智源发布BGE系列代码、多模态、可视化文档向量模型,全面登顶SOTA!代码检索、图文匹配、文档分析,AI检索能力再升级!
原文标题:代码、多模态检索全面登顶SOTA!智源BGE向量模型三连击,并全面开放
原文作者:机器之心
冷月清谈:
怜星夜思:
2、BGE-VL-v1.5在多模态检索方面有很强的通用性,那么在实际应用中,如何根据不同的场景选择合适的训练数据,以进一步提升模型的性能?
3、BGE-VL-Screenshot模型专注于可视化文档的检索,那么在信息安全领域,它有哪些潜在的应用?例如,如何利用它来检测钓鱼网站或恶意文档?
原文内容
机器之心编辑部
检索增强技术在代码及多模态场景中的发挥着重要作用,而向量模型是检索增强体系中的重要组成部分。针对这一需求,近日,智源研究院联合多所高校研发了三款向量模型,包括代码向量模型 BGE-Code-v1,多模态向量模型 BGE-VL-v1.5 以及视觉化文档向量模型 BGE-VL-Screenshot。这些模型取得了代码及多模态检索的最佳效果,并以较大优势登顶 CoIR、Code-RAG、MMEB、MVRB 等领域内主要测试基准。BGE 自 2023 年 8 月发布以来,已成为中国首个登顶 Hugging Face 榜首的国产 AI 模型以及 2023 年所有发布模型的全球下载量冠军。
目前,BGE-Code-v1、BGE-VL-v1.5、BGE-VL-Screenshot 三款模型已向社区全面开放,为相关技术研究与产业应用提供助力。
BGE-Code-v1:
-
模型地址:https://huggingface.co/BAAI/bge-code-v1
-
项目主页:https://github.com/FlagOpen/FlagEmbedding/tree/master/research/BGE_Coder
-
论文链接:https://arxiv.org/abs/2505.12697
BGE-VL-v1.5:
-
模型地址:https://huggingface.co/BAAI/BGE-VL-v1.5-zs
-
项目主页:https://github.com/FlagOpen/FlagEmbedding/tree/master/research/BGE_VL
-
论文链接:https://arxiv.org/abs/2412.14475
BGE-VL-Screenshot:
-
模型地址:https://huggingface.co/BAAI/BGE-VL-Screenshot
-
项目主页:https://github.com/FlagOpen/FlagEmbedding/tree/master/research/BGE_VL_Screenshot
-
论文链接:https://arxiv.org/abs/2502.11431

