华为昇腾FlashComm通过优化通信和并行策略,显著提升大模型推理速度,最高提速80%,为MoE模型推理带来新突破。
原文标题:帮大模型提速80%,华为拿出昇腾推理杀手锏FlashComm,三招搞定通算瓶颈
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到的FlashComm技术主要针对MoE模型,那么对于非MoE模型,这些优化思路是否还有借鉴意义?又该如何应用?
3、华为昇腾在FlashComm中扮演了什么样的角色?除了FlashComm,昇腾还在哪些方面为大模型推理提供了支持?
原文内容
机器之心编辑部
在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。

近日,华为数学家出手,祭出 FlashComm,三箭齐发,解决大模型推理通算难题:
-
FlashComm1: 大模型推理中的 AllReduce 通信优化技术。将 AllReduce 基于通信原理进行拆解,并结合后续计算模块进行协同优化,推理性能提升 26%。
-
FlashComm2:大模型推理中以存换传的通信优化技术。在保持计算语义等价的前提下,实现 ReduceScatter 和 MatMul 算子的计算流程重构,整体推理速度提升 33%。
-
FlashComm3: 大模型推理中的多流并行技术。充分挖掘昇腾硬件的多流并发能力,实现 MoE 模块的高效并行推理,大模型吞吐激增 30%。
随着大语言模型(Large Language Models, LLMs)规模的指数级扩张,其部署形态也随之变化,显卡配置朝着规模化、集约化演进。从神经网络时代的单卡部署,到稠密模型时代的多卡 / 单节点部署,再到以最近发布的 DeepSeek V3/R1 模型为代表的混合专家(Mixture of Experts, MoE)模型,大语言模型甚至会采用数百卡组成的集群和超节点来部署。
可以说,模型推理早已不是「单兵作战」,而是一场高协同的「群体作战」。而在这基于集群的大模型推理中,集合通信操作就像是一群工人协作盖房子时传递材料和信息的方式,能让多个计算节点高效配合完成任务。
