CrayonRobo通过视觉提示驱动机器人操作,提升其对任务目标的理解和在未知场景中的鲁棒性,已在模拟和现实环境中得到验证。
原文标题:【CVPR2025】CrayonRobo:面向机器人操作的以对象为中心的提示驱动视觉-语言-动作模型
原文作者:数据派THU
冷月清谈:
CrayonRobo是一种创新的视觉-语言-动作模型,旨在提升机器人操作的精确性和泛化能力。该模型通过在RGB图像上生成简洁的二维视觉提示,清晰地表达低层级动作和高层级任务规划。这些提示代表了任务目标,例如末端执行器的姿态和接触后的移动方向。CrayonRobo采用独特的训练策略,使模型能够理解视觉-语言提示,并在SE(3)空间中预测接触姿态与移动方向,从而完成长时间跨度的任务序列。该方法提升了模型对任务目标的理解,并增强了在未知场景中的鲁棒性。在模拟和现实机器人平台上的评估结果表明,CrayonRobo具备强大的操控能力和良好的泛化性能。
怜星夜思:
1、CrayonRobo模型中,二维视觉提示是如何减少自然语言歧义的?除了姿态和移动方向,还可以用视觉提示表达哪些信息来提升机器人操作的准确性?
2、CrayonRobo在未知任务场景中表现出鲁棒性,那么这种方法在哪些特定领域有更大的应用潜力?例如,在需要高精度操作的医疗领域,或者环境复杂的工业制造领域?
3、CrayonRobo通过关键帧步骤顺序执行任务序列,这种方法在处理复杂任务时,如何保证任务的稳定性和容错性?如果某个关键帧出现偏差,模型如何纠正?
2、CrayonRobo在未知任务场景中表现出鲁棒性,那么这种方法在哪些特定领域有更大的应用潜力?例如,在需要高精度操作的医疗领域,或者环境复杂的工业制造领域?
3、CrayonRobo通过关键帧步骤顺序执行任务序列,这种方法在处理复杂任务时,如何保证任务的稳定性和容错性?如果某个关键帧出现偏差,模型如何纠正?
原文内容

来源:专知本文约1000字,建议阅读5分钟我们在模拟环境与现实机器人平台中对该方法进行了评估,结果表明其具备强大的操控能力与良好的泛化性能。

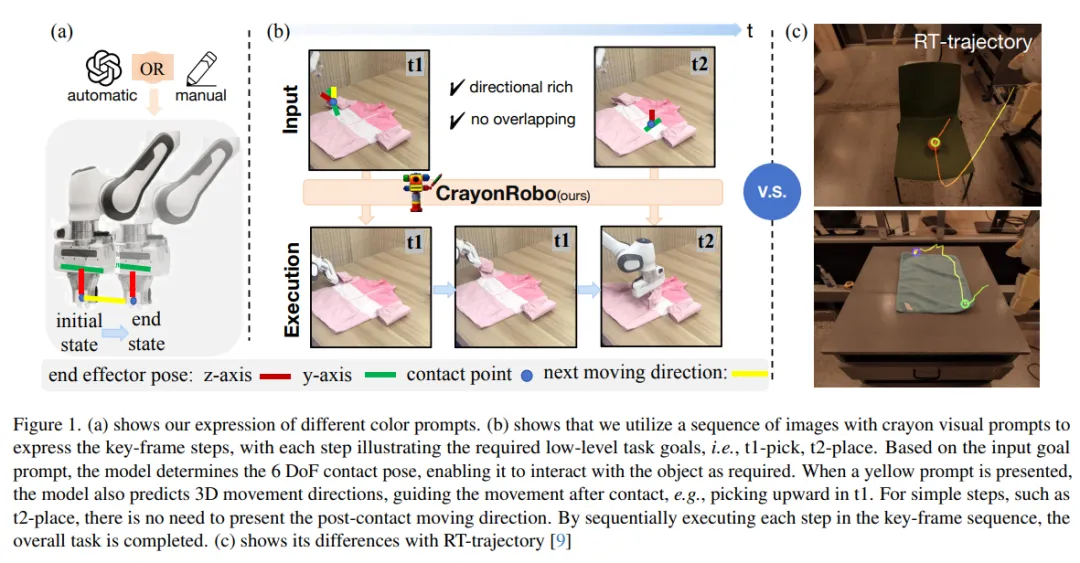
在机器人操作中,任务目标可以通过多种模态传达,例如自然语言、目标图像或目标视频。然而,自然语言往往存在歧义,而图像或视频则可能提供过于细节化的指令。为应对这些挑战,我们提出了 CrayonRobo ——一种以对象为中心、提示驱动的视觉-语言-动作模型,能够以简洁的方式明确表达低层级动作与高层级任务规划。
具体而言,对于任务序列中的每一个关键帧,我们的方法支持在 RGB 图像上手动或自动生成简单而富有表现力的二维视觉提示。这些提示代表了具体的任务目标,例如末端执行器的姿态以及接触后的期望移动方向。
我们还设计了一种训练策略,使模型能够理解这些视觉-语言提示,并在 SE(3) 空间中预测相应的接触姿态与移动方向。通过顺序执行所有关键帧步骤,模型能够完成长时间跨度的任务序列。该方法不仅使模型能够更清晰地理解任务目标,还通过提供可解释的提示显著提升了其在未知任务场景中的鲁棒性。
我们在模拟环境与现实机器人平台中对该方法进行了评估,结果表明其具备强大的操控能力与良好的泛化性能。