ACL 2025 论文 KnowSelf 提升大模型智能体知识边界感知能力,使其更自主、高效地进行任务规划,减少无效试错。
原文标题:ACL 2025 | 大模型乱试错、盲调用?KnowSelf让智能体有「知识边界感知」能力
原文作者:机器之心
冷月清谈:
怜星夜思:
2、论文中提到 KnowSelf 在少量知识的情况下超越了 100% 知识增强的基线方法,这说明了什么?我们应该如何理解“并非知识越多越好,精准的知识引入机制才是关键”这句话?
3、KnowSelf 目前主要在模拟环境数据集上进行测试,未来在实际应用中会遇到哪些挑战?如何进一步提升 KnowSelf 的实用性?
原文内容

在 AI 领域,大模型智能体的发展日新月异。我们今天要介绍的这篇 ACL 2025 论文——《Agentic Knowledgeable Self-awareness》,聚焦于如何提升智能体的「知识边界感知」能力,使其在复杂任务规划中更加得心应手,为智能体的可靠应用提供了新思路。

-
论文标题:Agentic Knowledgeable Self-awareness
-
论文链接:https://arxiv.org/abs/2504.03553
-
代码链接:https://github.com/zjunlp/KnowSelf
30 秒速读版本
KnowSelf 聚焦于大模型智能体在决策过程中所面临的「知识边界感知」问题。受人类决策机制启发,本文指出智能体应具备三类行为模式的自主决策能力:快速反应(快思考)、深度推理(慢思考),以及主动调用外部工具(本文以外部知识增强为例)。
KnowSelf 通过学习自身的知识边界,使智能体能在不同情境下自主判断是否具备足够知识进行生成和推理,以减少无效试错与知识滥用。实验表明,KnowSelf 可提升智能体的知识调用准确率、任务规划效率和跨任务泛化能力。
研究背景:智能体规划的困境
大模型智能体在诸多领域展现出巨大潜力,但现有智能体规划方法存在弊端。传统方法多采用「盲目灌输」模式,将标准轨迹、外部反馈和领域知识无差别地注入智能体模型,完全忽视了人类决策过程中至关重要的「自我认知」原则。
这种「无脑式」灌输导致智能体在面对意外信号时极易崩溃,陷入模式崩塌困境,且过度试错与盲目知识融合在实际场景中往往不可行,还会大幅推高模型推理成本。
