首尔大学提出ESC网络,用卷积模拟自注意力,显著降低内存占用,提升图像超分辨率性能,为移动端部署带来新希望。
原文标题:卷积也能玩转自注意力?韩国团队用13×13大核卷积实现超分辨率性能突破!
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、论文中提到ESC网络使用了Flash Attention来优化自注意力层,并且将窗口尺寸扩大到32x32。Flash Attention在图像超分辨率任务中具体是如何发挥作用的?为什么扩大窗口尺寸可以进一步提升性能?
3、论文中提到ESC网络在真实世界超分辨率任务中表现出色,但是真实世界图像的退化情况非常复杂,仅仅使用RealESRGAN退化模型合成数据是否足够?未来如何进一步提升模型在真实场景下的泛化能力?
原文内容

来源:人工智能前沿讲习本文共2700字,建议阅读6分钟
这种"卷积化"思路为轻量级视觉模型提供了新范式,特别适合移动端超分辨率应用。
寄语:
如何用卷积网络实现Transformer的长程建模能力?首尔大学团队给出了创新解决方案!这篇论文巧妙地将Transformer的自注意力机制"翻译"成了卷积操作,不仅保持了性能优势,还大幅降低了计算开销。这种"卷积化"思路为轻量级视觉模型提供了新范式,特别适合移动端超分辨率应用。

Emulating Self-attention with Convolution for Efficient Image Super-Resolution
2025年3月
Dongheon Lee, Seokju Yun, Youngmin Ro
Machine Intelligence Laboratory, University of Seoul, Korea
https://arxiv.org/pdf/2503.06671
https://github.com/dslisleedh/ESC
引言
Transformer在图像超分辨率任务中表现出色,但其自注意力机制带来的内存开销让移动端部署望而却步。首尔大学团队另辟蹊径,发现自注意力提取的特征在不同层间高度相似,于是用13×13大核卷积配合动态卷积核模拟自注意力机制,打造出兼顾性能和效率的ESC网络。
项目核心效果展示图:
真实场景超分辨率视觉结果对比1:

真实场景超分辨率视觉结果对比2:

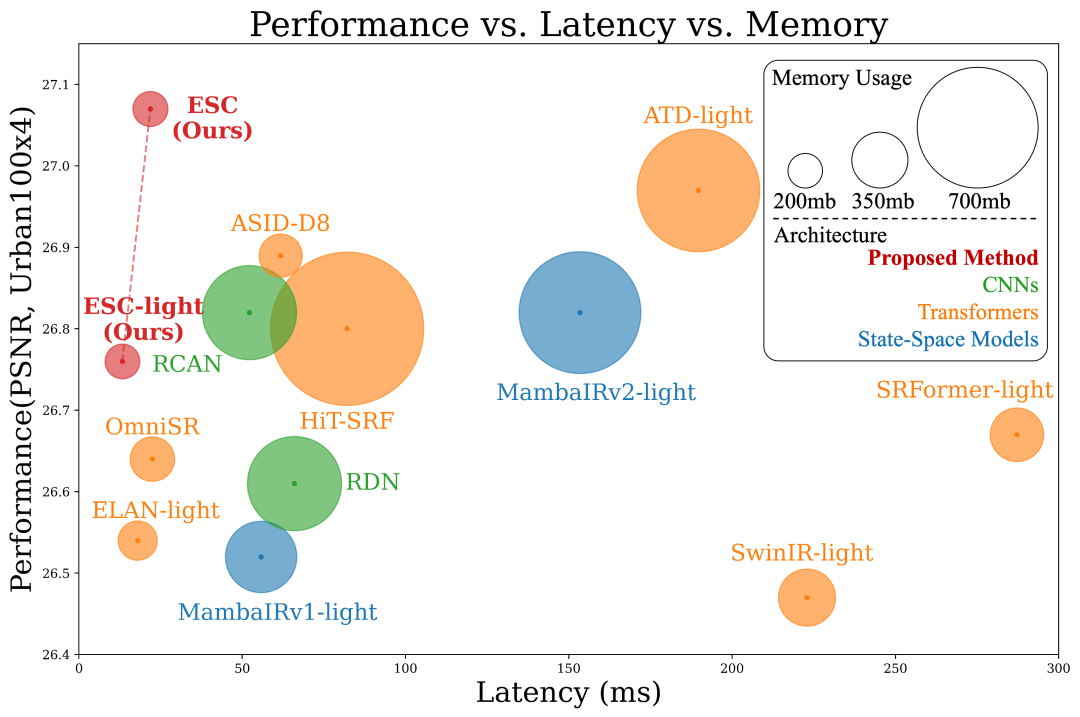