由智源研究院主导研发的通用向量模型系列 BGE,旨在为各类数据提供高效一站式向量表征与语义检索方案,已推出覆盖中英文、多语言检索及重排模型等多个版本,持续刷新 MTEB、C-MTEB、BEIR、MIRACL 等主流文本向量评测基准。BGE 凭借高性能与开源特性备受业界关注,已广泛应用于 RAG、神经搜索等场景,累计下载超 6 亿次,被国内外多家 AI 企业集成。
目前,检索增强技术正从传统的文本场景逐步拓展至涵盖代码与视觉等多模态数据的应用。然而,相较于文本领域,现有向量模型在代码和视觉模态中的检索效果仍有待提升。此次智源研究院发布的三款新模型,为构建更强大的多模态检索增强系统提供了有力的支持。
BGE-Code-v1
新一代代码优化语义向量模型
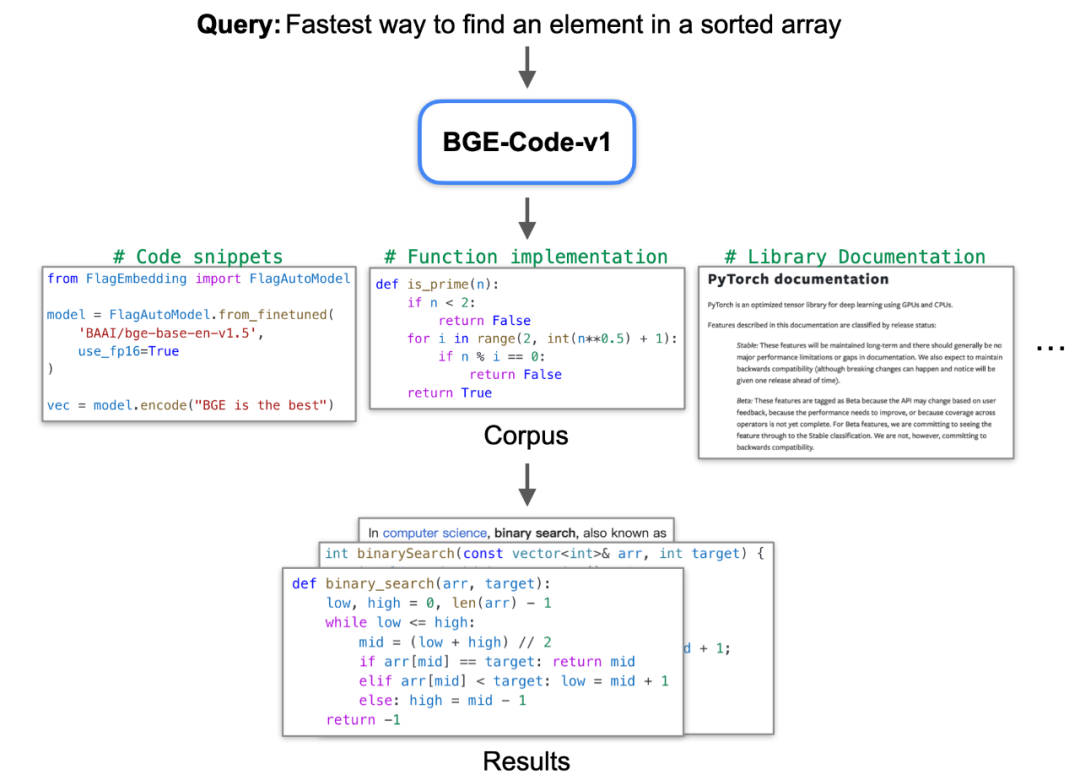
随着基础模型代码能力快速发展,Cursor、Copilot 等辅助编程工具大幅提升生产力。在面对百万行级代码库时,代码块检索增强需求凸显,因此检索模型的代码理解能力至关重要。
BGE-Code-v1 是以 Qwen2.5-Coder-1.5B 为基座打造的新一代代码向量模型,专为各类代码检索相关任务而设计,同时配备了强大的多语言文本理解能力。模型基于 CoIR 训练集和大量高质量代码 - 文本的合成数据进行训练,并使用课程学习,以 BGE-gemma2-multilingual 的 retrieval、STS 数据为辅助,进一步提升代码与文本的理解能力。BGE-Code-v1 适用于开发文档搜索、代码库语义检索、跨语言信息获取等多种实际应用场景,是面向代码 - 文本检索任务的最优选择。
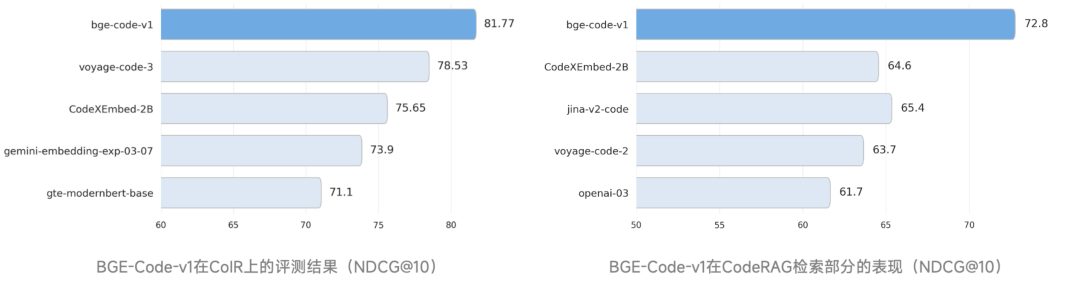
CoIR 代码检索基准,收集了覆盖 14 种编程语言的 4 大类 8 个子任务,能够有效地评估模型在自然语言和代码的各类混合场景中的检索能力。CodeRAG-Bench 基准评估了代码检索模型在代码检索增强(RACG)中的表现。BGE-Code-v1 在两个基准上均以显著优势超越谷歌、Voyage AI、Salesforce、Jina 等商业 / 开源模型,登顶 SOTA。
BGE-VL-v1.5
通用多模态检索模型

BGE-VL-v1.5 完成多模态检索任务
BGE-VL-v1.5 是基于 LLaVA-1.6(7.57B 参数)训练的新一代通用多模态检索模型,全面升级了图文理解能力并具有更强大的检索能力。BGE-VL-v1.5 在 MagePairs 300 万 (3M) 图文对齐数据基础上又收集了共 100 万条自然与合成数据(涵盖 image-captioning 数据、视觉问答数据、分类任务数据)进行多任务训练,显著地提升了模型在各类任务上的泛化性与理解能力。
