Dify工作流调度怎么做?本文对比Dify Schedule和XXL-JOB两种方案,解决定时调度、监控报警和性能问题。
原文标题:如何管理和调度Dify工作流?
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、如果Dify部署在完全隔离的内网环境中,无法访问任何外部服务,那么如何实现Dify工作流的定时调度和监控?
3、在实际应用中,如何根据Dify工作流的复杂度和业务需求,选择合适的调度方案?例如,对于简单的数据同步任务和复杂的AI模型训练任务,选择策略会有什么不同?
原文内容

概述
Dify[1]是一款开源的大模型应用开发平台,可以通过可视化的画布拖拖拽拽快速构建AI Agent/工作流。Agent通常指能够自主决策、动态响应的智能体,比如聊天机器人、自动化客服等。工作流适合结构化、步骤明确、对输出内容和格式要求非常严谨的场景。 Dify工作流有许多场景,需要用到定时调度,比如:
-
风险监控:每分钟扫描风险数据,通过大模型分析是否有风险事件,并发出报警。
-
数据分析:每天拉取金融数据,通过大模型进行数据分析,给出投资者建议。
-
内容生成:每天帮我做工作总结,写日报。
本篇文章将介绍如何通过任务调度系统调度Dify工作流,通过任务调度系统调度LangChain脚本请看《》。
