MIT与谷歌提出PASTA,通过策略学习驱动LLM异步并行生成。模型自主标注语义独立内容块,实现并行推理,显著提升LLM推理效率,为LLM推理效率优化开辟新路径。
原文标题:策略学习助力LLM推理效率:MIT与谷歌团队提出异步并行生成新范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、PASTA-LANG 使用 promise、async 和 sync 标记来控制异步生成流程,如果让你来设计,你会如何改进或者扩展这个标记语言?
3、PASTA 的推理系统设计中,KV 缓存的交错式存储是关键,但这种设计会带来哪些新的挑战?
原文内容

金天,麻省理工学院(MIT)计算机科学与人工智能实验室(CSAIL)博士五年级学生,师从 Michael Carbin 和 Jonathan Ragan-Kelley。他主要研究机器学习与编程系统的结合。此前曾在 IBM Research 主导实现深度神经网络在 IBM 主机上的推理部署。本科毕业于 Haverford College,获计算机科学与数学双学位。
鄭鈺熹,麻省理工学院 CSAIL 博士三年级学生,师从 Michael Carbin。她的研究方向为编程语言与机器学习的交叉领域。
大语言模型(LLM)的生成范式正在从传统的「单人书写」向「分身协作」转变。传统自回归解码按顺序生成内容,而新兴的异步生成范式通过识别语义独立的内容块,实现并行生成。
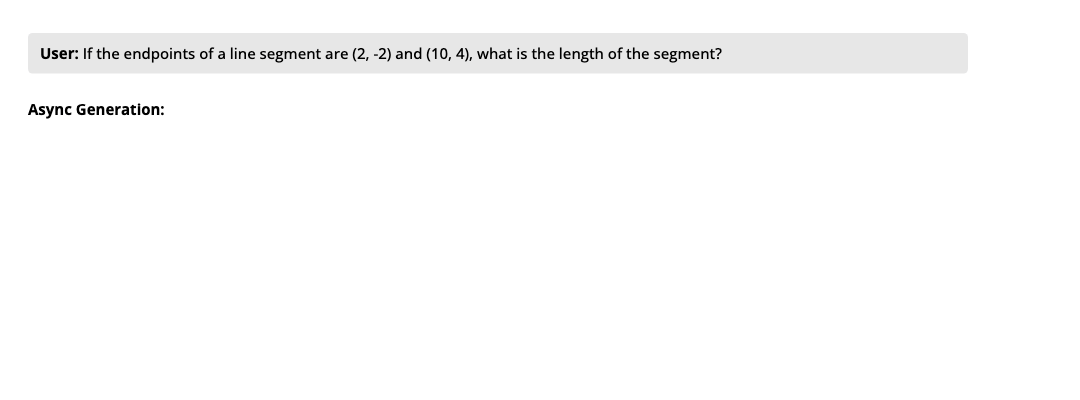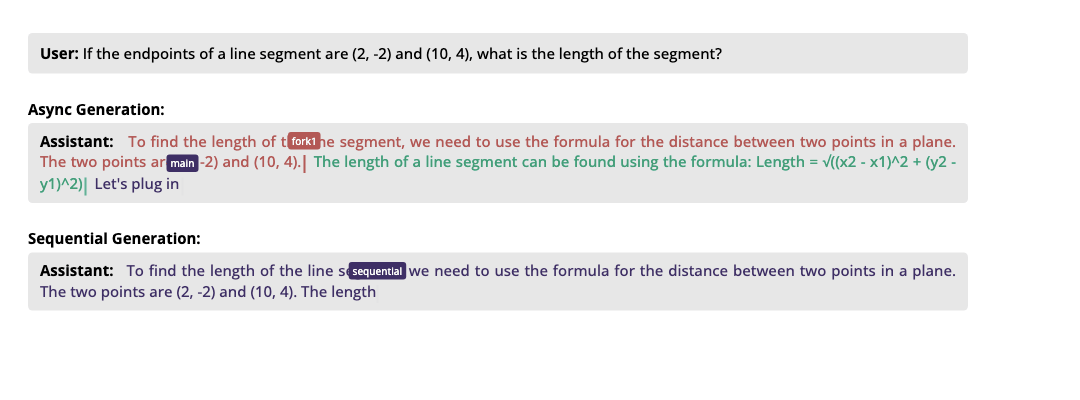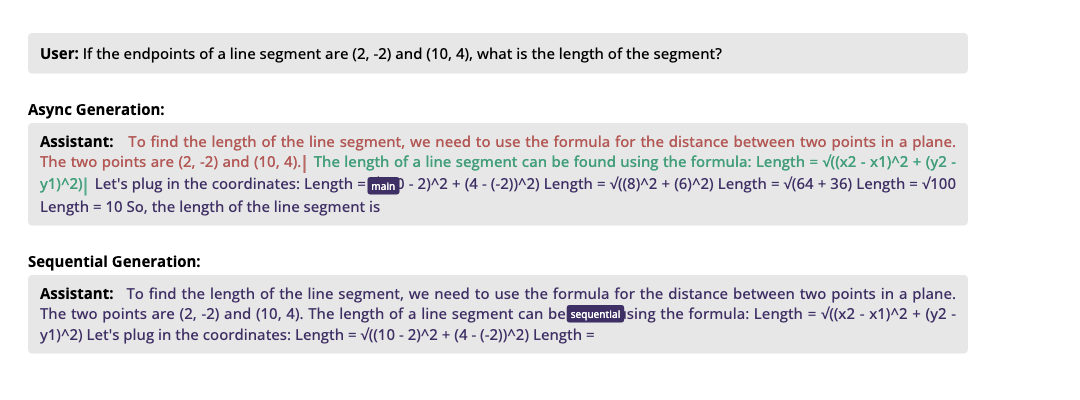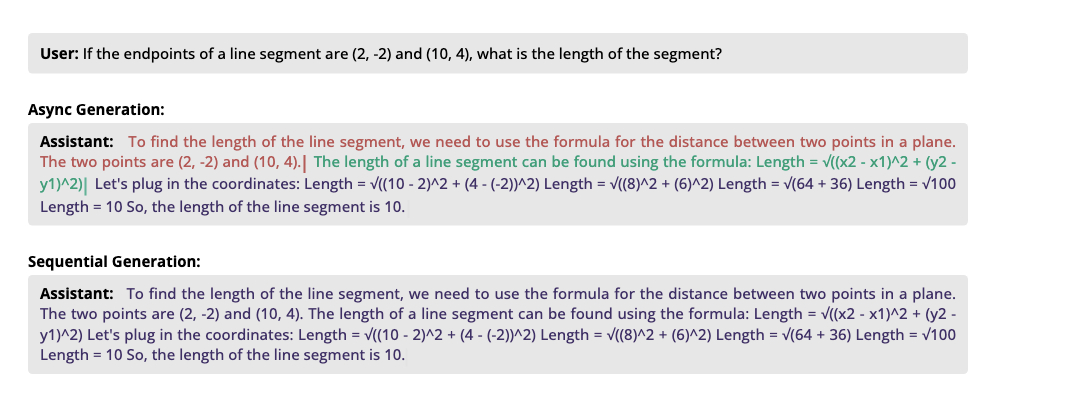