基于 MegaPairs 数据,BGE-VL-v1.5 在多模态检索任务中性能优势显著,不仅在图像检索中表现强劲,更在通用多模态场景中展现高适应性与准确率,适用于图文匹配、多模态问答、跨模态推荐等场景。
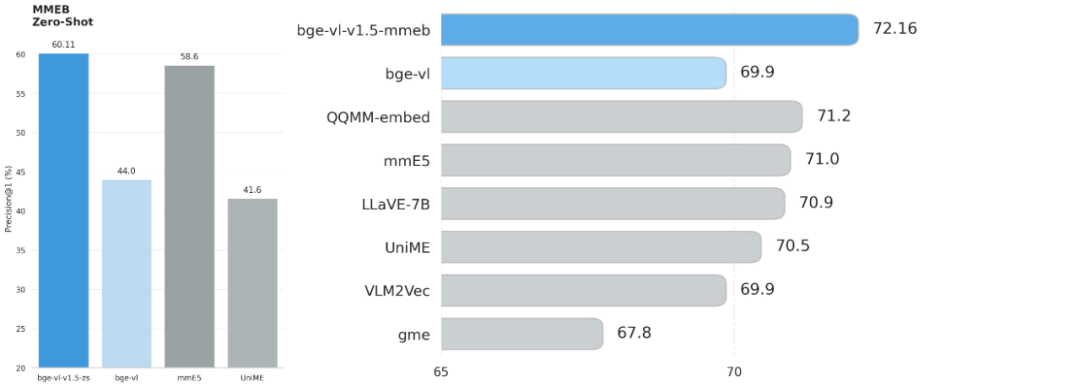
左为 BGE-VL-v1.5-zs 和其他 zero-shot 模型在MMEB上的表现,右为 BGE-VL-v1.5-MMEB 在 MMEB 基准检索任务上的表现
MMEB 是当前使用最广泛的多模态向量基准,由:分类、视觉问答、检索、视觉基础知识,四类任务构成。基于 zero-shot 设置(未使用 MMEB 训练集),BGE-VL-v1.5-zs 在 MMEB 基准中刷新 zero-shot 模型最佳表现;在检索任务上,基于 MMEB 微调的 BGE-VL-v1.5-MMEB 以 72.16 分登顶 SOTA。
BGE-VL-Screenshot
实用强大的视觉化文档向量模型
实际场景中网页、文档等多模态任务常由图文、符号、图表等多元素混合数据构成,这类任务称为 “可视化信息检索”(Vis-IR),因此,多模态模型不仅需要具备从复杂结构中提取关键信息的视觉能力,还需精准理解文本与视觉语义。目前,现有检索模型在此类任务中表现欠佳。

BGE-VL-Sc 基于截图与文本检索
BGE-VL-Screenshot 模型基于 Qwen2.5-VL-3B-Instruct ,以新闻、商品、论文、文档、项目主页等七类数据源进行训练,收集超过 1300 万张截图和 700 万组标注截图问答样本。
为了准确评估模型在 Vis-IR 任务上的表现,团队设计并推出了多模态检索基准 MVRB (Massive Visualized IR Benchmark,榜单链接:https://huggingface.co/spaces/BAAI/MVRB_leaderboard),涵盖截图检索、复合截图检索、截图 QA 和开放分类 4 项任务共 20 个数据集。
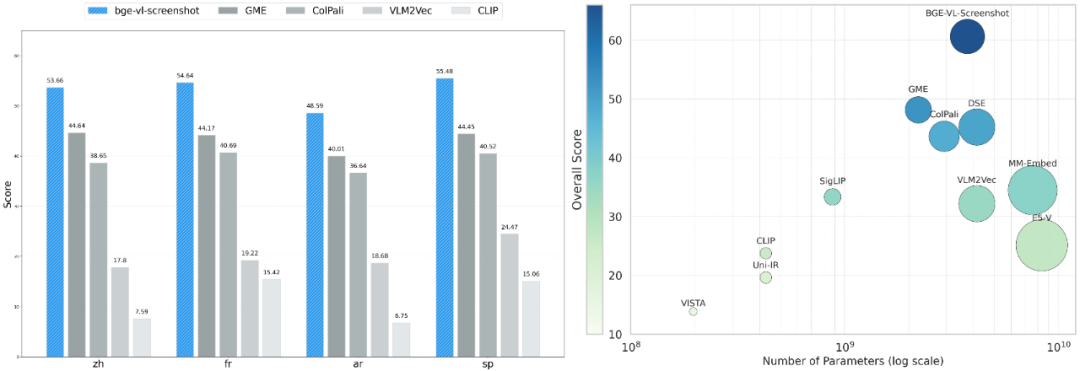
左为多语言 MVRB 测评结果,右为不同尺寸多模态检索模型 MVRB 评测结果对比
BGE-VL-Screenshot 在 4 项任务中表现出色,以 60.61 的综合得分达到 SOTA。在此基础上,通过少量 query2screenshot 多语言数据训练,模型实现了在英文之外的多语言任务上的出色表现。
智源研究院将继续深耕向量模型与检索增强技术,进一步提升 BGE 模型系列的能力与通用性。未来期待与更多科研机构与产业伙伴合作,共同推动检索与人工智能发展。欢迎广大研究者与开发者关注并使用 BGE 系列模型,共建开放繁荣的开源生态。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com