开源Dify的痛点
无定时调度和监控报警
Dify专注于做大模型应用的开发和运行平台,不支持工作流的定时调度和监控报警。
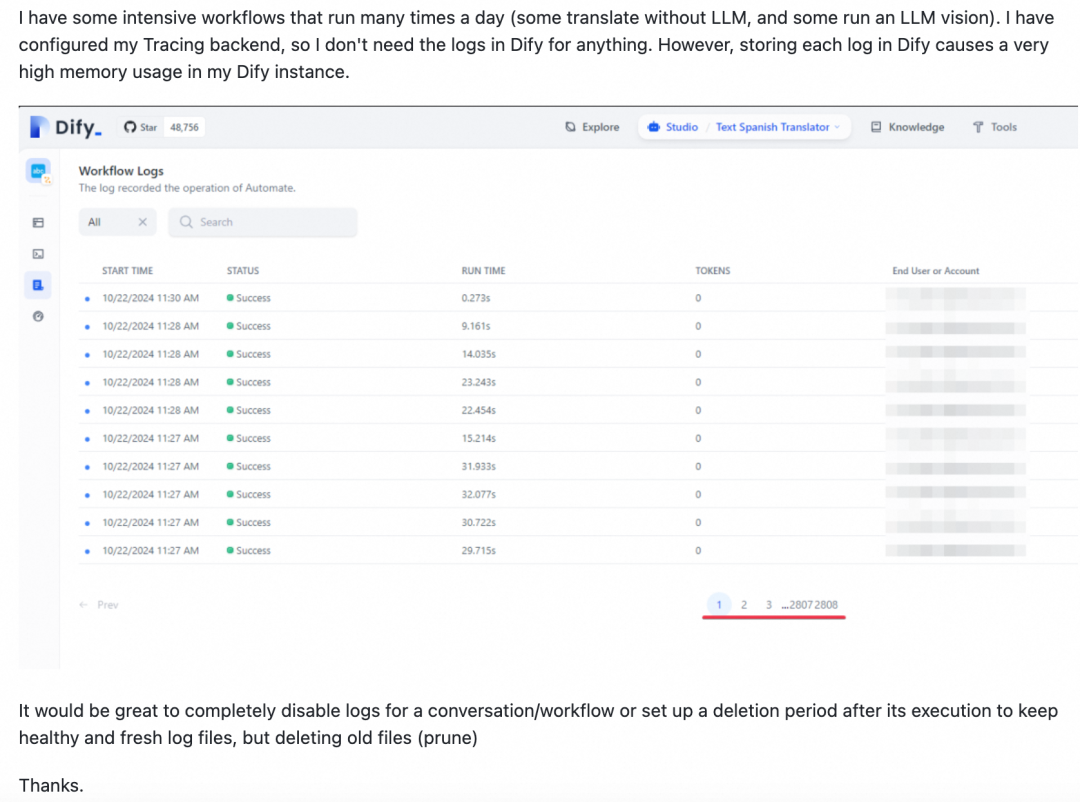
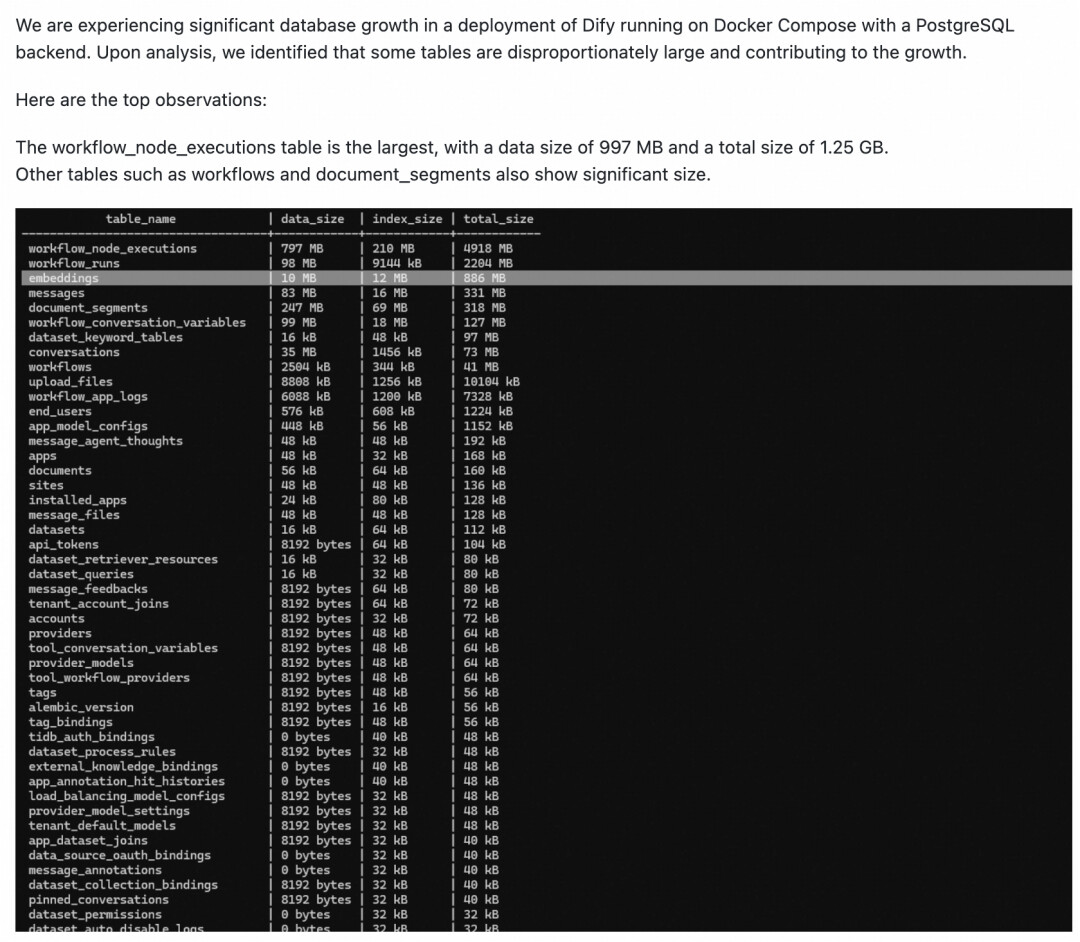
执行记录过多导致性能差
Dify工作流每次执行,会把执行记录存储在数据库的 workflow_node_executions, workflow_runs 等表,永远不会清理,会导致表数据越堆越多,影响性能。该问题社区也提了很多的 Issues,但是社区没有计划去修复该问题,比如:
解决方案
官方推荐使用任务调度系统托管和调度Dify工作流[4],做定时调度和状态监控。针对Dify侧数据库表数据过多的问题,社区没有计划做自动清理的能力,可以让运维隔断时间手动清理下该表,然后统一在任务调度系统上看执行记录。
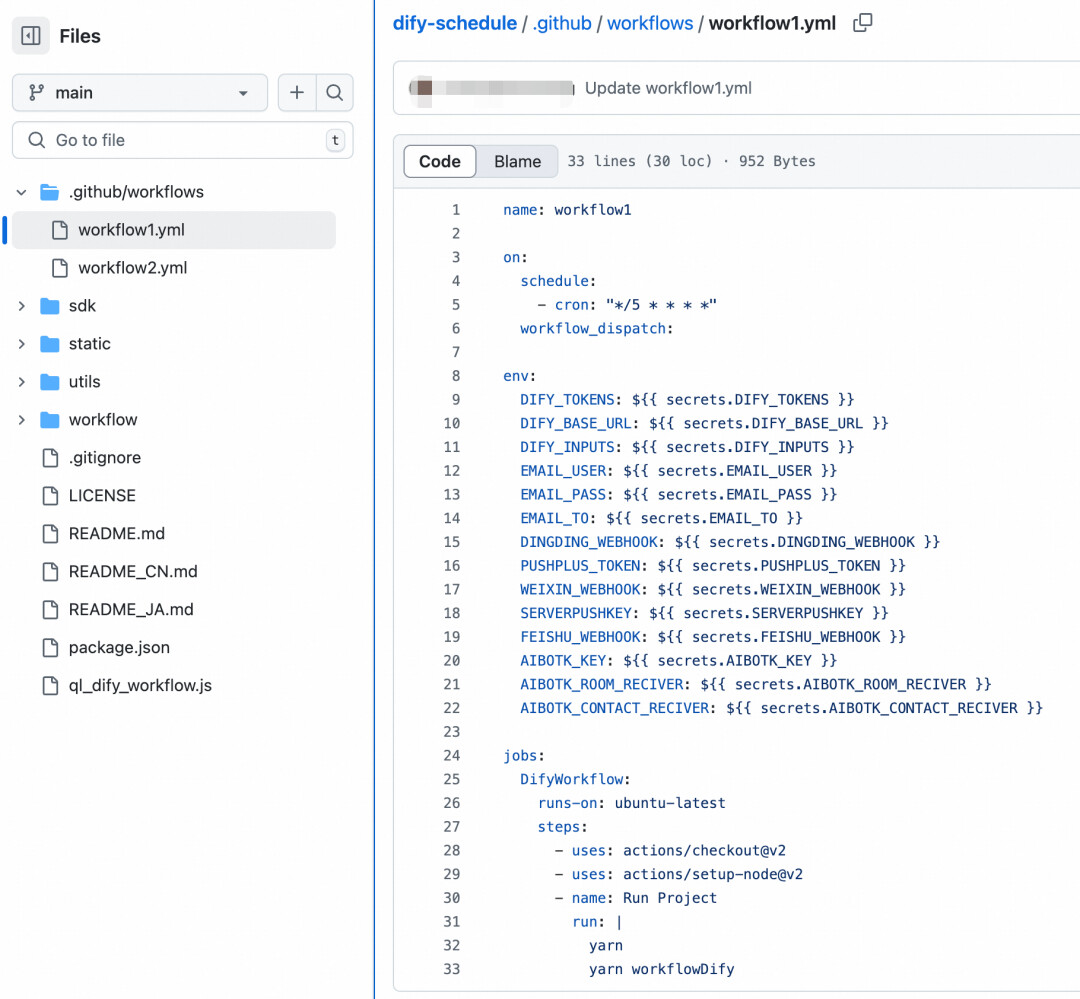
Dify Schedule集成Dify工作流
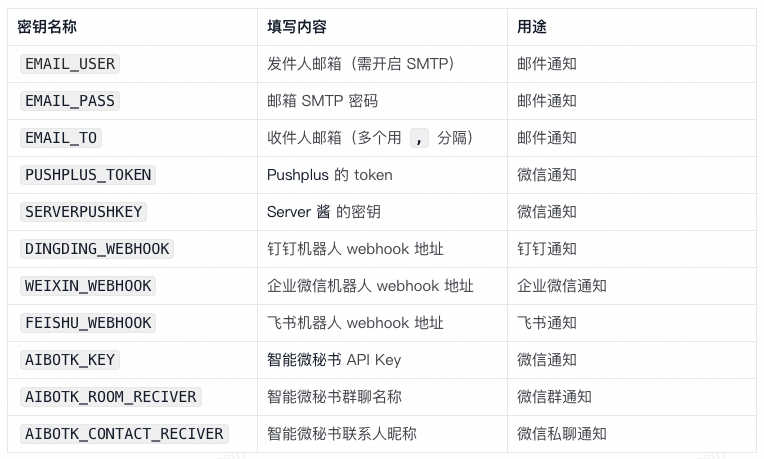
Dify Schedule [5]是一个使用 github actions [6]做Dify工作流定时调度的项目,主要包括的功能如下:
-
