《图解大模型》用300幅图带你入门大模型!内容涵盖原理、应用与微调,附赠DeepSeek-R1解读和200道面试题,更有海量资料和视频课等你探索!
原文标题:新书上市|技术书还能这么美!300幅插图看懂大模型
原文作者:图灵编辑部
冷月清谈:
本书分为三个主要部分:
* **理解语言模型**:探索大、小语言模型的内部运作机制,介绍领域和常用技术,讨论词元和嵌入等核心组件,并深入探讨Transformer架构。
* **使用预训练语言模型**:通过常见用例展示如何使用LLM,包括监督分类、文本聚类和主题建模、文本生成、语义搜索等。
* **训练和微调语言模型**:探讨如何构建和微调嵌入模型,回顾如何针对分类任务微调BERT,并介绍几种生成模型的微调方法。
本书还附赠了中文版专享福利——《图解 DeepSeek-R1》,通过18幅彩图解读DeepSeek的底层原理。此外,译者李博杰还整理了200道高质量大模型面试题,帮助读者更深刻地理解相关知识点。本书适合对大模型感兴趣的开发者、研究人员和行业从业者,无需具备深度学习基础,只要会用Python,就可以通过本书深入理解大模型的原理并上手大模型应用开发。
怜星夜思:
2、书中提到了大量的图解,这种可视化学习方式对于理解大模型真的有效吗?或者说,对于不同学习风格的人,效果会有差异吗?
3、书中附赠了200道大模型面试题,你觉得在准备大模型相关的面试时,除了刷题,还应该注意哪些方面?
原文内容

中文书名为《图解大模型》,即以“图解”为核心理念,通过高质量插图(超过 300 幅哦!),彻底颠覆你对技术书“晦涩难懂”的刻板印象。从底层原理到应用开发,再到模型训练与微调,让大家不仅能“读懂”,还能“看懂”,更要“用起来”。



博杰老师不仅在原作上下了功夫,还结合自己在创业过程中面试候选人的经历,以及本书及其关联资料,针对大模型领域系统梳理出 200 道高质量面试题,附赠读者,旨在帮助大家更深刻地理解相关知识点。
附赠的内容以免费电子资料的形式开放(大家可前往图灵社区下载阅读)。
回到图书本身的内容,我们来看看这本书具体是怎么组织的,看一张目录导图吧!
04
这本书讲什么