如图所示,传统方法(下)按顺序生成所有内容,而异步生成(上)同时处理多个互不依赖的内容块。对比顺序生成,异步生成在 AlpacaEval 长度控制评测中实现 1.21-1.93× 的几何平均提速,对应生成质量变化(胜率)为 +2.2% 至 -7.1%。
MIT 与谷歌研究团队在最新研究 PASTA(PArallel STructure Annotation)中首次从策略学习(policy learning)角度探索异步生成范式的可能。

-
论文标题:Learning to Keep a Promise: Scaling Language Model Decoding Parallelism with Learned Asynchronous Decoding
-
论文地址:https://arxiv.org/abs/2502.11517
研究团队不依赖人工设计规则来识别异步生成机会,而通过策略学习让模型自主发现并标注这些机会,系统地优化质量与速度的平衡。这种方法使 LLM 根据内容特点自适应地确定最佳异步生成策略,为生成效率优化开创学习驱动的全新路径。
PASTA-LANG:划分独立内容的标记语言
研究人员首先开发了一种新的标记语言 PASTA-LANG,专为异步生成而设计。大模型使用它在生成过程中标记语义独立块,指示并行生成机会。这种语言包含三种核心标记:
-
<promise topic="..."/>:标记语义独立的内容块,通过 topic 属性总结内容主题,大模型用它表明「这部分将会由一个独立子线程异步生成」。