配置和管理Dify工作流,通过github security secrets 安全管理Dify工作流配置信息。
-
支持cron定时调度和api调度
-
多渠道消息通知:企业微信、钉钉、飞书、邮件等。
接入步骤
方案限制
只能调度公网Dify
通过github actions 调度Dify工作流,需要 DIFY_BASE_URL 这个配置成公网域名,如果是私网部署的Dify,github无法调度,网络不通。
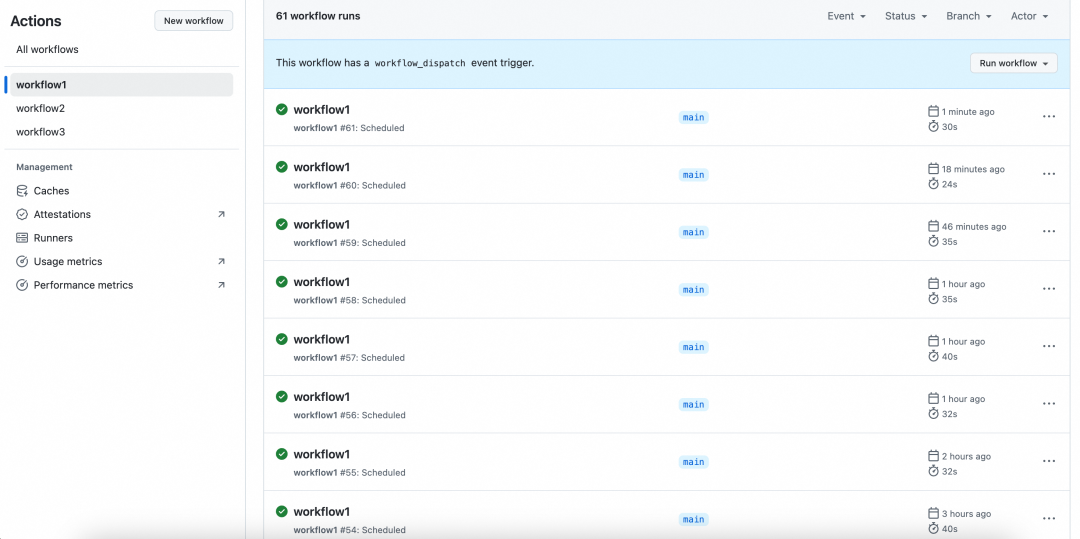
调度延时大
Github actions的schedule能力比较弱,就算把cron表达式配置成 * * * * * ,也无法做到每分钟调度一次,官方文档[7]描述最小调度频率是5分钟。
You can schedule a workflow to run at specific UTC times using POSIX cron syntax. Scheduled workflows run on the latest commit on the default or base branch. The shortest interval you can run scheduled workflows is once every 5 minutes.
