字节跳动&清华开源ChatTS,原生支持时序数据对话与推理。通过合成数据训练,有效提升模型在时序属性识别与推理上的性能。
原文标题:字节跳动&清华大学开源多模态时序大模型ChatTS,可实现时序数据对话与推理
原文作者:机器之心
冷月清谈:
怜星夜思:
2、ChatTS 采用了“数值保值归一化机制”,这种机制在实际应用中解决了哪些问题?对于不同量纲和分布的时间序列数据,还有哪些更有效的数据预处理方法?
3、ChatTS 目前主要聚焦在时序分析的理解与推理任务,如果将其与外部知识库、专家规则结合,在实际应用中可以解决哪些更复杂的问题?
原文内容

该工作由字节跳动 ByteBrain 团队 × 清华大学合作完成。第一作者为清华大学三年级博士生谢哲,主要研究方向为时序多模态 LLM、异常检测和根因定位。第二作者和第三作者分别为李则言和何晓,均来自字节跳动。通讯作者分别为字节跳动研究科学家张铁赢和清华大学计算机系副教授裴丹。
近年来,多模态大语言模型(MLLM)发展迅速,并在图像、视频、音频等领域取得了突破性成果。然而,相较于这些研究较为成熟的模态,时间序列这一类型的数据与大模型结合的系统研究却较为匮乏。
尽管已经有 TimeLLM 等工作尝试将 LLM 应用于时序任务,但这些研究大多局限于预测类任务,无法满足更复杂的理解与推理需求。随着 LLM 在 AIOps、金融等需要处理时序数据的应用场景中应用愈发广泛,时序问答、推理的能力已成为多模态智能系统的一项基础能力需求。
为此,我们提出了 ChatTS,一种原生支持多变量时序问答与推理的多模态 LLM。ChatTS 引来了 HuggingFace 产品负责人 Victor Mustar,以及 SparkNLP 项目负责人 Maziyar Panahi 等人的转发和点赞:


ChatTS 论文已经成功入选数据库顶级会议 VLDB 2025。

-
论文标题:ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning
-
论文 arXiv 链接:https://arxiv.org/pdf/2412.03104
-
ChatTS 代码和数据集:https://github.com/NetmanAIOps/ChatTS
-
模型参数:https://huggingface.co/bytedance-research/ChatTS-14B
什么是时序问答任务
传统的时间序列分析方法多基于统计模型或 AI 模型,而这些方法通常需要大量任务特定的训练、特定的数据预处理和结构化的输入输出,缺乏通用性和可解释性。而 LLM 的强语言建模能力和泛化推理能力,为「用自然语言理解时间序列」提供了可能。
然而,目前主流的 LLM 并不能直接处理原始的时间序列数组数据,现有工作要么将时间序列转成文本、图像输入,要么依赖 agent 工具进行间接分析,但都存在不同程度的限制。
因此,我们思考,是否可以构建一种「时间序列原生」的多模态 LLM,使其像处理图像一样,能够原生地理解时间序列的形状、波动与语义含义,并进行进一步的问答和推理?
构建时间序列多模态大模型面临诸多挑战
-
数据稀缺。与图文、语音等领域不同,时间序列+文本的对齐数据非常有限。
-
时间序列具有高度结构性。时序包含丰富的趋势、周期、局部波动、噪声等形态特征。
-
时间序列输入往往是多变量、不同长度的。变量之间的关系极具分析价值,但也加大了理解难度。
-
现有的评估基准未覆盖时间序列多模态建模任务,这也为训练和评估增加了难度。
现有方法
我们将现有尝试将 LLM 应用于时间序列的方式归为三类:文本化方法、图像化方法与 agent 方法。

-
文本化(Text-Based)方法最为直接,即将时间序列值编码成长文本输入 LLM。其可能存在显著的上下文长度限制,且无法处理多变量场景。
-
图像化(Vision-Based)方法借助可视化图像输入视觉大模型,但面临图像细节丢失的问题。
-
Agent 方法(Agent-Based)利用 LLM 调用工具获取特征,但该方式严重依赖工具准确性、推理链条极长且容易出现幻觉。
ChatTS: 基于合成数据训练的时序多模态 LLM
面对时间序列与语言对齐数据的极度匮乏问题,我们从根本上摒弃了依赖真实数据标注的路径,而是选择「纯合成驱动」的方式,设计出一个端到端的数据生成、模型训练框架。
一、属性驱动(Attribute-Based)的时间序列生成

我们定义了一套详细的时间序列属性体系,这些属性具有明确的语义与参数,构成了「属性池」。每个时间序列由若干属性组合生成,并对应一段高质量自然语言描述。这种组合方式不仅确保了生成时间序列的多样性与真实性,还能精确对应语言文本的细节表达,避免了传统「图文描述不符」的问题。
二、Time Series Evol-Instruct
仅有静态属性描述还不够,我们还需训练模型掌握复杂的提问、比较与推理能力。我们提出 TSEvol,该方法以一组基础 Q&A 为种子,依托已有 attribute pools,不断演化出多种新问题形式,优化复杂推理场景下的模型能力。
三、原生多模态模型设计

