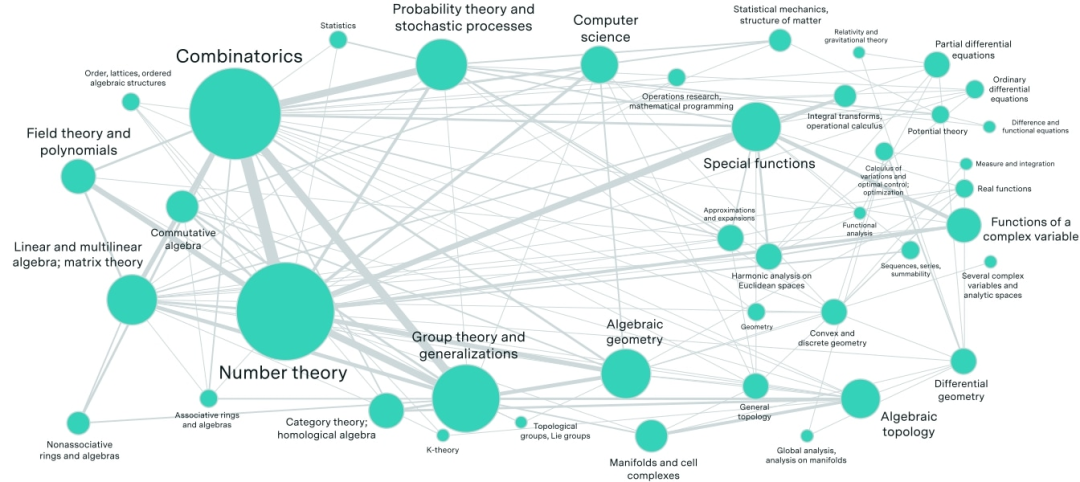
完整 FrontierMath 基准测试所包含的领域
前面已经强调,FrontierMath 最核心的优化目标是 AI 系统是否具备数学推理能力。
为了获得更具参考价值的人类基准,该研究选取了 7 道基础题(适合优秀本科生解答)和 16 道进阶题(针对参与专家定制),这些题目分为四个子类:(1) 拓扑学,(2) 代数几何,(3) 组合数学,(4) 数论。
评分机制为,答对一道进阶题得 2 分,答对一道基础题仅得 1 分。此外,在五大领域(基础题类别加上四个进阶题子类)中,每个领域至少答对一个问题即可额外获得一分。
最终,获得第一名奖励 1000 美元,第二名奖励 800 美元,第三名奖励 400 美元。其他参赛者将获得 150 美元的奖金,以鼓励他们的积极参与。
3. 「人类基准」的定义比较模糊
结果显示,这些团队通常能解决 13% 到 26% 的问题,平均为 19%。o4-mini-medium 解决了大约 22% 的竞赛问题。
然而,与具备完备知识储备的理想团队相比,当前统计的人类基准平均分可能在一定程度上被低估了。
一种解决方案是,如果八支人类队伍中有任何一支给出了正确答案,则认为该问题已正确回答。这样做可以将人类性能提升至约 35%。
但是考虑到 o4-mini-medium 是在 pass@1 的设置下进行评估的。因此人类在本次比赛中的表现可能介于这两个范围之间,大约在 20% 到 30% 之间。
然而,如果想要在通用基准上建立以人为基准的模型,还需要解决第二个问题。具体来说,竞赛题的难度分布与完整的 FrontierMath 数据集不同,如下表所示。

FrontierMath 竞赛和完整基准测试中问题的难度分布。竞赛中的 General(普通)问题是 1 或 2 级问题,而 Advanced(高级)问题则全部是 3 级。
因此,该研究将结果按难度等级划分,并根据完整基准测试的难度分布对总分进行加权。这样一来,基于每队平均值的人工基准得分将提升至约 30%,而基于「多次尝试」方法的人工基准得分将提升至约 52%。
遗憾的是,这种调整方法是否真的有效依然存疑,因为应用相同的权重意味着 o4-mini-medium 在基准测试中的得分约为 37%(而 Epoch AI 的完整基准测试评估结果为 19%)。这可能是因为相对于完整基准测试中同等级的平均问题,比赛中的 1/2 级问题相对较容易,但事后也很难进行调整。
4. 这意味着什么
AI 在 FrontierMath 上还未超越人类,但可能很快就会超越,这意味着什么?
首先,虽然我们现在知道 o4-mini-medium 的得分与人类团队相差无几(至少在当前的比赛限制下),但我们并不知道模型是如何做到的。AI 的答案是猜出来的吗?它们使用的方法与人类的方法相比如何?Epoch 表示未来会发布更多相关信息。
其次,就算人类的相关基准确实是在 30-50% 左右,Epoch AI 也同样认为 AI 很可能在今年年底前明确超越人类。
需要注意的是,由于比赛的形式,人类的表现可能被低估了。例如,如果有更多的时间,人类的表现很可能会大幅提升。o4-mini-medium 完成每道题大约需要 5-20 分钟,而人类通常需要更长的时间。
例如,参与我们赛后调查的参赛者平均在他们最喜欢的测试题上花费了大约 40 分钟的时间。
机器学习任务的相关研究也表明,人类拥有更佳的长期扩展行为 ——AI 的表现会在一段时间后停滞不前,但人类的表现却能持续提升。同样值得注意的是,FrontierMath 上的问题并非直接代表实际的数学研究。
但总的来说,Epoch AI 认为这是一条有用的人类基准,有助于将 FrontierMath 的评估置于实际情境中。
参考链接
https://epoch.ai/gradient-updates/is-ai-already-superhuman-on-frontiermath
https://x.com/EpochAIResearch/status/1926031207482953794

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com