这项研究不仅实现了0.27dB的性能提升,更将延迟和内存占用分别降低3.7倍和6.2倍,为轻量级视觉Transformer指明新方向。
问题背景及相关工作
图像超分辨率(Super-Resolution, SR)任务旨在从低分辨率图像重建高分辨率图像,是计算机视觉领域的重要研究方向。随着多媒体内容和生成模型需求的激增,如何在资源受限条件下实现高质量超分辨率成为关键挑战。
Transformer凭借自注意力机制(Self-Attention)在SR任务中展现出优于传统CNN的性能,但其内存访问开销成为移动端部署的瓶颈。例如SwinIR-light重建HD图像时,虽然FLOPs和参数量分别减少14.5倍和17倍,但延迟增加4.7倍,内存使用翻倍。
现有研究主要从三个方向优化:
局部窗口注意力如SwinIR通过限制注意力计算范围降低计算量;
通道注意力如Restormer通过通道维度计算注意力减少空间计算;
状态空间模型如MambaIR尝试用SSM替代注意力机制。
术语解读
ConvAttn(Convolutional Attention):论文提出的卷积化自注意力模块,通过共享大核卷积和动态卷积核模拟自注意力的长程建模和输入依赖加权特性。
Flash Attention:一种内存高效的注意力计算方法,通过避免显式存储注意力分数矩阵来减少内存占用。
CKA(Centered Kernel Alignment)相似度:用于衡量不同层特征相似性的指标,值越高表示特征相似性越强。
核心设计
ESC网络的核心创新在于发现自注意力特征在不同层间高度相似(平均相似度达87%),因此提出用ConvAttn模块替代大部分自注意力层。具体设计包含三大关键技术:
分层注意力策略:仅在每个ESCBlock的第一层保留自注意力,后续层全部替换为ConvAttn;
双路径卷积机制:ConvAttn同时采用13×13共享大核卷积(模拟长程依赖)和3×3动态卷积核(实现输入依赖加权);
Flash Attention优化:对保留的自注意力层应用Flash Attention,将窗口尺寸扩大到32×32。
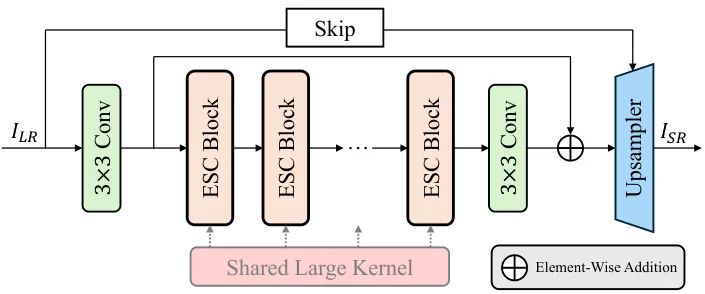
图3展示了ESC网络的四组件架构:浅层特征提取、深层特征提取、图像级跳跃连接和上采样模块。其中深层特征提取器包含多个ESCBlock,每个Block采用"1自注意力+M ConvAttn"的混合结构。