-
<async>...</async>:在<promise>后标识对应的异步生成的内容,表示这一部分由独立子线程负责生成。
-
<sync/>:在主线程标记同步点,表明后续内容生成将会依赖于之前的异步生成,主线程需等待所有异步线程完成后才能继续。
<promise/> 标记「承诺」生成某些内容,推理系统再创建异步线程来「履行」这些承诺,最后在 <sync/> 处将异步内容组合。
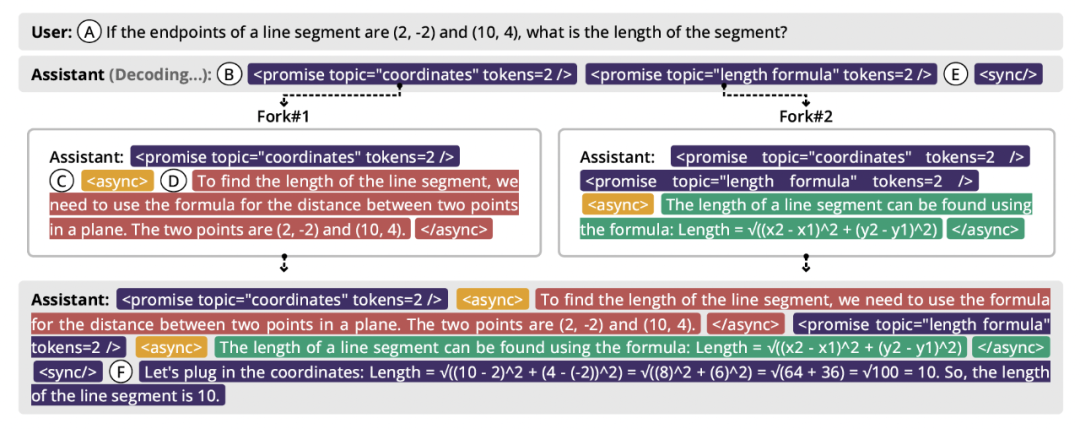
<promise/> 标记(B),随后用 <sync/> 标记(E)表明需要等待这些内容完成。图中红色和绿色区域(C、D)显示了两个异步线程并行生成的内容,最终在(F)处组合成完整解答。
这个新的标记语言简单,可扩展性强,开启了新的未来研究范式。
PASTA 训练:从标注到优化的双阶段学习
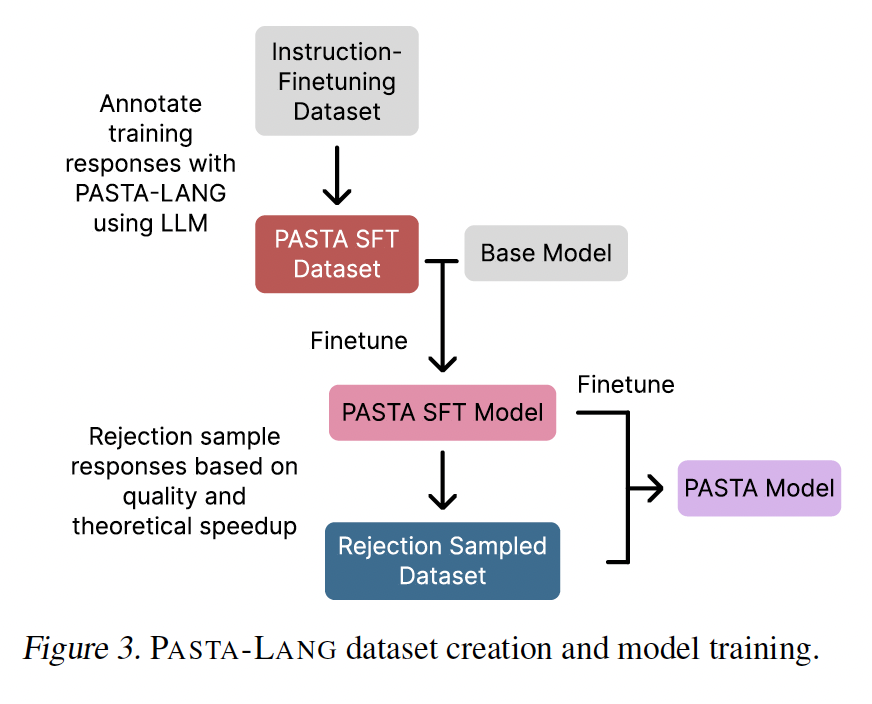
如图所示,PASTA 系统采用双阶段训练流程,使大模型自主学习使用上述标记语言,完成异步生成。
第一阶段:监督微调。研究团队首先选取 SlimOrca 指令跟随数据集,用 Gemini 1.5 Flash 为 100K 条样本添加 PASTA-LANG 标记,在样本回答中插入 <promise/>、<async> 和 <sync/> 标记, 创建 PASTA 微调数据集。团队随后对 Gemma 7B 进行监督微调,得到能插入 PASTA-LANG 标记的 PASTA-SFT 模型。