经过实际测试下来,可能是github调度资源有限,就算把cron表达式配置成 "*/5 * * * *" ,也无法保证5分钟一次,调度经常会延迟十几分钟甚至好几十分钟,如果想要精确的做Dify工作流定时调度,该方案不是很合适。比如配置每5分钟调度一次,实际调度情况如下图:
配置复杂
每增加一个Dify工作流,就得配置一个github actions workflow文件,针对每个Dify工作流,还得新增 DIFY_TOKENS、DIFY_INPUTS等Secrets配置,开发维护成本比较高。
无失败报警
失败报警是定时任务系统的基本诉求,如果Dify工作流运行失败了,需要及时通知到业务方,否则容易产生故障。该方案的消息通知,是任务执行成功失败都通知,没法配置只通知失败的任务。
XXL-JOB集成Dify工作流
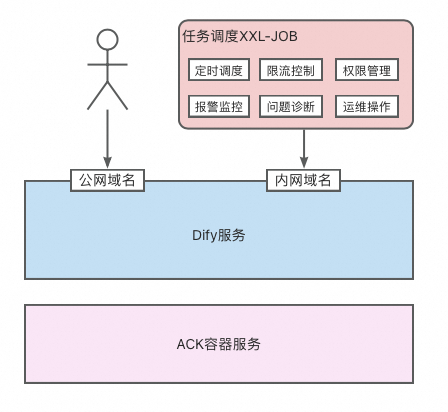
XXL-JOB[8]是开源非常流行的任务调度系统,简单易用,并且功能丰富。可以做到秒级别调度,提供任务的报警监控、手动运维、监控大盘等能力。