结合这个目录,我们来看看本书的主要内容:
第一部分:理解语言模型
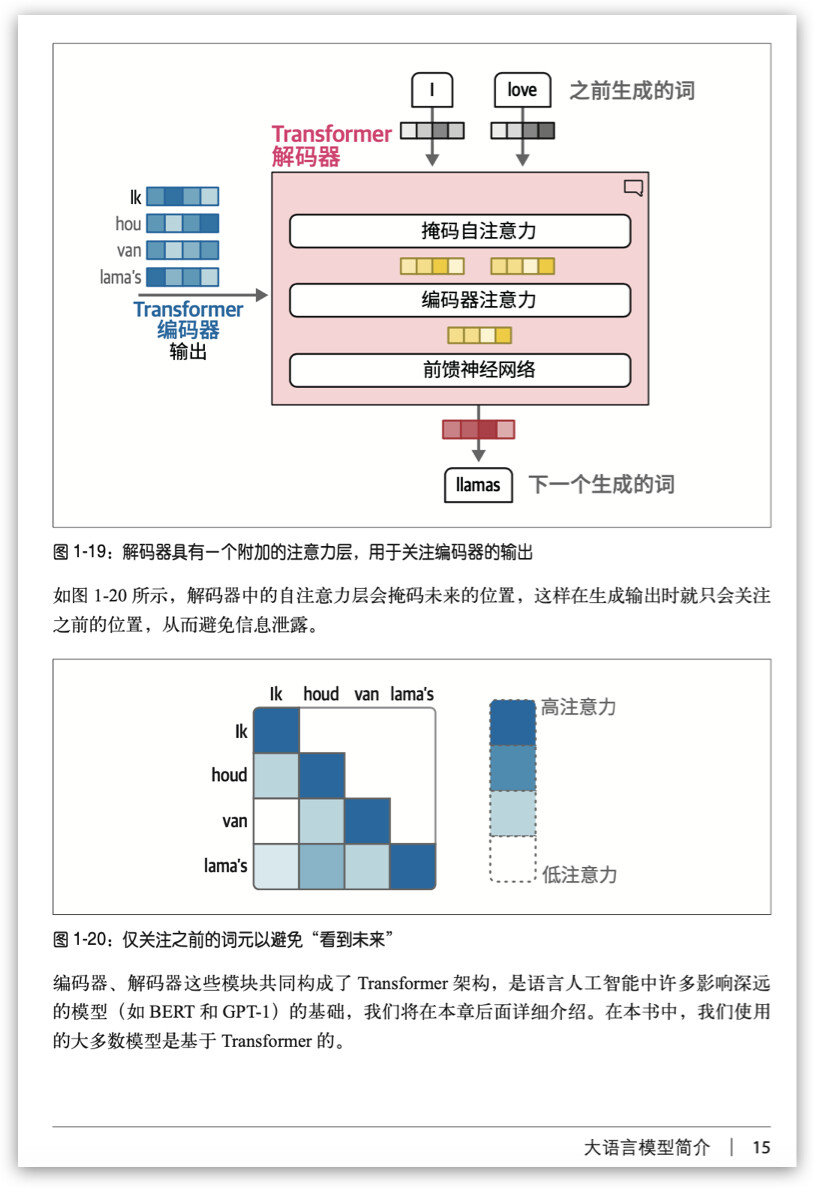
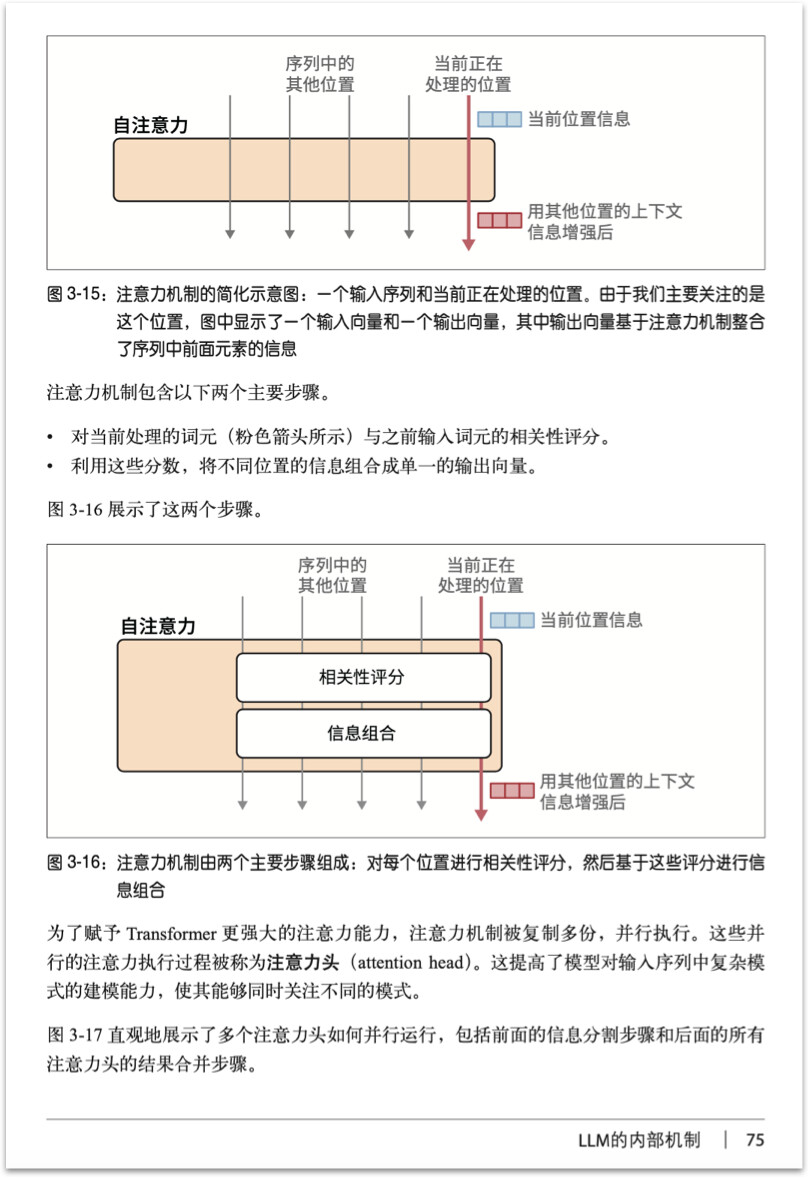
探索大、小语言模型的内部运作机制。首先概述该领域和常用技术(见第 1 章),然后讨论这些模型的两个核心组件(见第 2 章):词元(token)和嵌入 (embedding)。本部分最后是对 Jay 的大名鼎鼎的文章“The Illustrated Transformer”的更新和扩展,深入探讨了这些模型的架构(见第 3 章)。本部分还将介绍许多贯穿全书的术语及其定义。
第二部分:使用预训练语言模型
通过常见用例探索如何使用 LLM。我们将使用预训练模型并展示它们的功能,无须进行微调。
你将学习如何使用语言模型进行监督分类(见第 4 章)、文本聚类和主题建模(见第 5 章),利用嵌入模型进行文本生成(见第 6 章和第 7 章)、语义搜索(见第 8 章),以及将文本生成能力扩展到视觉领域(见第 9 章)。
学习这些独立的语言模型功能将使你具备用 LLM 解决问题的技能,并能够构建越来越高级的系统和流程。
第三部分:训练和微调语言模型
通过训练和微调各种语言模型来探索高级概念。我们将探讨如何构建和微调嵌入模型(见第 10 章),回顾如何针对分类任务微调 BERT(见第 11 章),并以几种生成模型的微调方法结束本书(见第 12 章)。
附录:图解 DeepSeek-R1
中文版专享福利,添加 Jay 大名鼎鼎的文章 “The Illustrated DeepSeek-R1”,通过 18 幅彩图解读 DeepSeek 底层原理,帮助读者真正认识推理大模型的本质。
05
适合谁阅读
本书适合对大模型感兴趣的开发者、研究人员和行业从业者。读者无须具备深度学习基础知识,只要会用 Python,就可以通过本书深入理解大模型的原理并上手大模型应用开发。书中示例还可以一键在线运行,让学习过程更轻松。
本书 GitHub 附赠大量延伸资料,且代码可通过 Google Colab 一键运行。
GitHub:
https://github.com/HandsOnLLM/Hands-On-Large-Language-Models

06
业内专家热评推荐
07
中文版附赠福利
-
【直观】300幅全彩插图,极致视觉化呈现
-
【全面】涵盖大模型原理、应用开发、优化
-
【实操】真实数据集,实用项目,典型场景
-
【热点】18 幅图深度解读 DeepSeek 底层原理
-
【附赠】一键运行代码 + 大模型面试题 200 问
-
【附赠】大量延伸阅读资料 + 两位作者的公开视频课
购买链接