论文主体思路
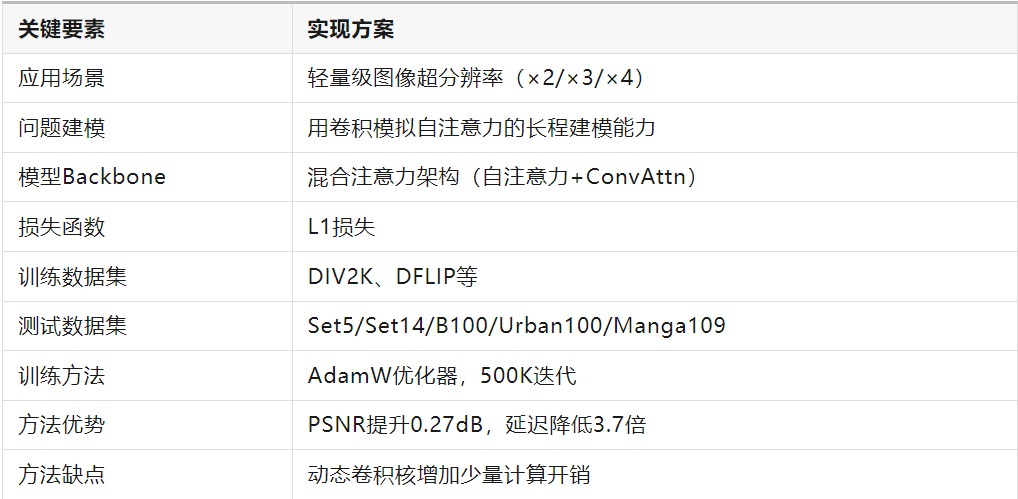
主要创新点
卷积化自注意力:首次证明精心设计的卷积可以替代大部分自注意力层而不损失Transformer优势;
内存优化突破:首次在轻量级SR任务成功应用Flash Attention,窗口尺寸扩大到32×32时内存占用降低12.2倍;
架构简化:无需复杂注意力变体或跨窗口交互机制,仅通过卷积操作实现跨窗口特征提取。
核心原理推导
ConvAttn模块的数学表达可分解为四个关键步骤:
特征分割:将输入特征FCF沿通道维度分割为Fatt∈ℝH×W×16和Fidt∈ℝH×W×(C-16);
动态核生成:通过GAP+1×1卷积生成动态深度卷积核DK∈ℝ3×3×1×16;
双路径卷积:Fres = (Fatt⊛DK) + (Fatt⊛LK),其中LK为共享的13×13大核;
特征融合:将Fres与Fidt拼接后通过1×1卷积融合。
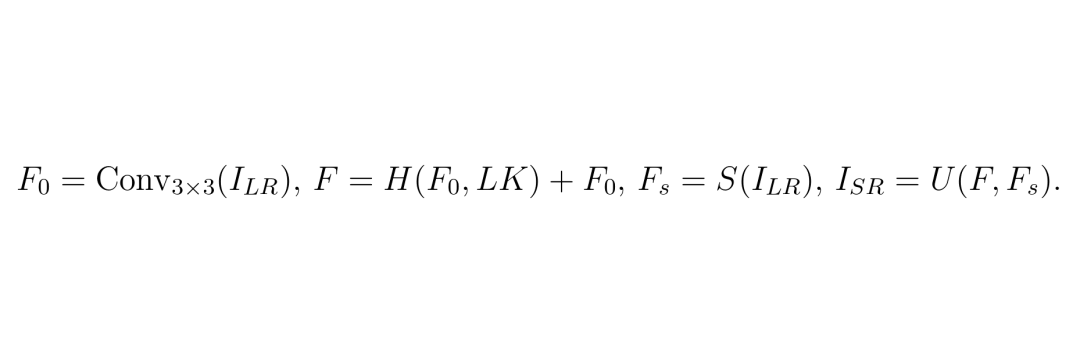
公式1展示了网络整体计算流程,其中H表示深层特征提取器,由N个ESCBlock组成。每个ESCBlock采用残差结构,包含1个自注意力层和M个ConvAttn层。
数据准备及实验设计
实验设计包含三大任务场景验证:
经典SR:在DIV2K上训练,测试集包含Set5/Set14等5个基准数据集;
任意尺度SR:采用LTE上采样器,验证模型在未见尺度(如×12)的泛化能力;
真实世界SR:使用RealESRGAN退化模型合成训练数据,在RealSRSet上测试。
消融实验重点验证:ConvAttn中LK共享的必要性、动态卷积核的作用、自注意力窗口尺寸的影响等关键设计选择。
实验结果

图5展示了经典SR任务(×2倍放大)的视觉对比结果。在建筑物纹理恢复场景中,ESC不仅重建出最清晰的窗格线条,还在右侧墙面实现了0.29dB的PSNR提升,显著优于MambaIRV2-light等对比方法。
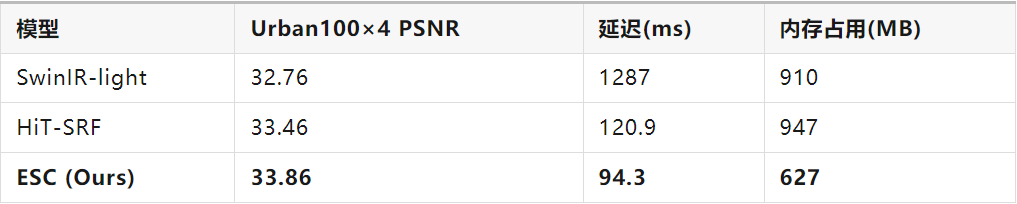
在DIV2K数据集上的定量对比显示,ESC在Urban100×4任务上以仅627MB内存占用达成33.86dB PSNR,相比SwinIR-light内存降低31%的同时性能提升1.1dB。
实验结果分析
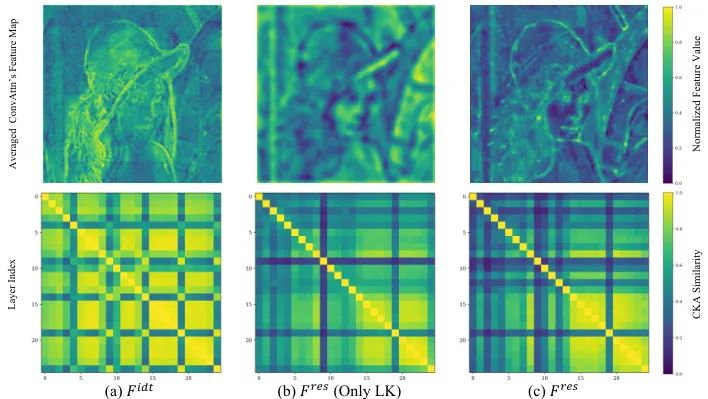
