华为发布昇腾算子优化技术,包括AMLA、融合算子和SMTurbo,通过数学创新、架构感知和硬件亲和,显著提升大模型推理性能。
原文标题:以加代乘?华为数学家出手,昇腾算子的高能设计与优化,性能提升30%!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、融合算子优化提到要消除冗余数据搬运,这个在实际操作中会遇到哪些挑战?如何保证融合后的算子依然具有良好的可维护性和可扩展性?
3、SMTurbo技术通过优化Load/Store语义来降低跨卡访存延迟,这种优化对于哪些类型的AI模型收益最大?未来在分布式训练中,这种技术还有哪些潜在的应用场景?
原文内容
机器之心编辑部
现如今,随着参数规模的指数级增长,大语言模型(LLM)的能力边界不断被打破,AI 的智力正在经历快速跃迁。但随之而来的是,大模型在落地过程中面临着一系列推理层面的难题,比如推不动、算不起、部署慢,导致推理成本高昂,性能冗余浪费严重。
因此,大模型推理的「速度」与「能效」成为所有算力厂商与算法团队绕不开的核心命题,如何让它们真正「跑得快、用得省」亟需全新的解法。这显然不仅仅是工程挑战,更要在承接大模型推理压力的同时,在能效、延迟、成本等多方面实现可控与优化。
在这一背景下,华为团队和昨天一样(参考:),用数学补物理,给出了一份深度融合软硬件的系统性方案!
他们基于昇腾算力,正式发布了三项重要的硬件亲和算子技术研究,带来了大模型推理速度与能效的双重革命。具体包括如下:
-
AMLA—— 以加代乘的高性能昇腾 MLA 算子。用「数学魔法」重构浮点运算,让昇腾芯片的算力利用率突破 70%!
-
基于昇腾的融合算子技术与设计原理。像指挥交响乐团一样调度硬件资源,让计算与通信「无缝协奏」!
-
SMTurbo—— 面向高性能原生 Load/Store 语义加速。打造内存访问的「高速公路」,跨 384 卡延迟低至亚微秒级!
可以看到,华为团队着力通过对大模型推理中关键算子的重构优化,实现能效、多卡协同和速度三大维度的全面突破。
作为 AI 大模型执行计算的「原子级工具」,算子如同乐高积木中的基础模块,负责从加减乘除到特征提取的一切核心操作。它们不仅是模型的效率引擎,更是硬件性能的放大器 —— 通过标准化设计、硬件深度适配与复用机制,让芯片处理海量数据时如虎添翼。
而华为团队此次发布的三大技术,正是算子优化的「终极形态」。
技术全景
三大黑科技如何颠覆 AI 计算?
AMLA:以加代乘的「魔法」让芯片算力利用率飙升
-
「数字炼金术」:对二进制表示重解析,将复杂乘法转换为加法运算,充分利用存内算力,算力利用率飙升至 71%!