阿里云XXL-JOB版完全兼容开源,支持调度公网的Dify集群,也支持调度阿里云内网的Dify集群,下面以调度阿里云内网Dify详细介绍。
接入步骤
-
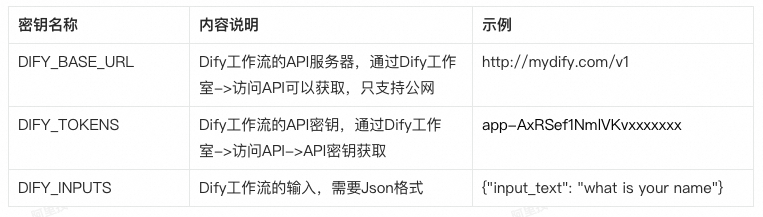
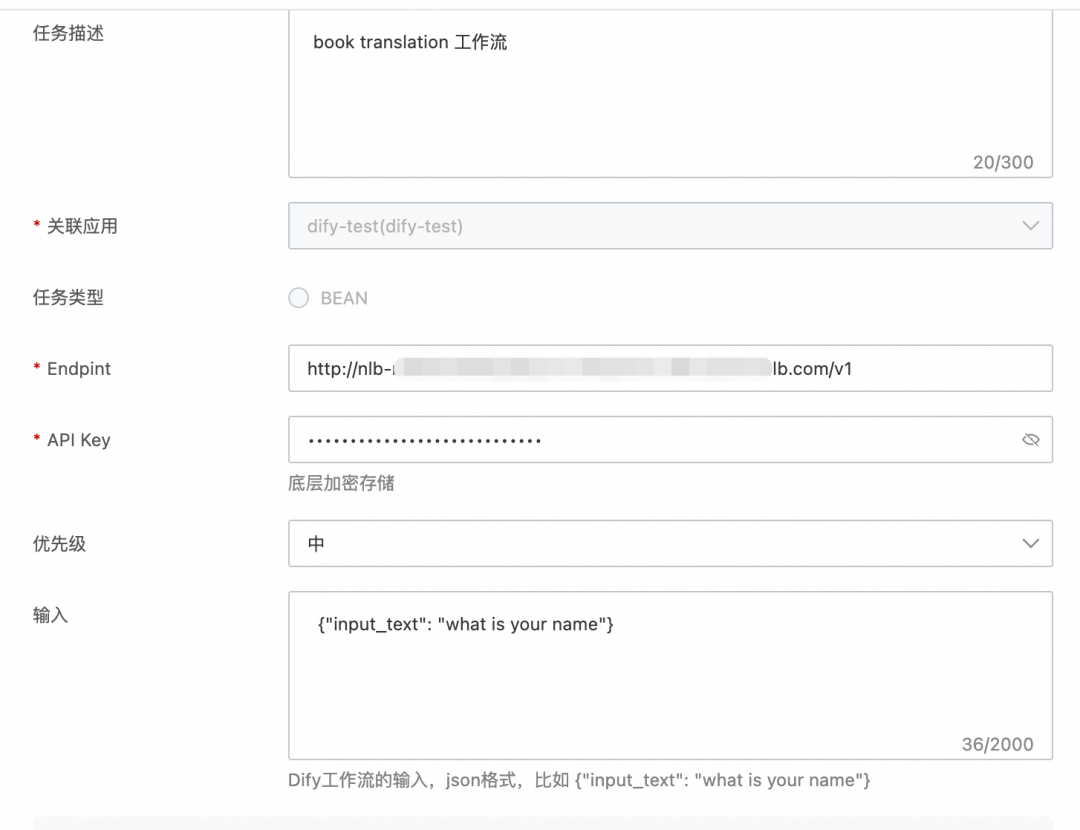
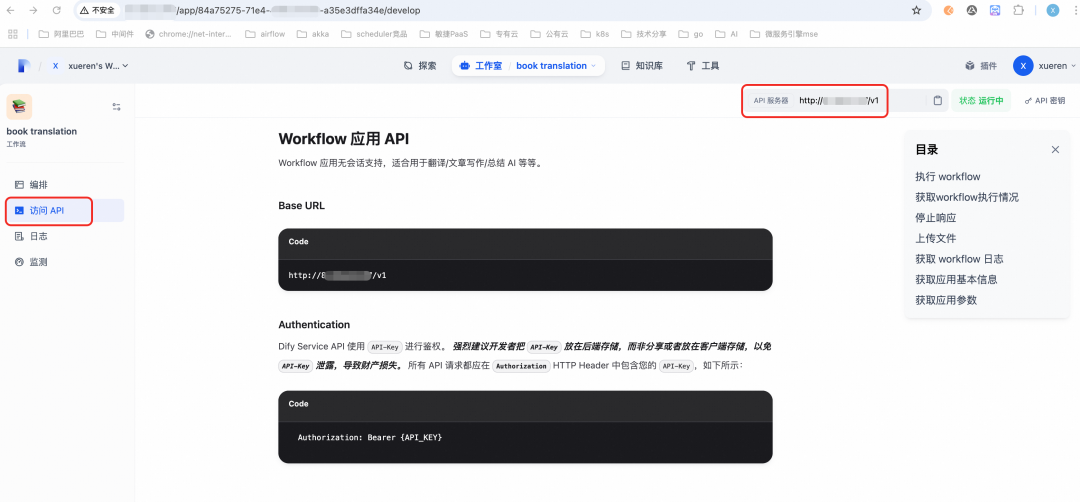
Endpoint:Dify工作流的API服务器,如果是阿里云自建Dify,推荐域名换成内网。
-
API KEY:Dify工作流的API 密钥,不同的工作流有不同的密钥,通过这里获取。
-
输入:工作流的输入,json格式,比如
{"input_text": "what is your name"}
方案优势
秒级别调度
该方案支持多种定时调度,包括cron、fixed_rate、fixed_delay,能精确到秒级别调度。同时还支持时区、自定义日历等定时配置。
安全防护
-