有一些常用集合通信操作,比如全量规约(AllReduce)可以想象成一群工人各自收集了不同区域的建筑材料数据,全量规约就是把所有工人手里的数据汇总到一个地方,进行求和、求平均值等计算。在大模型里,多个计算节点可能各自计算了一部分参数梯度,AllReduce 操作能把这些梯度汇总起来,计算出最终的梯度,用于更新模型参数。
再比如全量收集(All-Gather)则类似于所有工人把自己手头的材料清单共享给彼此,这样每个人都知道所有材料的情况。在大模型里,All-Gather 操作能让每个计算节点都获取到其他节点计算出的部分结果,将分散在各节点的数据聚合到所有节点。还有像规约散射(Reduce-Scatter)操作则相当于先把所有建筑材料按类别汇总,再重新分配给不同工人。在大模型中,Reduce-Scatter 先对数据进行规约计算,再将计算结果分散到各个节点,常用于在多个节点间分摊计算压力。也还有像 All-To-All 这样允许所有节点之间相互交换数据,让每个节点都能获取到其他节点的相关数据的操作。
这些形形色色的集合通信操作,大多用来支持在集群上运行大模型推理时的并行策略,比如常见的张量并行(TP)是把一个大的张量(可以理解为模型的参数矩阵)拆分成多个部分,分配到不同的计算节点上计算。在这个过程中,节点之间需要频繁交换数据,比如 All-to-All 操作就经常被用到,让各个节点能获取计算所需的张量片段,实现高效的并行计算。
再如数据并行(DP),其将输入数据分成多个批次,在不同节点上同时处理不同批次的数据。各节点计算完各自批次数据对应的梯度后,需要用 AllReduce 操作把这些梯度汇总起来,计算出平均梯度,再将更新后的模型参数发送给所有节点,保证各节点使用相同的模型。
而被 MoE 带火的专家并行(EP)就像工厂的流水线,不同的计算节点负责模型不同专家的计算。在这个过程中,节点之间需要传递中间计算结果,类似广播操作会把上一层的输出传递给下一层的节点,确保专家正常激活运行。
由上可以看出,集合通信操作是大模型推理中多个计算节点协作的「桥梁」,不同的并行策略(TP、DP、EP)通过这些操作实现高效的数据交互和计算,从而加速大模型的推理过程。
通信:Scaling law 头顶的乌云
随着集群规模和推理并发数的飞速增长,在大语言模型的推理中,通信面临的压力也在不断变大,在推动应用通算融合技术上还有一些问题需要解决:
1) 随着 MoE 模型规模的持续扩张,专家数量与参数总量呈指数级增长,单个模型参数突破千亿级别已成常态。尽管 MoE 通过稀疏激活机制仅调用部分专家,但海量参数的存储与调度仍对硬件构成严峻挑战。MoE 模型的稀疏计算特性虽能提升推理效率,却引入了更复杂的流程与通信瓶颈。专家路由、数据分发与结果聚合等环节紧密耦合,通信带宽需求随专家数量呈平方级增长,极易引发网络拥塞;而流程各阶段的强依赖性使得计算与通信难以重叠,硬件资源长期处于「饥饿」状态。如何实现通信与计算的深度协同成为关键难题。
2) 传统的通信方案中小并发推理场景下常用的通信策略 —— AllReduce,存在着一些缺陷:
-
AllReduce 在通信原理上, 等价于 ReduceScatter 和 AllGather 的组合。直接使用 AllReduce 算子,在通信次数上较少,适用于小并发场景。但在大并发场景下,AllReduce 算子对比拆分的 ReduceScatter 和 AllGather,收益并不明显。
-
Transformer 结构中 AllReduce 算子之后,往往会有一些其他计算操作,如 RMSNorm、以及 MLA 中的降维计算等。这些计算过程会在不同卡上执行相同的计算操作,在小并发场景下可能耗时不高,但在大并发场景下,会带来不小的代价。
3) 当前主流的并行方案是张量并行 (TP) 在应用 AllReduce 时也面临一些问题。TP 方案通过卡间均匀切分权重的方式,虽然能够有效降低每张卡上加载的模型权重大小,但卡间求和的 AllReduce 操作在大模型端到端推理时延中占比较高;在多节点的部署场景中,跨节点的带宽限制进一步加剧了整网时延劣化。
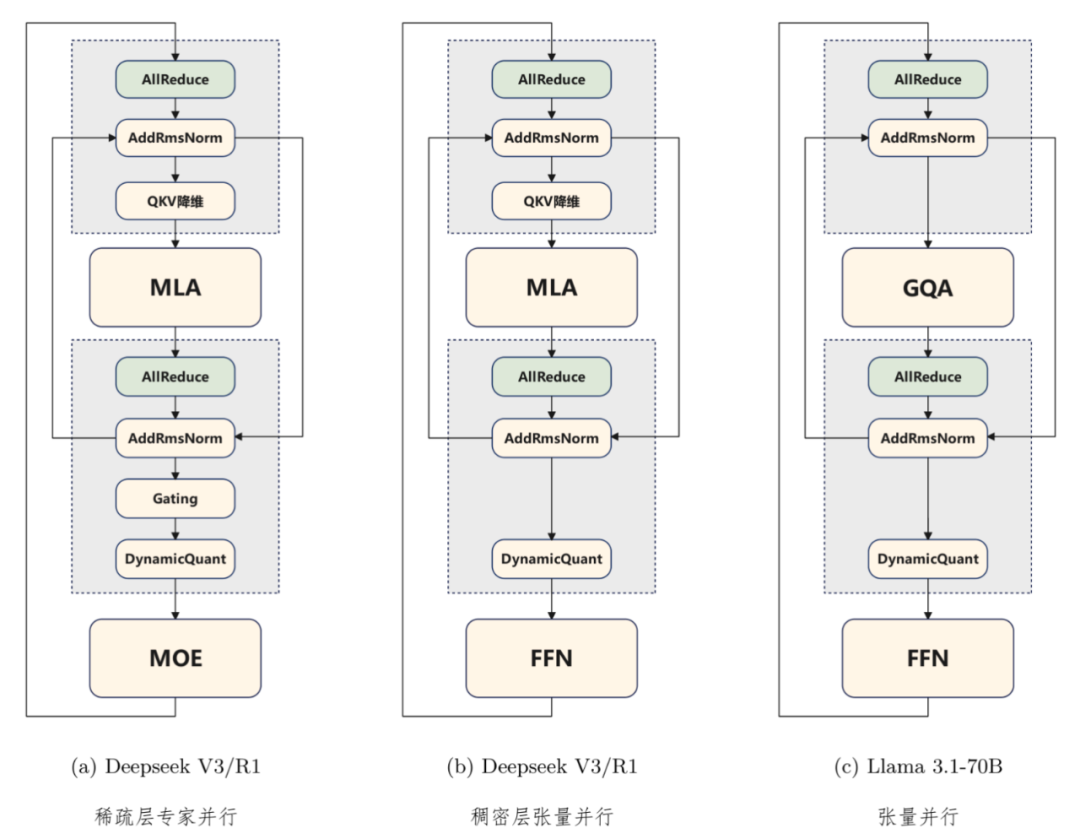
针对上面三个难题,华为团队用数学补物理,给出了他们的系列性创新解法,把加速大模型推理提到了新的高度。
项目链接:https://gitcode.com/ascend-tribe/ascend-inference-cluster/tree/main/FlashComm
FlashComm:别让通信扼住算力的咽喉
FlashComm1 通算重组:给通信装上「智能压缩器」