模型结构方面,我们基于 Qwen2.5-14B-Instruct,设计了一个时间序列原生感知的输入结构。时间序列被切分为小 patch,并用轻量级 MLP 编码,嵌入到原始文本上下文中。
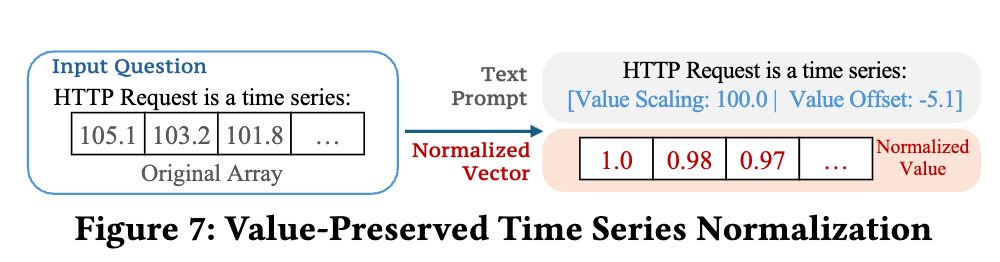
与之配套,我们设计了「数值保值归一化机制」。考虑到原始数值在实际业务中非常重要(如最大 CPU 使用率),我们在对序列进行 0-1 归一化时,同时将归一化参数以文本形式保留进 prompt,使模型既能学习序列形态,又不丢失绝对数值的意义。
ChatTS 案例展示

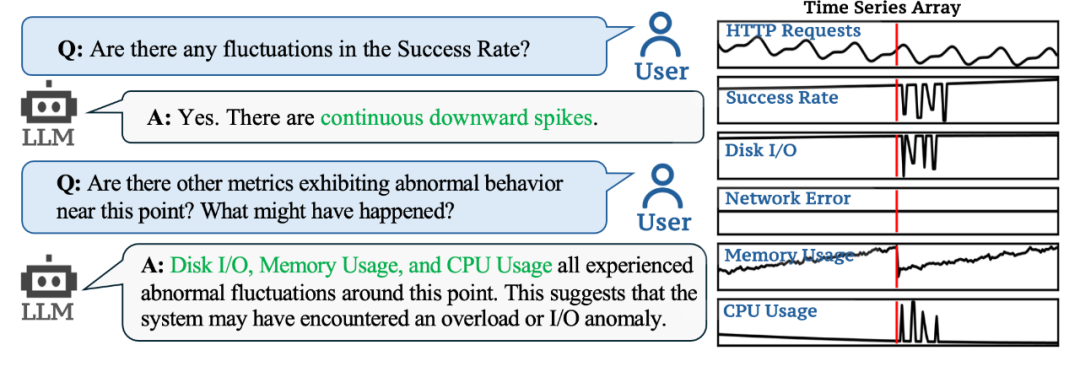
我们做了几个基于真实时间序列的 Case Studies。可以发现,ChatTS 不仅能对多变量时序的形态进行分析,还能输出时序中波动区间的位置与幅度。ChatTS 还能够对没有见过的时序波动模式进行识别,并基于自己的理解给它「起名字」。
此外,ChatTS 的使用场景非常灵活,无需精确的 prompt 输入也能准确响应。例如,我们让它分析时序中的所有「事件」,ChatTS 准确地 get 到了我们的意思,并自动提取出时序中的所有的异常波动。此外,ChatTS 还能实际应用结合,例如结合专家知识,对故障去进行初步的诊断和分析。
评估体系

我们一共收集了 3 个数据集用于评估,包含了 real-world 与合成的时序数据,评测集覆盖了对齐任务与推理任务两大类,共 12 子类的问题类型,以全面评估对比模型性能。
一、对齐任务评估:全方位精准识别时间序列属性

我们将 ChatTS 模型与基于 Text、Vision 和 Agent 的模型进行对比。结果显示,ChatTS 在所有指标上均大幅超越 GPT-4o 及其他基线方法,分类任务 F1 提升 46%–75%,数值任务相对准确率提升超过 80%。
在多变量任务上,ChatTS 优势更为显著:ChatTS 能一次性感知多个变量间的变化趋势与关系,且 token 成本极低,显示出极强的实用性与高效性。
二、推理任务评估:从归纳到因果,全面提升时序理解深度

推理任务包括四类:归纳、演绎、因果、比较。实验结果显示,ChatTS 在所有推理任务上均优于基线,平均提升 25.8%。
思考与展望
ChatTS 展示了一个全新的范式:通过可控合成数据,训练具备真实理解能力的多模态大模型。我们从零出发,仅使用合成数据训练出了一个在真实任务中表现优异的模型,这说明「数据生成 + 模态对齐」的范式具备高度潜力。
当前,ChatTS 聚焦在时序分析的理解与推理任务,未来我们可以拓展其能力至更高阶任务(例如因果推理、根因分析),甚至结合外部知识库、专家规则,实现更强的决策支持能力。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com