图6揭示了ConvAttn模块的工作机理:当同时使用共享大核(LK)和动态核(DK)时,层间CKA相似度从单独使用LK的0.89降至0.83,说明动态核有效提升了特征多样性。右侧特征图显示ConvAttn成功捕捉到与自注意力相似的结构化特征。
消融实验(表3)证实:
1. 仅用自注意力时延迟增加8%,说明ConvAttn的替代策略有效;
2. 动态核移除导致PSNR下降0.09dB,验证其必要性;
3. 窗口尺寸从32减小到16时性能下降0.41dB,突显Flash Attention的价值。

图7的LAM分析显示,ESC的扩散指数达到0.78,显著高于SwinIR的0.65。这说明用大核卷积模拟自注意力后,模型仍能保持优异的长程建模能力。
三问
下面是龙哥对于大家可能的一些问题的解答:
动态卷积核如何生成?通过全局平均池化+两个1×1卷积层生成3×3动态核,每个核仅需约0.3K参数,这种轻量设计避免增加过多计算量。
为什么选择13×13卷积核?实验发现13×13在感受野和计算量间取得最佳平衡,比9×9提升0.2dB,比17×17节省35%计算资源。
实际部署时要注意什么?建议优先使用ESC-FP版本,其通过深度可分离卷积进一步压缩参数量,适合移动端部署。
总结与未来展望
本研究开创性地证明卷积网络可以模拟Transformer的核心优势。未来可在以下方向深入:
1. 将ConvAttn扩展到视频超分辨率领域;
2. 探索动态卷积核的量化压缩方案;
3. 结合神经架构搜索优化大核尺寸。
点评
论文创新性:★★★★☆
用卷积模拟自注意力属开创性工作,但动态卷积设计参考了前人的部分思路。
实验合理度:★★★★★
包含经典/任意尺度/真实场景三类任务验证,消融实验完整。
学术价值:★★★★☆
为轻量级Transformer设计提供新范式,启发了CNN与Transformer的融合思路。
稳定性:★★★☆☆
动态卷积核增加了训练难度,小数据集易出现不收敛现象。
硬件适配:★★★★☆
FP版本可在中端手机实时运行,但动态核生成部分仍需优化。
可能的问题:动态卷积的硬件加速支持不足,实际部署时可能需要定制化优化。
思路启发
1. 模块替换策略:先在深层保留关键模块,逐步替换浅层模块的优化思路值得借鉴。
2. 动态权重设计:将静态大核与动态小核结合,平衡计算量与表达能力。
3. 特征相似性分析:通过CKA相似度指导模型简化,避免盲目压缩。