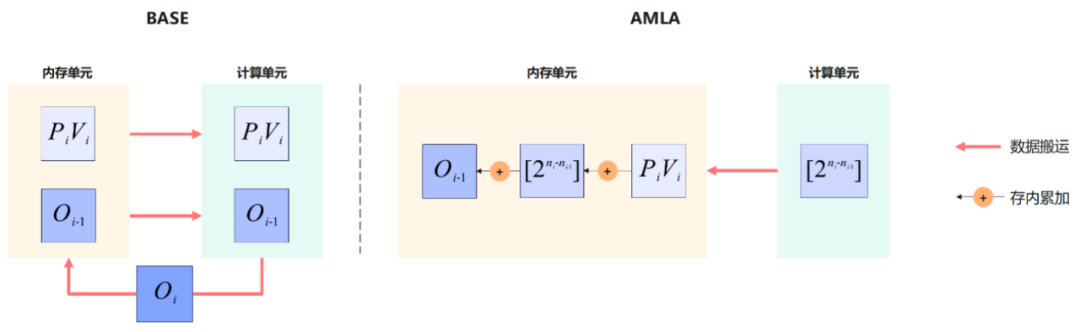
针对 Decode 阶段的 MLA 计算,华为团队提出了 AMLA(Ascend MLA)算子,通过数学等价变化和硬件亲和的深度优化,释放昇腾芯片澎湃算力。MLA 是 DeepSeek 大模型的重要技术创新点,主要就是减少推理过程的 KV Cache,实现在更少的设备上推理更长的 Context,极大地降低推理成本。FlashMLA 是该技术的高效实现版本。
针对 MLA 架构,华为团队通过精妙的数学变换,让其变得更加昇腾亲和,并做到了更高的算力利用率。
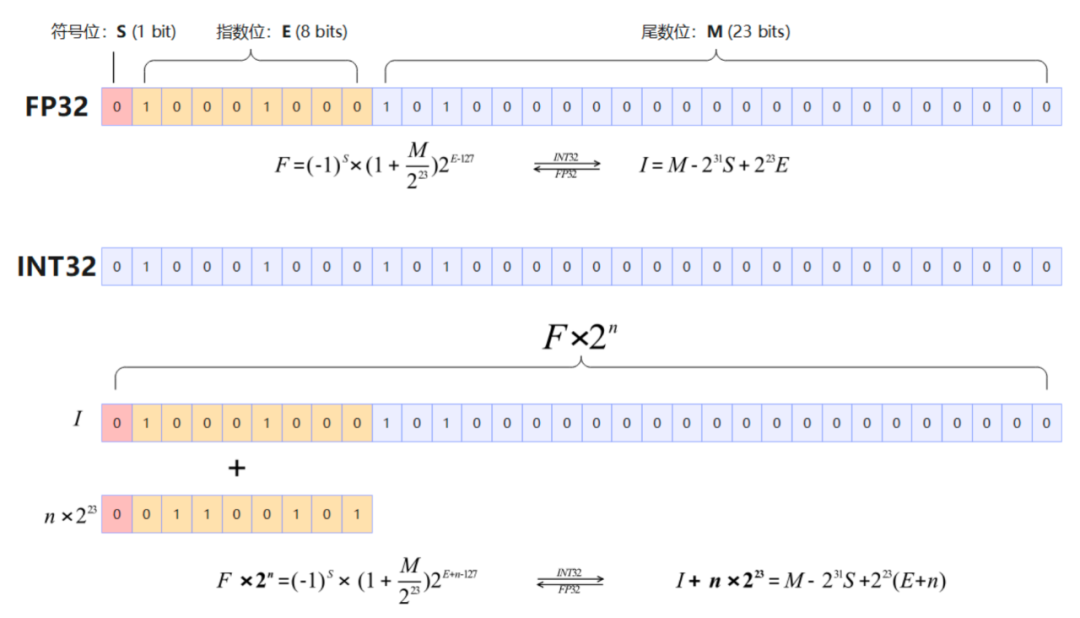
具体而言,通过对浮点数二进制编码的重解析,把复杂的乘法运算变成简单的加法操作,AMLA 实现了基于存内计算的变量更新,充分利用算力的同时减少数据搬运;结合一系列基于昇腾硬件的计算流程及流水优化手段,进一步提升算子的整体性能。
当前 AMLA 算法的 Attention 算子充分发挥昇腾硬件的计算能力,性能提升 30% 以上,平均算力利用率达到 55%,最高可达 71%,优于 FlashMLA 公开的结果(67%)。
博客链接:https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/OptimizedOps/ascend-inference-cluster-amla.md
融合算子优化:硬件资源的 「交响乐指挥家」
-
将多个算子合而为一,让计算、通信、存储「三重协奏」!