传统 AllReduce 的笨重通信方式如同用集装箱运输散装货物,华为团队则通过数学手段,基于昇腾硬件特点,将其拆解重构:先将数据智能分拣(ReduceScatter),再对精简后的核心信息进行广播(AllGather)。在这两个阶段之间,创新性插入数据投影降维和 INT8 动态量化技术,使后续通信量直降 35%,关键计算量锐减至 1/8。
这种「先浓缩再传递」的智慧,让 DeepSeek 模型 Prefill 推理性能提升 22 ∼ 26%,Llama3.1-70B 模型的 Decode 阶段性能提升 14%,如同为数据洪流建造了分级疏导系统。
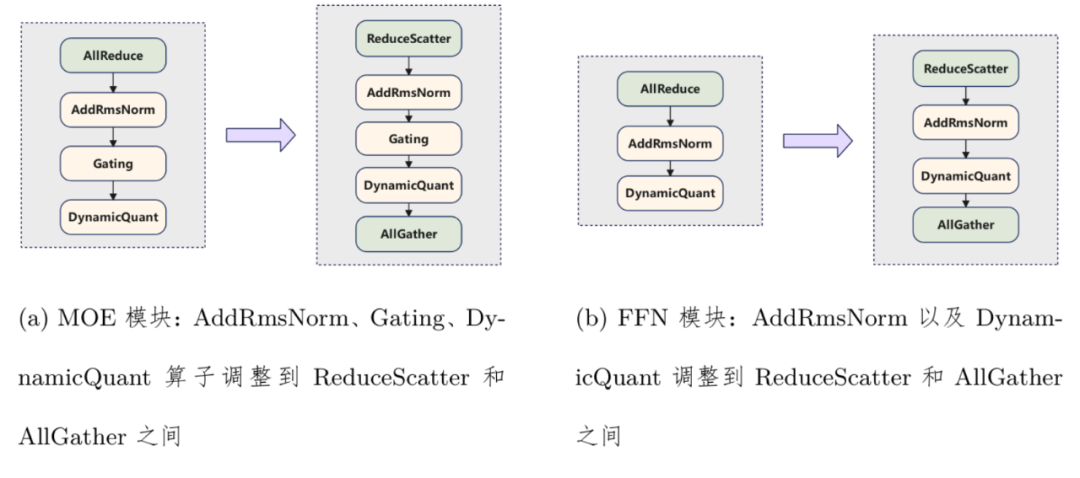
技术博客:https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/FlashComm/ascend-inference-cluster-flashcomm.md
FlashComm2 以存换传:重新定义计算与通信的平衡
面对 TP+AllReduce 架构的通信瓶颈,团队发现了一个精妙的数学等价关系:通过调整矩阵乘法的并行维度,在保持计算结果精确性的前提下,将原本需要传输的三维张量「压扁」成二维矩阵。这种维度魔法配合 INT8 量化技术,使得 DeepSeek 模型在注意力机制转换阶段的通信量骤降 86%,整体推理速度提升 33%。
这就像在保证货物完整性的前提下,把运输集装箱体积压缩了五分之四,让数据传输真正实现「轻装上阵」。
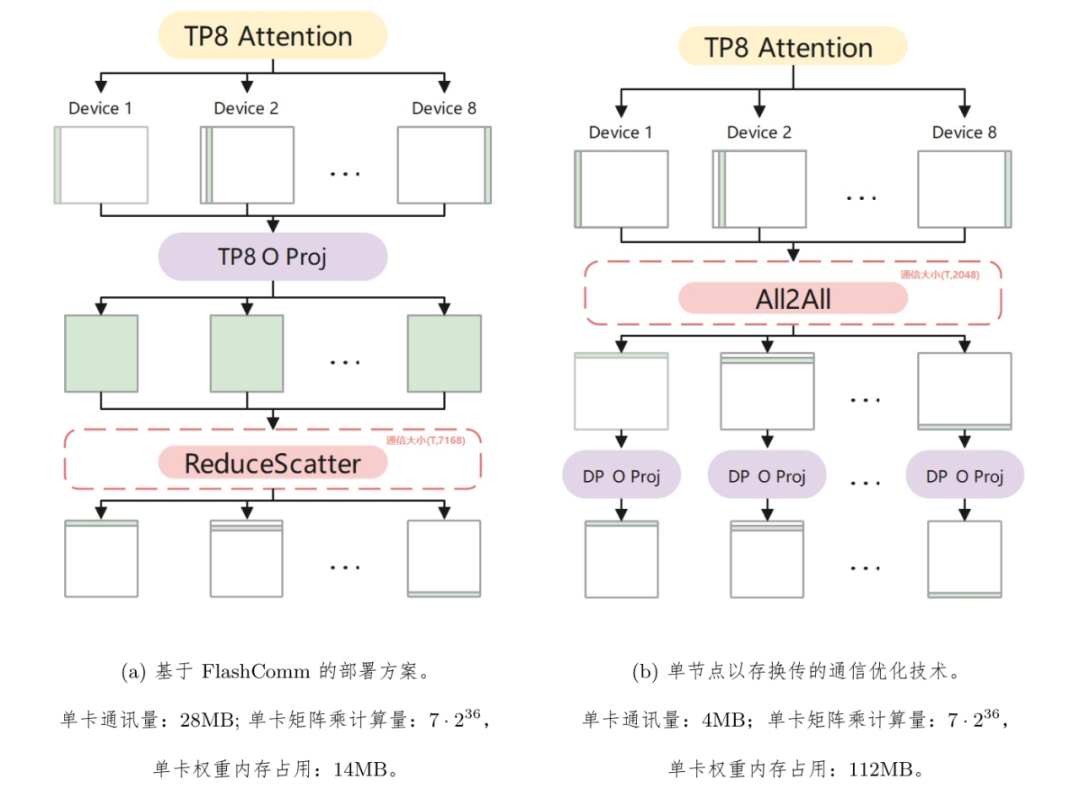
技术博客:https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/FlashComm/ascend-inference-cluster-flashcomm2.md
FlashComm3 多流并行:打破计算链条的串行桎梏
针对上文提到的最后一个问题,华为团队提出了昇腾亲和的大模型推理多流并行技术。
在 MoE 模型的推理过程中,华为团队如同拆解精密钟表般对 DeepSeek V3/R1 的计算流程展开深度剖析。通过数学重构将原本环环相扣的激活通信、门控决策等五大模块拆解重组,借助昇腾硬件的多流引擎实现三股计算流的精准并行:当一组数据正在进行专家计算时,另一组数据已开启门控决策,而第三组数据已在传输途中 —— 这种「计算不停歇」的流水线设计,使关键路径耗时大幅缩短。