第二阶段:偏好优化。为优化标注策略,团队设计了策略学习方案。团队对每个样本从 PASTA-SFT 模型采样多种标注方案,然后基于两项指标评估这些方案:理论加速比和内容质量(由 Gemini 1.5 Pro 评估)。根据评估结果,团队构建「拒绝采样数据集」,该数据集包含每个输入的最佳和最差标注方案。最后,团队用 BoNBoN 算法对 PASTA-SFT 模型进行偏好优化,得到最终的 PASTA 模型。
PASTA 推理系统:并行生成与缓存管理
推理系统设计难点。异步并行生成的主要挑战在于如何协调多个线程高效协作。传统方法通常需要为每个线程创建独立的 KV 缓存池——创建新线程时必须复制主线程的前缀内容到子线程缓存池,完成后再复制结果回主线程。这两次大规模矩阵复制操作严重限制了系统性能,使理论加速难以转化为实际收益。
KV 缓存的存储布局。PASTA 设计了交错式 KV 缓存布局,所有线程共享单一连续内存池。系统初始以连续方式存储用户输入,在推理过程中动态将不同线程在同一时间点生成的 token 交错存储在相邻位置。
注意力控制与位置编码。PASTA 通过两个机制确保大模型正确理解多线程交错存储的 KV 缓存:
-
注意力掩码控制:限制子线程只能访问与自己相关的内容,在<sync/>后通过移除掩码使主线程能访问所有子线程生成的内容。
-
位置编码调整:每个线程都使用独立且连续的位置编码,使线程处理自己的内容时,将交错存储的内容视为逻辑上连续的序列,确保模型能正确理解上下文。
这些设计共同确保 PASTA 能在提高速度的同时保持输出质量。
实验结果:Pareto 最优与可扩展性
PASTA 在性能与质量的平衡上取得了突破性成果,实验结果表明它不仅实现了显著加速,还在某些情况下提高了输出质量。研究团队在 AlpacaEval 基准上进行了全面评估,该基准包含 805 个具有代表性的指令跟随任务。