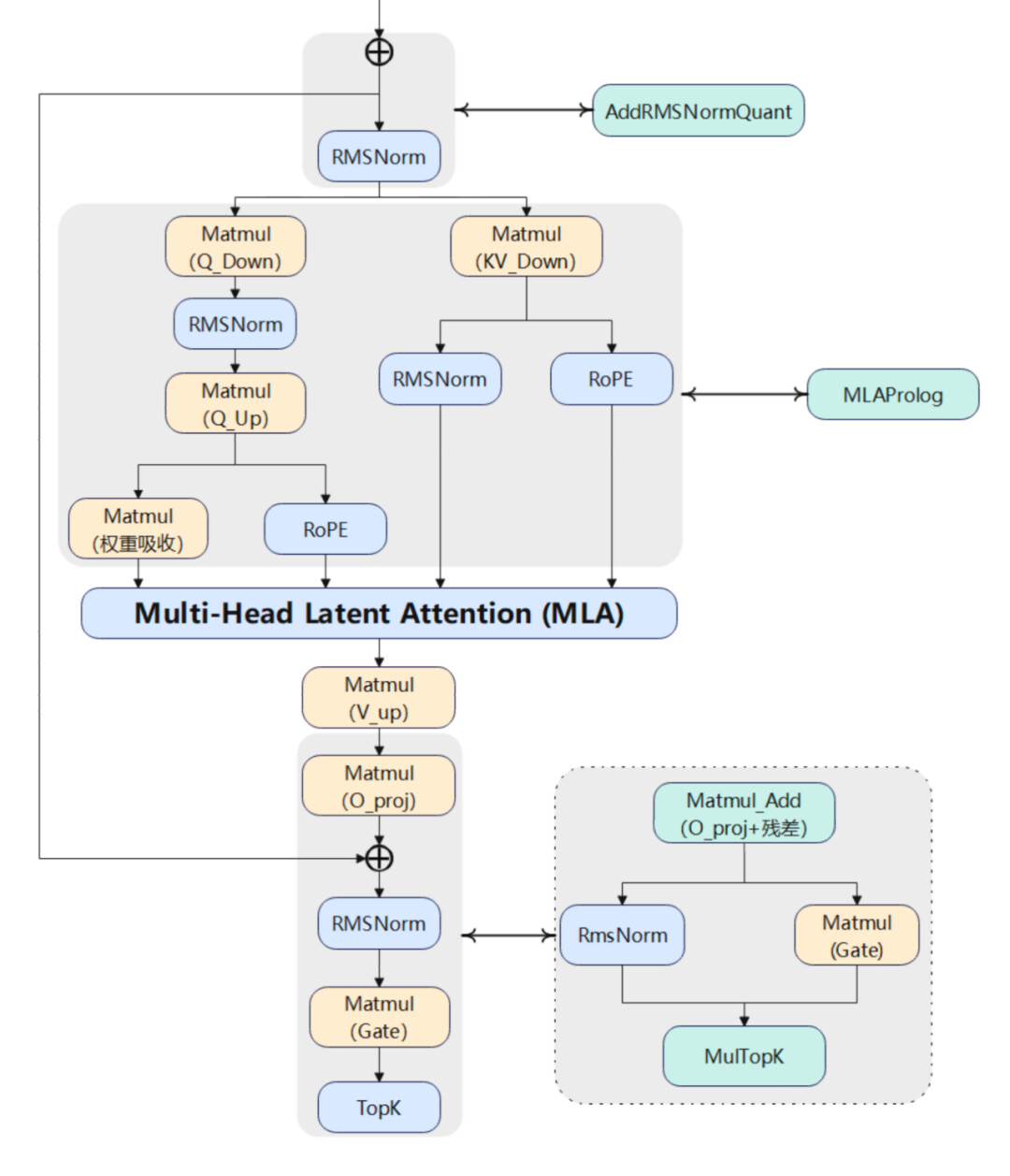
基于昇腾平台部署 DeepSeek V3/R1 大模型的实践经验,华为团队提炼出三大昇腾算子融合设计原理:硬件单元间并行度优化、冗余数据搬运消除、数学等价重构计算流。
首先,利用昇腾芯片的多硬件单元并行的能力,将跨硬件单元串行算子融合为复合算子,通过指令级流水编排实现计算耗时相互掩盖。
其次,对串行向量算子实施融合处理,构建全局内存与计算单元缓存的直通数据通道,使中间结果全程驻留高速缓存。
最后,华为团队运用数学等价关系解耦算子间数据依赖,重构计算顺序实现并行加速。该技术体系在模型推理中实现了大幅性能提升。
博客链接:https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/OptimizedOps/ascend-inference-cluster-fused-ops.md
SMTurbo:384 卡内存共享的「超低延迟高速公路」
-
昇腾原生 Load/Store 语义让跨卡访存延迟进入亚微秒时代!