可以通过内网域名调度Dify工作流,不需要把Dify的API服务器暴露到公网,减少安全风险。
-
精细化权限管控:使用阿里云RAM权限体系,能支持给不同的账号、角色配置不同的权限,比如开发可以新建和编辑Dify工作流任务,运营只能读和手动运行任务。
限流控制
有一堆Dify工作流,每天运行一次或者每小时运行一次,如果把定时时间设置同一时刻,会导致调用大模型的时候触发token限流,任务执行失败。
XXL-JOB自带任务失败自动重试功能,虽然通过不断重试最终可以解决该问题,但是限流过程中一直重试会加重token限流,资源利用率不高,重复重试还会导致浪费token消耗,增加成本。所以针对该场景,推荐使用限流方案:

如上图所示,任务调度XXL-JOB版支持应用级别的限流控制:
企业级报警
任务调度XXL-JOB版集成阿里云监控,提供企业级报警服务:
-
支持联系人、联系人组统一管理。
-
支持实例和应用维度阈值报警,比如某个应用最近N分钟连续环比下跌30%。
-
支持精细化到任务级别的失败报警、超时报警、成功通知。
-
支持短信、电话、webook、邮件报警渠道。
丰富的可观测
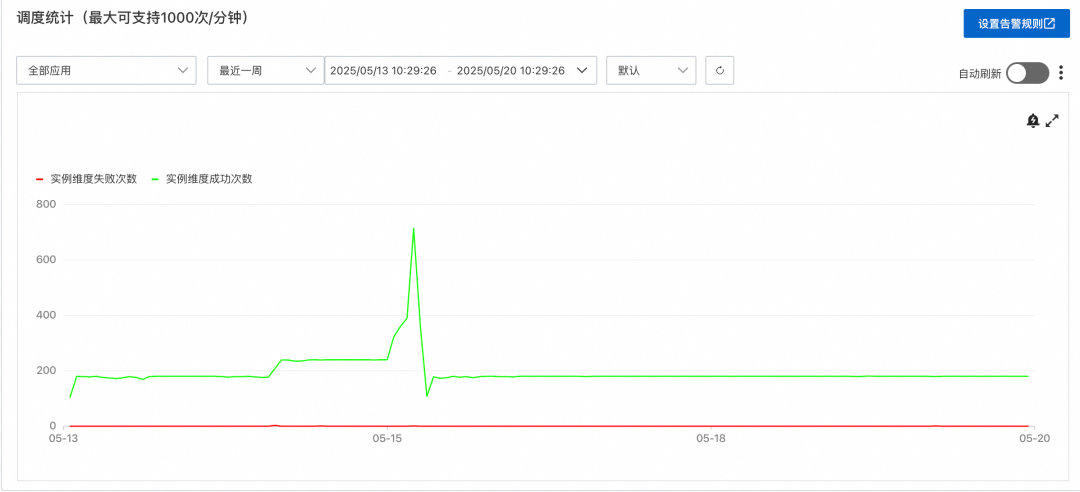
调度大盘
调度大盘通过曲线的形式展示整体调度情况,包括执行成功和执行失败,支持应用、时间区间的过滤:
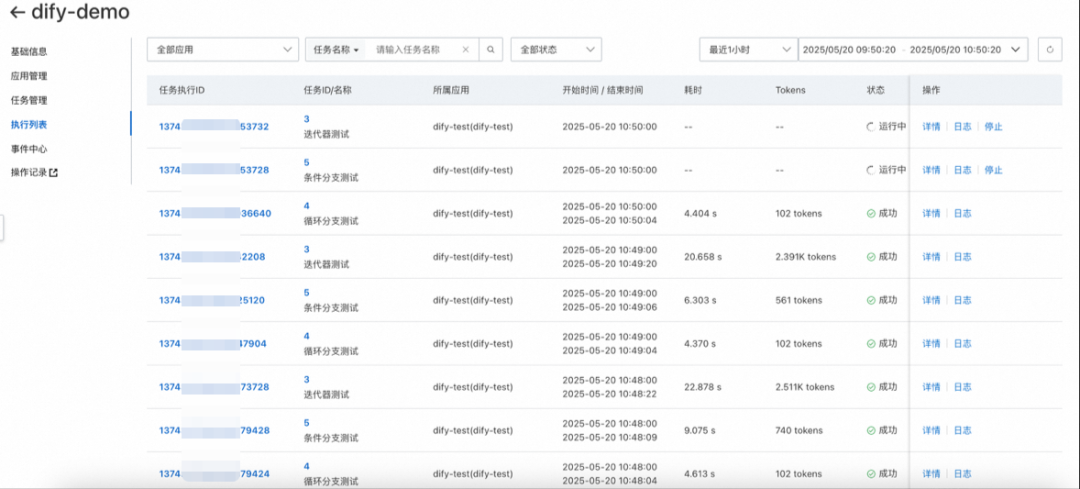
执行记录
执行记录通过列表的形式展示了每次执行的基本详情,包括Dify工作流执行的状态、耗时和tokens消耗,支持多种条件过滤查询:
工作流详情
在执行记录列表中,点详情,可以看到整个Dify工作流这次运行的详情。
-
基本信息
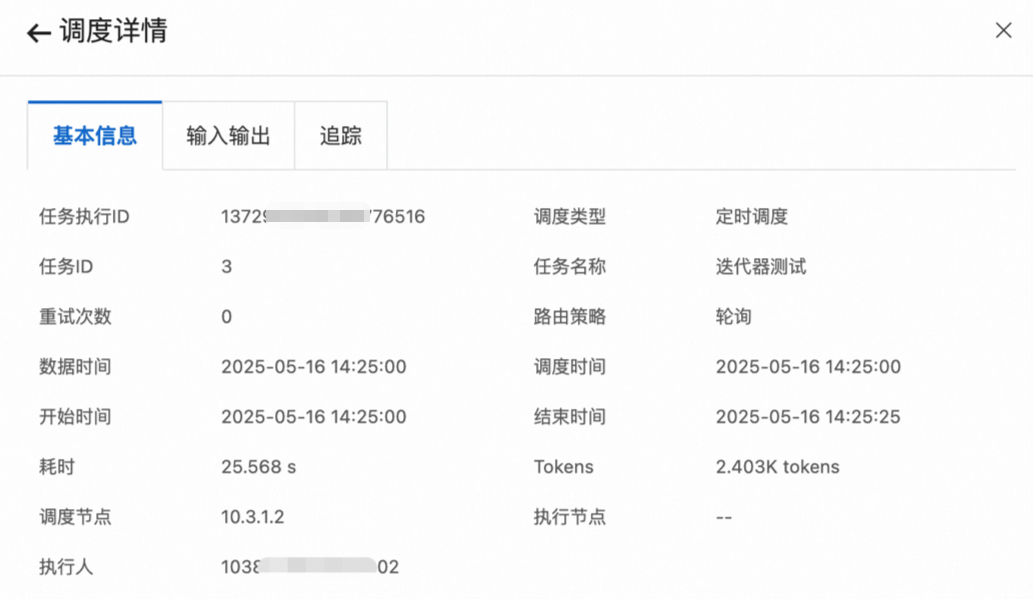
-
输入输出
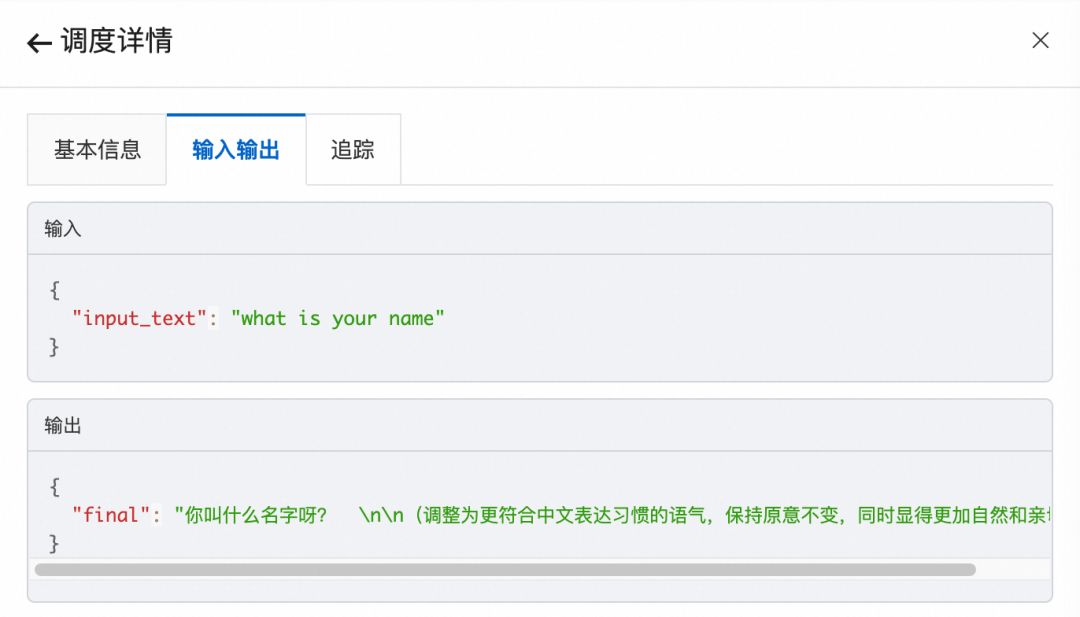
节点追踪
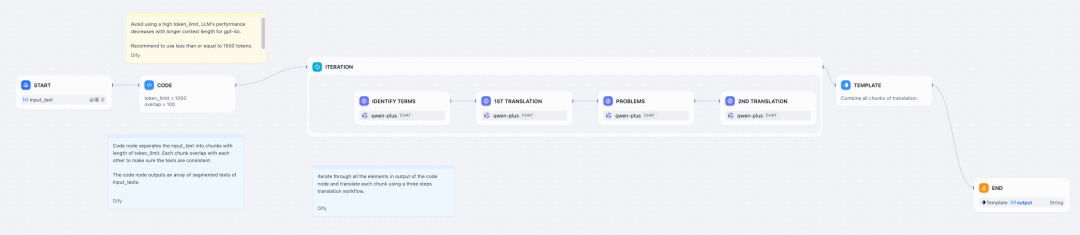
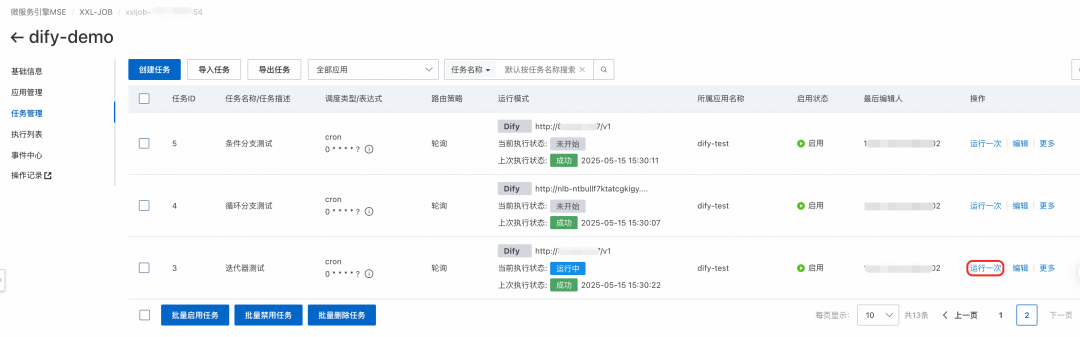