人类在决策时,会根据面临的情境动态评估自身状态,灵活调整策略。比如,当我们遇到简单问题时,能迅速做出判断并行动;遇到棘手问题,会放慢思考节奏,深入分析;而面对超出自身能力范围的问题,会主动寻求外部知识或帮助。
然而,当前大模型智能体普遍缺乏这种「知识边界感知」能力,导致规划行为低效且脆弱。
核心方法:KnowSelf 框架
为破解这一难题,论文提出了智能体「知识边界感知」的思路,并基于此设计了数据驱动 KnowSelf 方法,让大模型智能体能够自主调节知识的运用。

-
知识系统构建
对于外部工具(知识),并采用了一种简单高效知识收集方法,以极低成本完成知识库的离线构建。该知识系统由知识库和知识选择模块组成,其中知识库包含一系列知识条目,知识选择模块能依据智能体历史轨迹从知识库中精准挑选所需知识。这种设计兼顾了知识系统的实用性和高效性。
-
情境判断标准
论文基于智能体的能力,将情境划分为三类:快速思考(Fast Thinking)、慢速思考(Slow Thinking)和知识型思考(Knowledgeable Thinking)。并提出了启发式情境判断标准,用于标记智能体自我探索轨迹中的特殊标记,从而针对智能体的能力构建出训练数据,为后续训练奠定基础。
-
快思考:智能体无需多虑,能直接给出正确行动
-
慢思考:智能体虽能给出正确行动,但需经过多步思考与反思
-
知识型思考:智能体自身无法提供正确行动,必须借助外部知识辅助思考
-
自我认知训练
KnowSelf 采用双阶段训练过程,先通过监督式微调(SFT),让智能体模型初步掌握自我认知规划模式;再引入 RPO 损失函数,进一步强化自我认知能力。在这一体系下,智能体会生成特定特殊标记,表明其对情境的判断,在推理过程中实现知识查询与反思的精准调控。
实验成果
本文在两个模拟大模型智能体规划数据集 ALFWorld 和 WebShop 上,对 KnowSelf 进行了全面评估,涵盖 Llama-8B 和 Gemma-2B 两个不同规模的模型。实验结果显示,KnowSelf 凭借极少的反思和知识使用,性能优于多种基线方法。
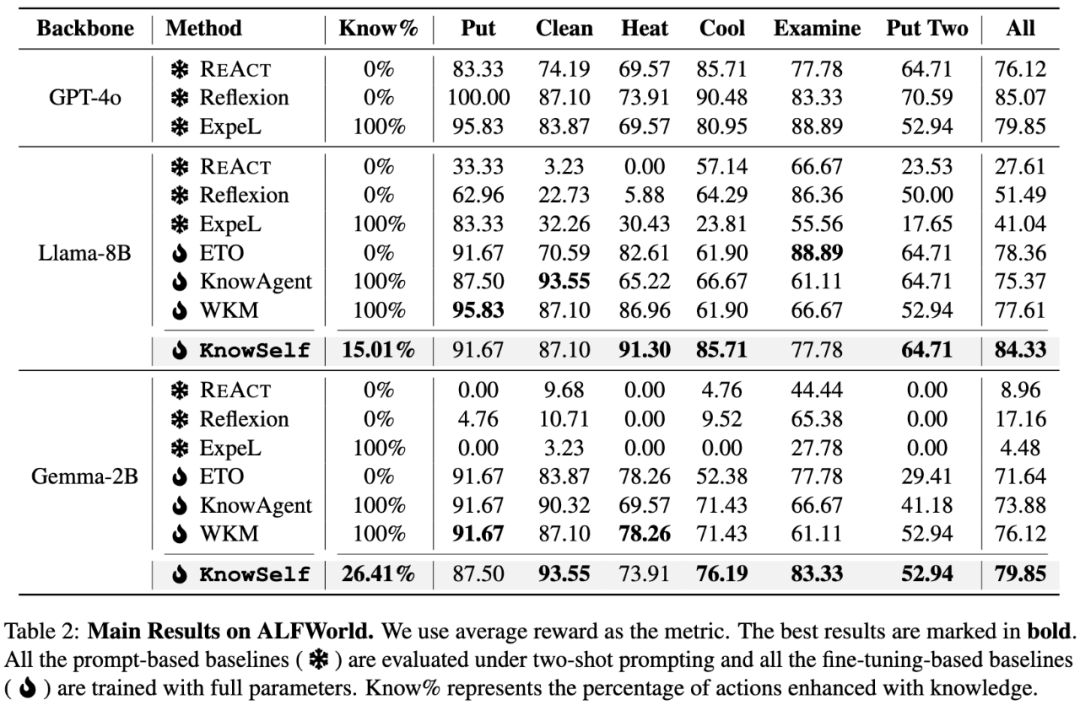
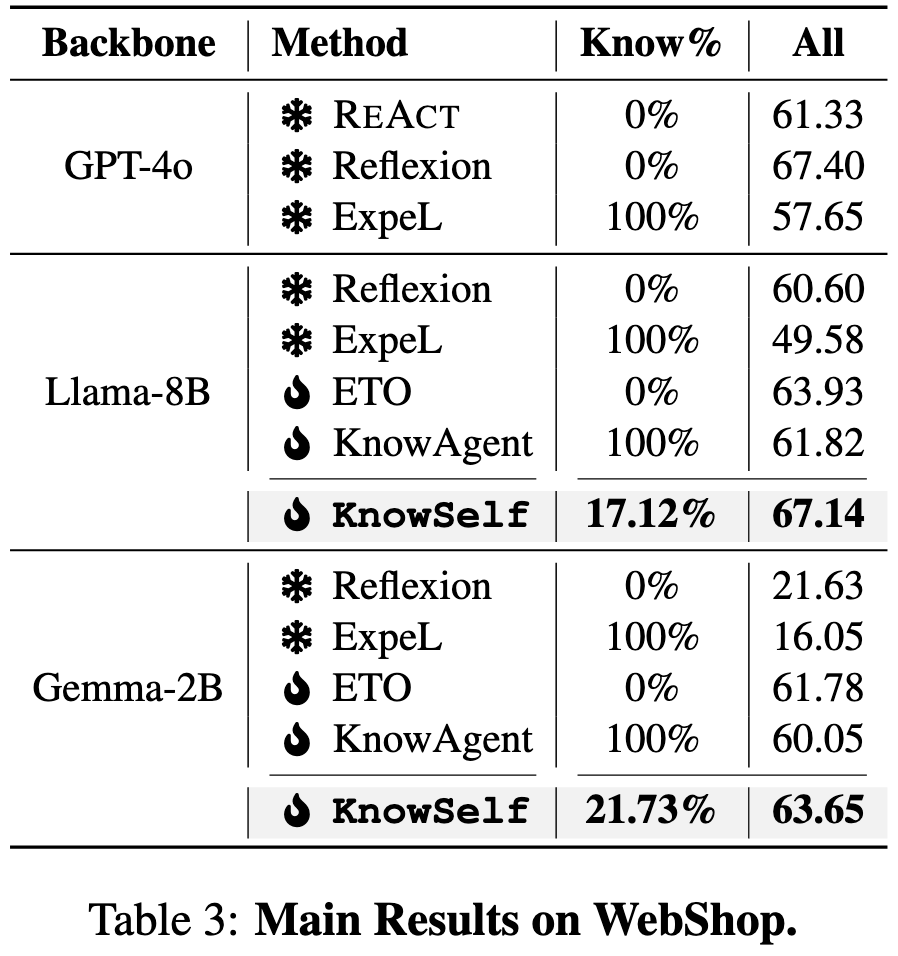
与无知识基线方法对比,KnowSelf 在 Llama-8B 和 Gemma-2B 模型上均展现出卓越性能。与知识增强型基线方法相比,KnowSelf 仅用少量知识,就超越了所有的 100% 知识增强基线方法,充分证明了并非知识越多越好,精准的知识引入机制才是关键。