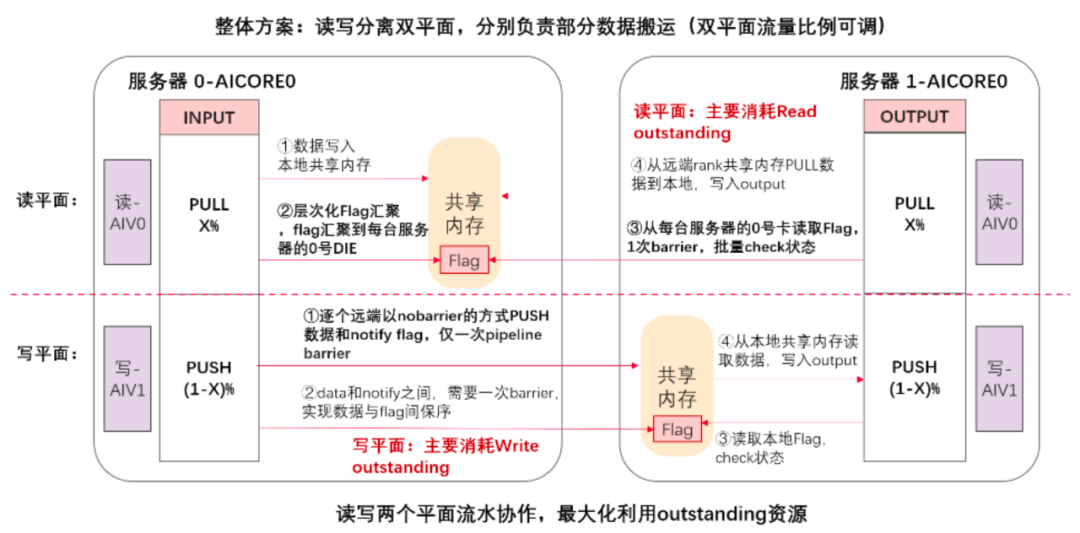
华为 CloudMatrix 384 支持 384 卡规模原生 Load/Store 语义。因其低延迟、上下文切换代价小、可细粒度流水等优势,受到业界广泛关注。基于共享内存的集合通信满足了小数据量、大范围集合通信场景需求,成为稀疏模型推理的关键能力。
面向原生 Load/Store 内存语义通信提供软硬件加速能力,ShmemTurbo Concurrent Push & Pull (SMTurbo-CPP) 将 Load/Store 在读和写两个方向上并行,发挥了昇腾芯片读写分离的微架构优势;针对数据保序场景下的同步开销问题,引入了批处理与中转机制,降低了控制逻辑的开销。在跨机访存通信场景下,方案可以提升 CloudMatrix 384 中昇腾芯片每线程的访存吞吐 20% 以上。
博客链接:https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/OptimizedOps/ascend-inference-cluster-loadstore.md
未来与展望
如上提到的三个算子层面优化技术的未来发展上,针对 AMLA,将研究仅 KV Cache 量化和全量化场景的 MLA 算子优化,进一步扩展算子应用场景;针对融合算子优化,将进一步探索融合算子在更多模型架构上的应用,推动大语言模型在昇腾硬件上的高效推理与广泛应用;针对 Load/Store 的优化技术,将结合业务设计精巧的流水实现,平衡读写平面的负载分担,将该思想引入 Deepseek dispatch 与 combine 场景,在大 BatchSize 下取得实际收益。
面向未来,这三类算子层面的优化技术不仅将在昇腾生态中发挥关键价值,也有望为整个行业提供一个参考性范本。在大模型架构日趋复杂、推理场景更加多样化的当下,算子层的优化正从单一性能突破迈向「数学创新、架构感知、硬件亲和」协同演进的全新阶段。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com