更巧妙的是,通过 TP8 分片与流水线技术的交织运用,在多卡并行时仍为系统腾出 2GB 内存空间,如同在高速运转的引擎内部完成精密的空间重组。实际部署中,DeepSeek 模型的 Prefill 阶段提速超 10%,Decode 吞吐激增 25%-30%。
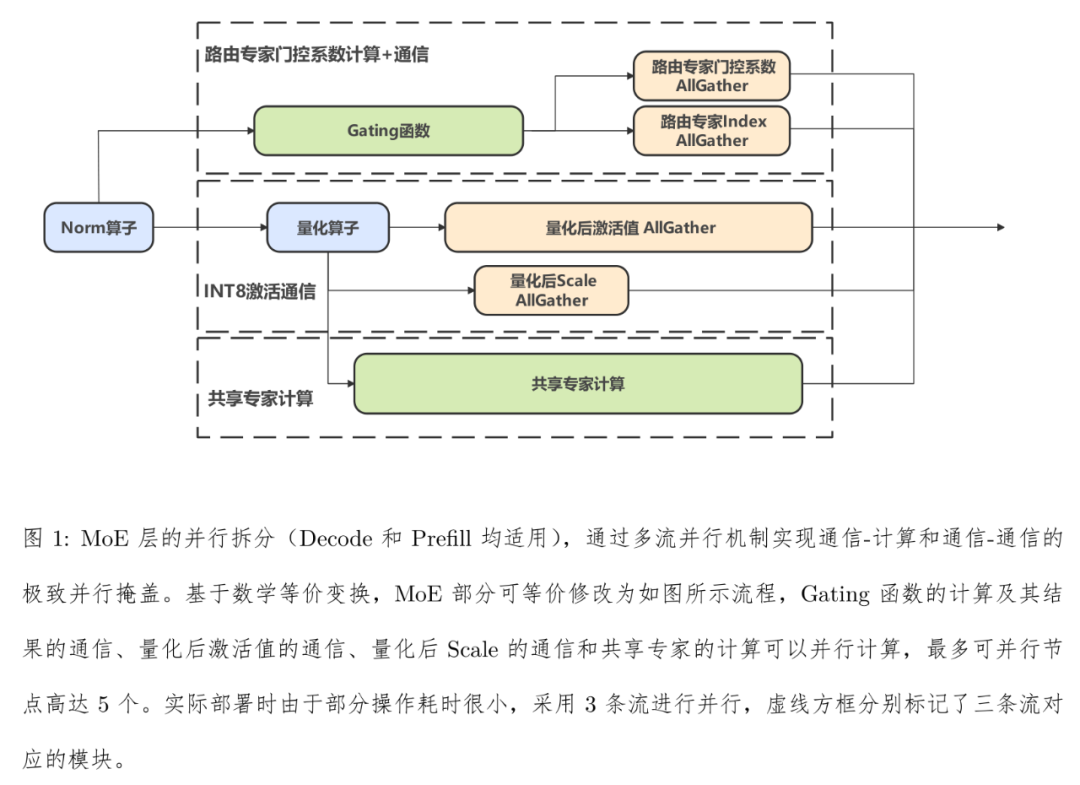
技术博客:https://gitcode.com/ascend-tribe/ascend-inference-cluster/blob/main/FlashComm/ascend-inference-cluster-flashcomm3.md
总结与展望
针对 DeepSeek 这类超大规模 MoE 模型的多机多卡推理场景中的通信挑战,华为团队提出了三项关键技术,其中 FlashComm 技术基于相同的集合通信逻辑替大模型推理中的 AllReduce 通信算子,在不改变网络并行方式的前提下,充分利用网络中低维度数据或低比特数据特性进行通信算子位置的编排,实现通信数据量的降低和通信时延的优化,同时消除了计算流程中的冗余计算,进一步提升了网络端到端推理性;FlashComm2 技术充分考虑网络并行过程中数据特征的维度变化,基于相同的集合通信逻辑将张量并行中的原有通信算子进行替换,并对新的通信算子在网络中的位置进行编排;FlashComm3 技术通过对 MoE 架构的细致理解,通过计算流程的等价变换,尽可能提升模型计算的并行度,并借助昇腾硬件提供的多流能力实现并行,进而大幅提升大模型的推理吞吐。
未来,围绕着超大规模 EP 下的多流并行、权重自动预取、模型自动多流并行等方向,华为团队将进行更多的创新,进一步提升大模型推理的系统性能。
同时,随着大语言模型特别是 MoE 架构的进一步扩展,其参数规模、专家数量与并发推理需求将持续增长,对通信、调度和资源协同会提出更高的要求。在这一趋势下,华为昇腾不仅仅是硬件算力的提供者,更要构建一个面向大模型推理的全栈生态体系。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com