进一步分析:深入探索智能体自我认知
-
智能体规划模式过拟合
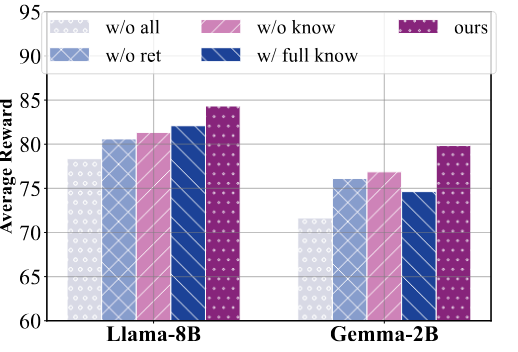
本文通过消融实验,发现仅在标准轨迹上训练的模型更易陷入模式拟合,而引入反思和知识边界感知后,智能体规划能力提升。这表明,在许多情况下,智能体并非不能做出正确决策,而是受限于规划模式。此外,过度引入知识可能会对性能产生负面影响,因此凸显了精准知识引入机制的重要性。
-
智能体规划泛化能力
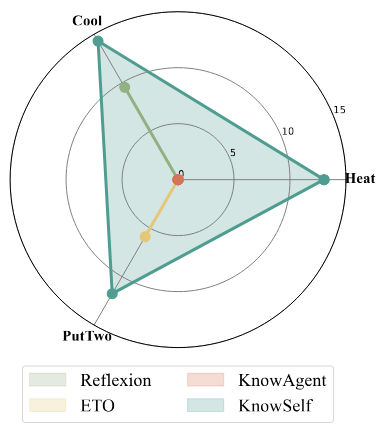
在泛化能力测试中,KnowSelf 在 ALFWorld 的三项挑战性任务上表现优异,优于基于提示的基线方法 Reflexion。这表明 KnowSelf 能有效打破传统规划轨迹训练的局限,使模型具备跨任务情境感知能力,在未见过的任务上能灵活运用反思和知识引入策略。
-
模型与数据规模影响
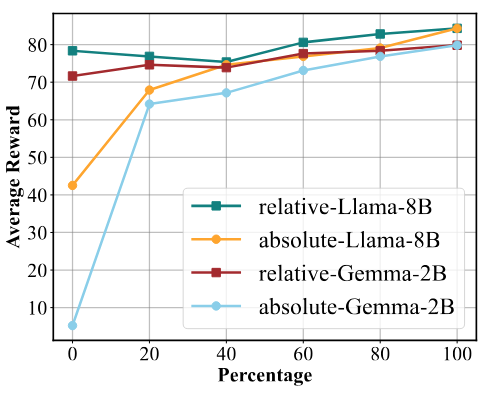
随着模型规模扩大和自我认知训练数据量增加,KnowSelf 性能稳步提升。当自我认知训练数据相对比例低于 40% 时,模型性能可能出现波动甚至下降,推测模型需达到一定自我认知水平才能稳定发挥效能。
-
智能体自我认知机制机理
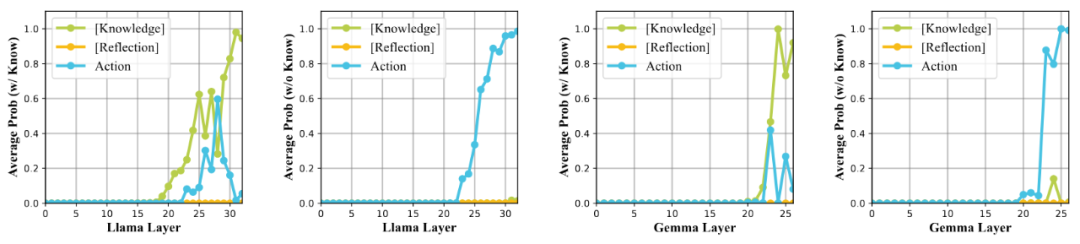
本文在 Transformer 模型的各层计算不同情境标记的平均概率,发现 Reflection 标记概率始终为零,Knowledge 标记和 Action 标记在模型最后几层才出现。这表明智能体在内部决策时,仅在最后几层隐藏层才决定是否调用外部知识,且调用知识的决策可能更晚出现,暗示智能体在 Token 空间内通过隐式奖励引导进行探索,最终做出决策。
结论与展望
本文提出的 KnowSelf 方法为智能体规划提供了新思路,初步探索了智能体知识边界感知这一问题。在后 R1 时代,随着 Search-R1、ReSearch、Deep Researcher 等工作的出现,基于 RL 的智能体自主知识获取工作展现了巨大的前景,KnowSelf 还只是在这个时代之前的初步产物,相信随着技术的发展,基于 RL 的智能体自我认知能迸发更大的活力。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com