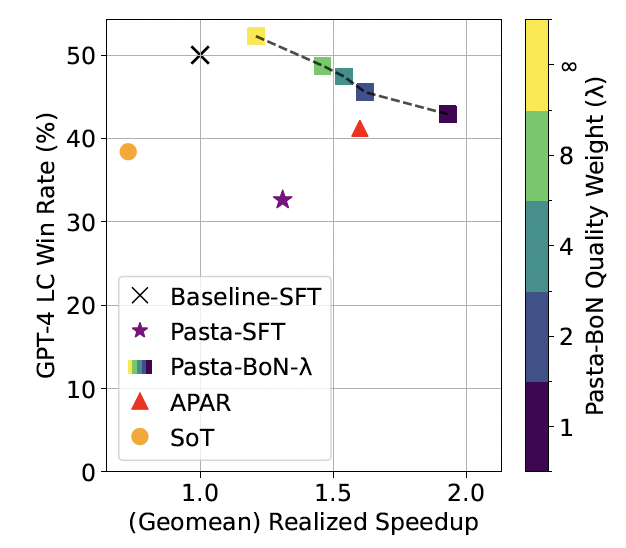
质量-速度平衡的 Pareto 前沿。如图所示,PASTA 通过调节质量权重参数生成了一系列的模型。在不同的生成质量的情况下,PASTA 均能提供非常可观的加速。结果显示,即使最注重质量的 PASTA 模型也能提供显著加速,而最快的模型则以一定的质量牺牲换取接近 2 倍的速度提升。与基于手动设计的异步生成方案(Skeleton-of-Thought, APAR)相比,PASTA 模型展现出全面优势。
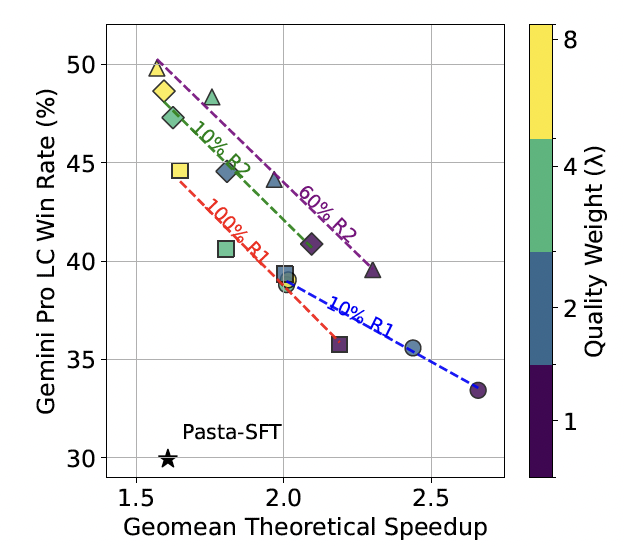
可扩展性。研究结果展示了 PASTA 方法出色的可扩展性,如图所示。随着偏好优化不断推进,PASTA 模型的性能持续提升。图中清晰展示了从第一轮开始到第一轮结束,再到第二轮开始和第二轮后半程的整个优化过程,质量-速度的 Pareto 前沿大体持续向右上方推进。
这种稳定的改进趋势表明,PASTA 方法具有良好的可扩展性——随着投入更多计算资源,仍未饱和。与传统依赖固定规则的异步解码方法不同,PASTA 通过策略学习驱动的训练算法提供了可持续的优化路径,能够有效地将额外计算资源转化为更高的推理效率。
总结与展望
PASTA 首次证明,通过策略学习让 LLM 自主优化生成策略,能够突破传统自回归和基于规则的异步生成的效率极限。这一工作不仅为实时大模型应用提供了实用加速方案,更印证了未来 LLM 可能具备推理时自我优化能力的发展方向。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com