任务开始执行,MSE-XXLJOB通过streaming模式,就可以实时拿到该工作流所有节点的执行情况,如果节点是迭代器和循环分支,还能支持节点下钻,比如步骤1中包含迭代器的工作流,节点追踪如下图所示:
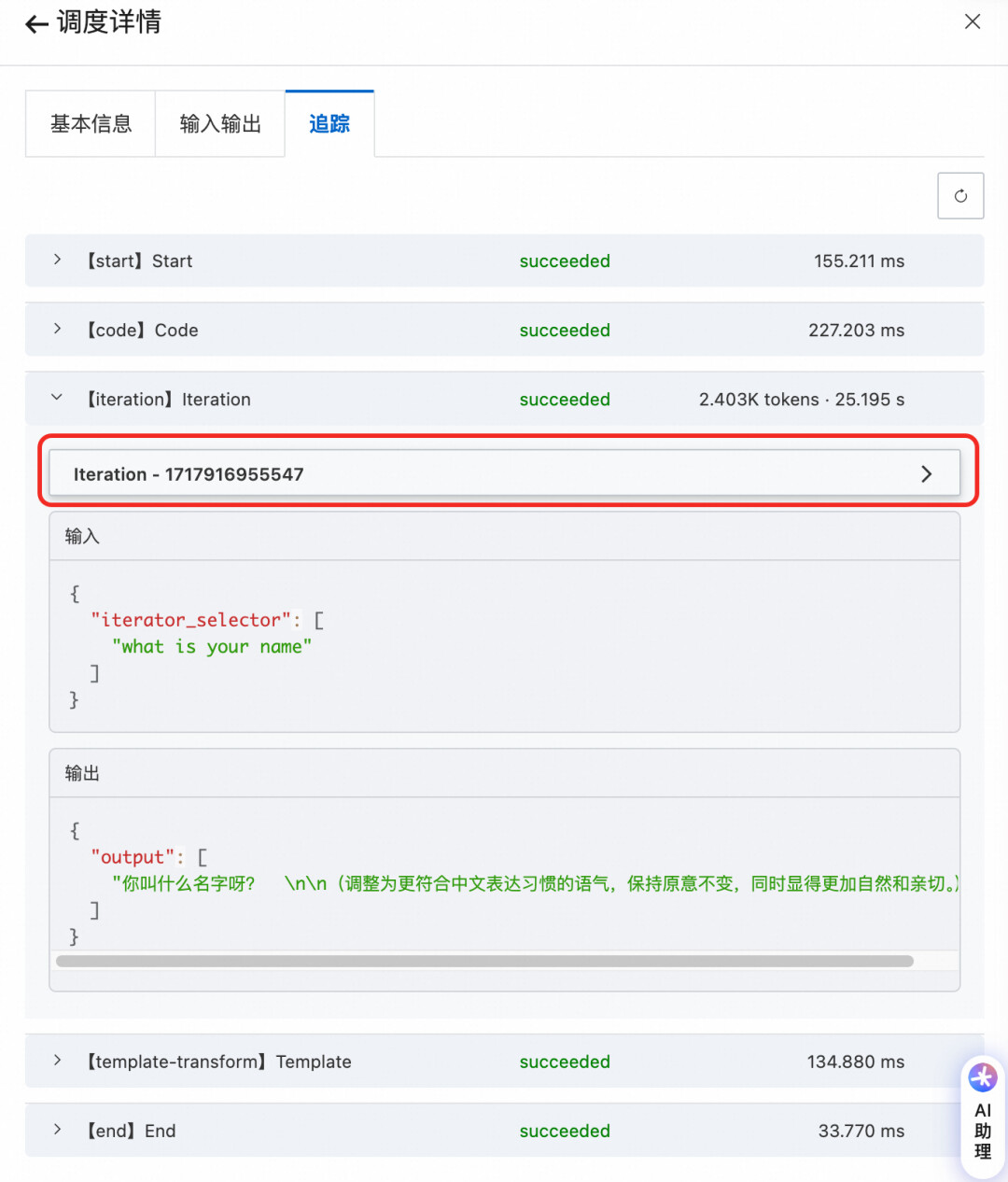
点击迭代器节点 - Iteration,可以看到子流程如下:
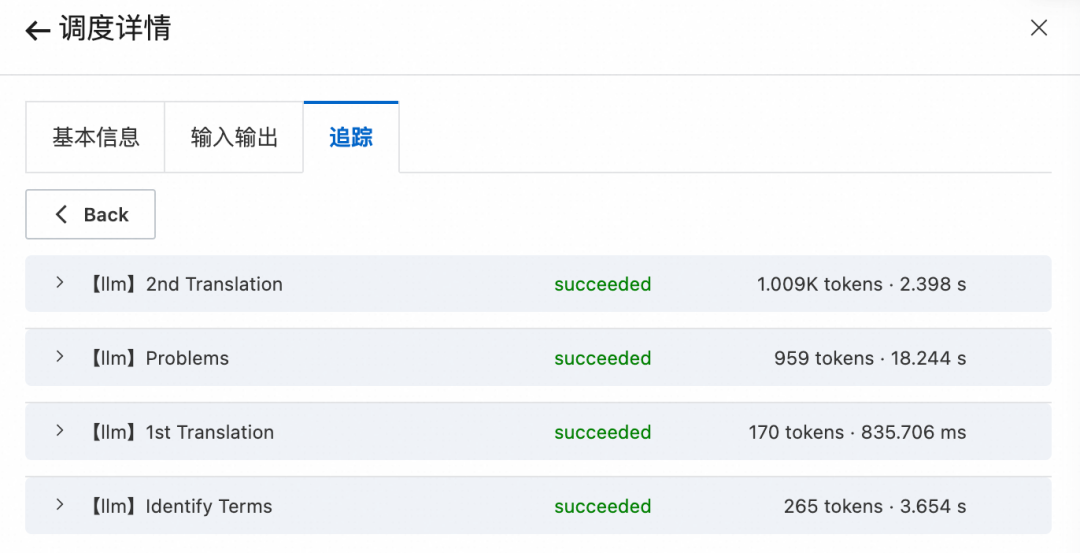
调度事件
调度事件以列表的形式展示了任务每次调度的所有事件,针对Dify工作流任务,还包括了所有工作流和节点的事件,支持按照应用、任务名、任务执行ID、时间区间过滤:

总结
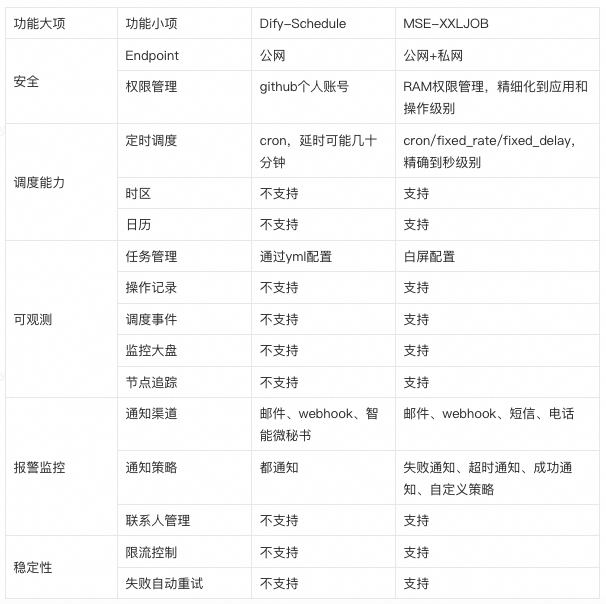
Dify-Schedule和MSE-XXLJOB,调度Dify工作流详细对比如下表:
有任何问题和需求,欢迎加钉钉群交流:23103656
云上高可用架构
从企业上云最基础的需求出发,面向可能遇到的单点故障风险,介绍了经典的“业务上云高可用架构”方案设计。
点击阅读原文查看详情。